作者:Max Pechyonkin;翻譯:和中華;校對:丁楠雅
本文約2900字,建議閱讀10分鐘。
本文將介紹3個非視覺領域的應用實體。
導讀
眾所周知,目前深度學習在計算機視覺領域已經有很好的應用落地,再加上遷移學習,可以很容易的訓練出一個用於視覺任務的模型。但是現實中還有很多工的原始資料是非視覺型別的,面對這樣的問題,我們還可以借用強大的深度學習視覺模型嗎,本文作者將用3個具體案例來展示這一切都是可能的。
介紹
近年來,深度學習已經徹底改變了計算機視覺。由於有遷移學習和優秀的學習資源,任何人都可以在數天甚至數小時內,利用預先訓練好的模型並將其應用於自己的領域從而獲得最先進的結果。隨著深度學習變得商品化,人們的需求也隨之變成了它在不同領域的創造性應用。
遷移學習教程:
https://machinelearningmastery.com/transfer-learning-for-deep-learning/
深度學習教程:
https://course.fast.ai/
今天,計算機視覺領域的深度學習已經在很大程度上解決了視覺物件分類、標的檢測和識別問題。在這些領域,深度神經網路的表現優於人類。
即使資料不是視覺化的,你仍然可以利用深度學習視覺模型,主要是指CNN。要做到這一點,你必須將資料從非視覺型轉換為影象,然後使用某個針對影象預訓練過的模型來處理你的資料。你將會對這種方法的強大感到驚訝!
在本文中,我將介紹3個創造性地使用深度學習的案例,展示一些公司如何將深度學習視覺模型應用於非視覺領域。在每個案例中,都會對一個非計算機視覺問題進行轉換和說明,以便利用適於影象分類的深度學習模型。
案例一:石油工業
在石油工業中,“磕頭機”常用於從地下開採石油和天然氣。它們由一個連線在遊樑上的發動機提供動力。遊梁將發動機的旋轉運動轉化為抽油桿的垂直往複運動,使得抽油桿像泵一樣將油輸送到錶面。

磕頭機,也稱為抽油機。來源:https://commons.wikimedia.org
像任何複雜的機械繫統一樣,抽油機也容易發生故障。為了幫助診斷,人們在抽油機上安裝一個測功計,用於測量桿上的負載。測量後,繪製出一張測功計泵卡,其顯示發動機旋轉週期各部分的負載。

測功計泵卡樣例。來源:https://www.researchgate.net/
當抽油機出故障時,測功計泵卡的形狀會改變。通常會邀請專業技術人員來檢查卡,並就泵的哪個部位出現故障以及需要採取什麼措施來修複它作出判斷。這個過程非常耗時,並且需要非常狹窄的專業知識才能有效解決。
另一方面,這個過程看起來像是可以自動化的,這就是之前為什麼傳統的機器學習系統被試過,只是沒有取得好的效果,準確率僅為60%左右。
將深度學習應用到這個領域的公司之一是貝克休斯(Baker Hughes)。在他們的案例中,測功計泵卡被轉換成影象,然後作為輸入傳給ImageNet預訓練好的模型中。結果令人印象深刻——只需採用預訓練好的模型並用新資料對其進行微調,準確率就從60%上升到了93%。對模型進一步最佳化,其準確率可達97%。
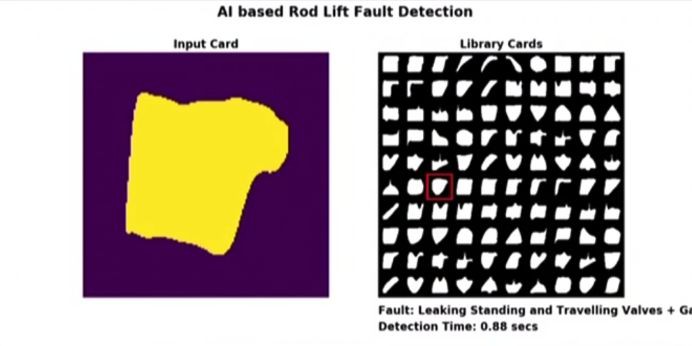
貝克休斯部署的系統示例。左側是輸入影象,右側是故障樣式的實時分類。系統在行動式裝置上執行,其分類時間顯示在右下角。來源:https://www.youtube.com
它不僅擊敗了以前基於傳統機器學習的方法,而且現在該公司不需要抽油機技術人員花時間來診斷問題,從而可以提高效率。他們可以立即開始修複機械故障。
要瞭解更多資訊,你還可以閱讀一篇討論類似方法的論文。
案例二:線上欺詐檢測
計算機使用者在使用計算機時有獨特的樣式和習慣。當你瀏覽一個網站時你使用滑鼠的方式或者編寫郵件時你在鍵盤上敲擊的方式都是獨一無二的。
在這個案例中,Splunk解決了一個問題,即透過使用計算機滑鼠的方式對使用者進行分類。如果你的系統能夠根據滑鼠使用樣式唯一地識別使用者,那它就可以用於欺詐檢測。想象一下:欺詐者竊取某人的登入名和密碼,然後登入併在網上商店購物。欺詐者使用電腦滑鼠的方式是獨一無二的,系統將很容易檢測到這種異常情況,並防止欺詐交易發生,同時也會通知賬戶的真正所有者。
