引子
前文寶華的《宋寶華:關於ARM Linux原子操作的實現》談到軟體如何使用ARM V7之後的LDREX和STREX指令來實現spin lock和atomic 函式,這篇文章接著探討ARM架構和匯流排協議如何來支援的。對於某款ARM處理器和匯流排CCI,CCN和CMN產品的具體實現,屬於實現層面的微架構,一般需要NDA,這裡不予討論。
順便提一下,在ARMv8 架構下對應的是LDXR (load exclusive register 和STXR (store exclusiveregister)及其變種指令,另外,在ARMv8.1架構中引入atomic instruction, 例如LDADD (Atomic add),CAS(Compare and Swap)等。
Exclusive monitor
首先,作為一個愛問為什麼的工程師,一定會想到LDXR/ STXR和一般的LDR/STR有什麼區別。這個區別就在於LDXR除了向memory發起load請求外,還會記錄該memory所在地址的狀態(一般ARM處理器在同一個cache line大小,也就是64 byte的地址範圍內共用一個狀態),那就是Open和Exclusive。
我們可以認為一個叫做exclusive monitor的模組來記錄。根據CPU訪問記憶體地址的屬性(在頁表裡面定義),這個元件可能在處理器 L1 memory system, 處理器cluster level, 或者匯流排,DDR controller上。
下麵是Arm ARM架構 [1] 檔案定義的狀態轉換圖
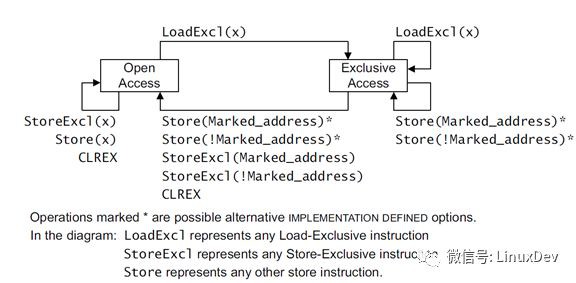
實體說明:
1)CPU1發起了一個LDXR的讀操作,記錄當前的狀態為Exclusive
2)CPU2發起了一個LDXR的讀操作,當前的狀態為Exclusive,保持不變
3)CPU2發起了一個STXR的寫操作,狀態從Exclusive變成Open,同時資料回寫到DDR
4)CPU1發起了一個STXR的寫操作,因為當前的exclusive monitor狀態為Open,寫失敗(假如程式這時用STR操作來寫,寫會成功,但是這個不是原子操作函式的本意,屬於程式設計錯誤)
假如有多個CPU,同時對一個處於Exclusive的memory region來進行寫,CPU有內部邏輯來保證序列化。
Monitor的狀態除了STXR會清掉,從Exclusive變成Open之外,還有其他因素也可以導致monitor的狀態被清掉,所以軟體在實現spinlock的時候,一般會用一個loop迴圈來實現,所謂“spin”。
Exclusive monitor實現所處的位置
根據LDXR/STXR 訪問的memory的屬性,需要的monitor可以在CPU內部,匯流排,也可以DDR controller(例如ARM DMC-400 [2]在每個memory interface 支援8個exclusive access monitors)。
一般Memory屬性配置為 normal cacheable, shareable,這種情形下,CPU發起的exclusive access會終結在CPU cluster內部,對外的表現,比如cacheline fill和line eviction和正常的讀寫操作產生的外部行為是一樣的。具體實現上,需要結合local monitor的狀態管理和cache coherency 的處理邏輯,比如MESI/MOESI的cacheline的狀態管理來。
為方便大家理解,下麵劃出一個monitor在一個假象SOC裡面的邏輯圖(在一個真實晶片裡面,不是所有monitor都會實現,需要和SOC vendor確認)

External exclusive monitor
對於normal non-cacheable,或者Device型別的memory屬性的memory地址,cpu會發出exclusive access的AXI 訪問(AxLOCK signals )到匯流排上去,匯流排需要有對應的External exclusive monitor支援,否則會傳回錯誤。例如, 假如某個SOC不支援外部global exclusivemonitor,軟體把MMU disabled的情況下,啟動SMP Linux,系統是沒法啟動起來的,在spinlock處會掛掉。
AMBA AXI/ACE 規範
The exclusive access mechanism can provide semaphore-type operations without requiring the bus to remain dedicated to a particular master for the duration of the operation. This means the semaphore-type operations do not impact either the bus access latency or the maximum achievable bandwidth.
The AxLOCK signals select exclusive access, and the RRESP and BRESP signals indicate the success or failure of the exclusive access read or write respectively.
The slave requires additional logic to support exclusive access. The AXI protocol provides a mechanism to indicate when a master attempts an exclusive access to a slave that does not support it.
Atomic指令的支援
處理器,支援cache coherency協議的匯流排,或者DDR controller可以增加了一些簡單的運算,比如,在讀寫指令產生的memory訪問的過程中一併把簡單的運算給做了。
AMBA 5 [3] 裡面增加了對Atomic transactions的支援:
AMBA 5 introduces Atomic transactions, which perform more than just a single access, and have some form of operation that is associated with the transaction.
Atomic transactions are suited to situations where the data is located a significant distance from the agent that must perform the operation. Previously, performing an operation that is atomically required pulling the data towards the agent, performing the operation, and then pushing the result back.
Atomic transactions enable sending the operation to the data, permitting the operation to be performed closer to where the data is located.
The key advantage of this approach is that it reduces the amount of time during which the data must be made inaccessible to other agents in the system.
支援4種Atomic transaction:AtomicStore ,AtomicLoad,AtomicSwap 和AtomicCompare
QA
1) Local monitor和Global monitor的使用場景
* Local monitor適用於訪問的memory屬為normal cacheable, shareable或者non-shareable的情況.
* Global monitor ,準確來說,external global exclusive monitor (處理器之外,在外部匯流排上)用於normal noncacheable或者device memory型別。比如可以用於一個Cortex-A處理器和一個Cortex-M 處理器(沒有內部cache)之間的同步。
2)多CPU下,多個LDREX,和STREX的排他性實現
* 各個處理器和匯流排的實現不同,可以從軟體上理解為和data coherency實現相結合,比如M(O)ESI協議[5],這是一種 Invalidate-based cache coherence protocol, 其中的key point就是當多個CPU在讀同一個cacheline的時候,在每個CPU的內部cache裡面都有cacheline allocation,cacheline的狀態會變成Shared;但是當某個CPU做寫的時候,會把其它CPU裡面的cacheline資料給invalidate掉,然後寫自己的cacheline資料,同時設定為Modified狀態,從而保證了資料的一致性。
* LDREX,本質上是一個LDR,CPU1做cache linefill,然後設定該line為E狀態(Exclusive),額外的一個作用是設定exclusive monitor的狀態為Exclusive;其他cpu做LDREX,該line也會分配到它的內部cache裡面,狀態都設定為Shared ,也會設定本CPU的monitor的狀態。當一個CPU 做STREX時候,這個Write操作會把其它CPU裡面的cacheline資料給invalidate掉。同時也把monitor的狀態清掉,從Exclusive變成Open的狀態,這個MESI協議導致cachline的狀態在多CPU的變化,是執行Write操作一次性改變的。這樣在保證資料一致性的同時,也保證了montitor的狀態更新同步改變。
3)比如舉一個多核的場景,一個核ldrex了,如果本核的local monitor會發生什麼,外部的global monitor發生什麼,開不開mmu,cache不cache,區別和影響是什麼。
Ldrex/strex本來就是針對多核的場景來設計的,local monitor的狀態發生改變,不會影響外部的global monitor狀態。但是external global monitor的狀態發生改變,可以告訴處理器,把local monitor的狀態清掉。
Data coherency是透過硬體來支援的。對於normal cacheable型別的memory, MMU和DCache必須使能,否則CPU會把exclusive型別的資料請求發出處理器,這時需要外部monitor的支援。
參考文獻
[1] ARM Architecture Reference Manual ARMv8,
https://developer.arm.com/docs/ddi0487/latest/arm-architecture-reference-manual-armv8-for-armv8-a-architecture-profile
[2] DMC400 TRM
https://developer.arm.com/products/system-design/fast-models/docs/dui1087/latest/corelink-dmc-400-dynamic-memory-controller-user-guide
[3] AMBA specification ( 需要註冊使用者名稱,一般個人郵件地址都可以),
https://developer.arm.com/products/architecture/system-architectures/amba
[4] Arm training courses
https://developer.arm.com/support/training
其他架構的實現探討
X86_64
看檔案和程式碼感覺類似ARM的atomic instruction, 比如 CMPXCHG(Compare andexchange)
arch/x86/include/asm/spinlock.h
Onx86, we implement read-write locks using the generic qrwlock with x86 specific optimization.
include/asm-generic/qspinlock.h

RISCV (Volume II: RISC-V Privileged ArchitecturesV1.10)
對RISCV瞭解不多,和ARM相比,同為RISC架構,對原子指令的支援也比較類似
Support for atomicinstructions is divided into two categories:
1) Load-Reserved/Store-Conditional (LR/SC)instructions have been added in the atomic instruction extension.
2) Within AMOs, there are four levels of support: AMONone, AMOSwap, AMOLogical, and AMOArithmetic.
AMONone indicates that no AMO operations are supported.
AMOSwap indicates that only amoswap instructions are supportedin this address range. AMOLogical indicates that swap instructions plus all thelogical AMOs (amoand, amoor, amoxor) are supported.
AMOArithmetic indicates that all RISC-V AMOs are supported.
arch/riscv/include/asm/spinlock.h