使用一段特殊的javascript程式碼,就可以收集所有的滑鼠活動。該軟體每5-10毫秒記錄一次滑鼠活動。因此,每個使用者每頁面大約會產生5000–10000個資料點。該資料有兩大挑戰:首先,這對每個使用者來說都是大量的資料;第二,每個使用者的資料集將包含不同數量的資料點,這不是很方便,因為通常而言,不同長度的序列需要用到更精巧的深度學習架構。
他們的解決辦法是將每個使用者在每個網頁上的滑鼠活動轉換為單個影象。在每幅影象中,滑鼠移動由一條線表示,顏色編碼了滑鼠移動的速度,而左擊和右擊則由綠色和紅色圓圈表示。這種處理初始資料的方法解決了上述兩個問題:首先,所有影象的大小都相同;其次,可以使用處理影象的深度學習模型了。

在每幅影象中,滑鼠移動由一條顏色編碼滑鼠速度的線表示,而左擊和右擊則由綠色和紅色圓圈表示。來源:https://www.splunk.com
Splunk使用TensorFlow加Keras構建了一個分類使用者的深度學習系統。他們做了兩個實驗:
實驗一:某個金融服務網站使用者的組別分類——訪問類似頁面時,區分他們是普通客戶還是非客戶。
僅用了一個由2000張圖片組成的較小的訓練集,在對基於VGG16修改的網路結構進行了2分鐘的訓練後,系統就能以80%以上的準確率識別這兩個類別。
實驗二:單個使用者分類。
該任務是對於給定的使用者,透過滑鼠活動預測它是此使用者的還是模仿者的。這回僅有一個360張圖片的小訓練集。基於VGG16,但考慮到資料集更小和過擬合(可能使用了dropout和batch normalization),他們對網路結構進行了修改。經過3分鐘的訓練,準確率就達到了78%左右,考慮到該任務的挑戰性,這個結果令人印象非常深刻。
想瞭解更多資訊,請參閱下麵這篇描述系統和實驗的完整文章。
文章連結:
https://www.splunk.com/blog/2017/04/18/deep-learning-with-splunk-and-tensorflow-for-security-catching-the-fraudster-in-neural-networks-with-behavioral-biometrics.html
案例三:鯨魚的聲音檢測
在這個例子中,谷歌使用摺積神經網路來分析錄音並檢測其中的座頭鯨。這對研究而言很有用,例如跟蹤單個鯨魚的運動、歌曲的特性、鯨魚的數量等。有趣的不是研究目的,而是谷歌如何處理資料以用於需要影象的摺積神經網路。
將音訊資料轉換成影象的方法是使用時頻譜。時頻譜是音訊資料基於頻率特徵的視覺表示。

一個男性聲音說“十九世紀”的時頻譜例子。來源:https://commons.wikimedia.org
在將音訊資料轉換成時頻譜之後,谷歌的研究人員使用了Resnet-50架構來訓練這個模型。達到的效能如下:
-
精度90%:90%被模型歸類為鯨魚歌聲的音訊剪輯被正確歸類
-
召回率90%:如果有一首鯨魚歌聲的錄音,有90%的機率它會被貼上這樣的標簽。
這一結果令人印象深刻,對鯨魚的研究也一定有幫助。
讓我們把焦點從鯨魚轉到處理音訊資料上。建立時頻譜時,根據音訊資料的型別,你可以選擇要使用的頻率。針對人類語音、座頭鯨歌聲或工業裝置錄音等將需要不同的頻率,因為在這些不同場景下,最重要的資訊包含在不同的頻段中。必須使用領域知識來選擇該引數。例如,如果你使用的是人類語音資料,那麼第一選擇應該是梅爾倒頻譜。
目前有很好的軟體包可用於音訊。librosa是一個免費的音訊分析python庫,可以使用CPU生成時頻譜。如果你在TensorFlow上開發並且想在GPU上做時頻譜計算,也是可以的。
librosa相關連結:
https://librosa.github.io/librosa/
請參考下麵這篇谷歌人工智慧的原始部落格文章,以瞭解更多關於谷歌如何處理座頭鯨資料的資訊。
谷歌部落格文章:
https://ai.googleblog.com/2018/10/acoustic-detection-of-humpback-whales.html
總而言之,本文概述的一般方法遵循兩個步驟。
-
首先,找到一種將資料轉換成影象的方法;
-
第二,使用經過預訓練的摺積網路或從頭訓練一個。
第一步要比第二步更難,需要思考你的資料是否可以轉換成影象,這是你展現創造性的地方。我希望上述提供的示例對解決你的問題有幫助。如果你還有其他的例子或問題,請寫在下麵的評論中。
參考取用
IoT for Oil & Gas — The Power of Big Data and ML (Cloud Next ’18)
https://www.youtube.com/watch?v=6_kdEguYwwg&feature;=youtu.be&t;=1692
Beam Pump Dynamometer Card Prediction Using Artificial Neural Networks
https://www.knepublishing.com/index.php/KnE-Engineering/article/download/3083/6587
Splunk and Tensorflow for Security: Catching the Fraudster with Behavior Biometrics
https://www.splunk.com/blog/2017/04/18/deep-learning-with-splunk-and-tensorflow-for-security-catching-the-fraudster-in-neural-networks-with-behavioral-biometrics.html
Acoustic Detection of Humpback Whales Using a Convolutional Neural Network
https://ai.googleblog.com/2018/10/acoustic-detection-of-humpback-whales.html
本文最初發表在作者網站pechyonkin.me上。
作者聯絡方式
Twitter:
https://twitter.com/max_pechyonkin
LinkdIn:
https://www.linkedin.com/authwall?trk=gf&trkInfo;=AQFpHL3mlkPKnQAAAWiThnDAgtn1tdrvz57ag0PVaE7smdQF3iJOA2Eapss4-q9395VIOxi_DSeBALr0q2KXAxHqmEkhqzFKFdkMWgCcWSkILT7gOlMbd9XT5Jqctr4d-DFLHGk=&originalReferer;=&sessionRedirect;=https%3A%2F%2Fwww.linkedin.c
原文標題:
Deep Learning Vision for Non-Vision Tasks
原文連結:
https://towardsdatascience.com/deep-learning-vision-non-vision-tasks-a809df74d6f
編輯:黃繼彥
譯者簡介:和中華,留德軟體工程碩士。由於對機器學習感興趣,碩士論文選擇了利用遺傳演演算法思想改進傳統kmeans。目前在杭州進行大資料相關實踐。加入資料派THU希望為IT同行們盡自己一份綿薄之力,也希望結交許多志趣相投的小夥伴。
「完」
轉自:資料派THU ;
版權宣告:本號內容部分來自網際網路,轉載請註明原文連結和作者,如有侵權或出處有誤請和我們聯絡。
關聯閱讀
原創系列文章:
資料運營 關聯文章閱讀:
資料分析、資料產品 關聯文章閱讀:
80%的運營註定了打雜?因為你沒有搭建出一套有效的使用者運營體系
合作請加qq:365242293
更多相關知識請回覆:“ 月光寶盒 ”;
資料分析(ID : ecshujufenxi )網際網路科技與資料圈自己的微信,也是WeMedia自媒體聯盟成員之一,WeMedia聯盟改寫5000萬人群。

