來源:戀習Python(ID:sldata2017)
深陷抄襲之名、訴訟糾紛的《愛情公寓》終於上映了。

情懷粉們的力量不容小覷,截止到8月12,《愛情公寓》票房已經突破3.72億大關,穩坐票房冠軍的寶座,院線排片佔比高達40.0%。

和超高票房背道而馳的,是各大社交平臺上一邊倒的差評。豆瓣萬人打分,九成觀眾果斷打了一星,只無奈豆瓣沒有零星選項。

不知道有多少像我這樣的情懷粉絲們,滿懷期待地買了電影票,走進電影院,卻發現是交了智商稅。
豆瓣短評區裡,觀眾們的狀態已經出離憤怒,近乎暴走的狀態。有人揭露電影掛羊頭賣狗肉,電影內容和《愛情公寓》故事主線毫無關係。是山寨電影、詐騙電影、電影中的拼多多。


為了燃解我心頭之恨,戀習Python將會跟你一起用貓眼上萬條評論資料來分析,網友對這部電影的反響是否爛到掃清國產片不要臉的下限?
還是老規矩,整體思路將會從資料獲取、資料清洗、資料視覺化三部曲來進行:
1.資料獲取清洗
整體思路與之前獲取《邪不壓正》評論一樣,詳情見《邪不壓正》評分持續走低,上萬條網友評論揭秘,是救救薑文還是救救觀眾?
具體程式碼如下:
import requests
import time
import random
import json
#獲取每一頁資料
def get_one_page(url):
response = requests.get(url=url)
if response.status_code == 200:
return response.text
return None
#解析每一頁資料
def parse_one_page(html):
data = json.loads(html)['cmts']#獲取評論內容
for item in data:
yield{
'date':item['time'].split(' ')[0],
'nickname':item['nickName'],
'city':item['cityName'],
'rate':item['score'],
'conment':item['content']
}
#儲存到文字檔案中
def save_to_txt():
for i in range(1,1001):
print("開始儲存第%d頁" % i)
url = 'http://m.maoyan.com/mmdb/comments/movie/1175253.json?_v_=yes&offset;=' + str(i)
html = get_one_page(url)
for item in parse_one_page(html):
with open('愛情公寓.txt','a',encoding='utf-8') as f:
f.write(item['date'] + ','+item['nickname'] +','+item['city'] +','
+str(item['rate']) +',' +item['conment']+'
')
#time.sleep(random.randint(1,100)/20)
time.sleep(2)
#去重重覆的評論內容
def delete_repeat(old,new):
oldfile = open(old,'r',encoding='utf-8')
newfile = open(new,'w',encoding='utf-8')
content_list = oldfile.readlines() #獲取所有評論資料集
content_alread = [] #儲存去重後的評論資料集
for line in content_list:
if line not in content_alread:
newfile.write(line+'
')
content_alread.append(line)
if __name__ == '__main__':
save_to_txt()
delete_repeat(r'愛情公寓_old.txt',r'愛情公寓_new.txt')2.資料分析視覺化
我們將用Python的兩個模組Pandas與pyecharts:
pyecharts 是一個用於生成 Echarts 圖表的類庫。Echarts 是百度開源的一個資料視覺化 JS 庫。用 Echarts 生成的圖視覺化效果非常棒,pyecharts 是為了與 Python 進行對接,方便在 Python 中直接使用資料生成圖。(詳情請看:
http://pyecharts.org/)
Pandas 是基於 NumPy 的一個非常好用的庫,正如名字一樣,人見人愛。之所以如此,就在於不論是讀取、處理資料,用它都非常簡單。Pandas 有兩種自己獨有的基本資料結構。要使用pandas,首先就得熟悉它的兩個主要資料結構:Series和DataFrame。其中Series的性質和Python中原生的dict差不多,一個key對應一個vaule,而且key必須是唯一的;DataFrame(以下簡稱df)的性質則和SQL中的table差不多(詳情請看:
http://pandas.pydata.org/)。
真可謂電影界的”拼多多“
我們把城市打分情況投射到地圖中,可以看出:

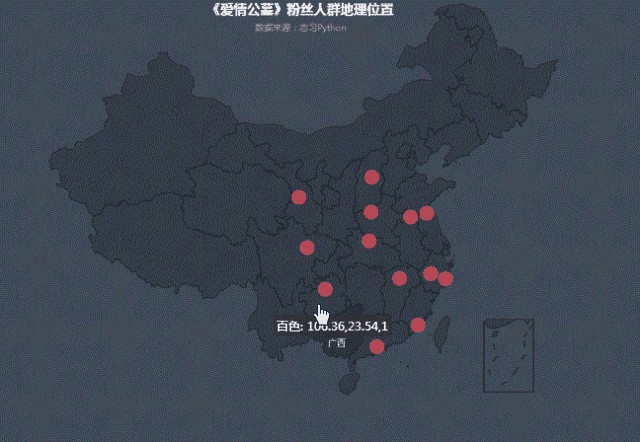
在熱力圖中,白銀、綿陽、遵義等三四線城市熱度相對高點,也可看出隨著人們消費水平的升級,去電影院看電影是娛樂首選。在滿足普通人民精神娛樂需求方面,但也不能掛羊頭賣狗肉,電影內容和《愛情公寓》故事主線毫無關係。這難道不是電影界的拼多多麼?
評分清一色,均為3星級
圖為主要城市的評論數量與打分情況:
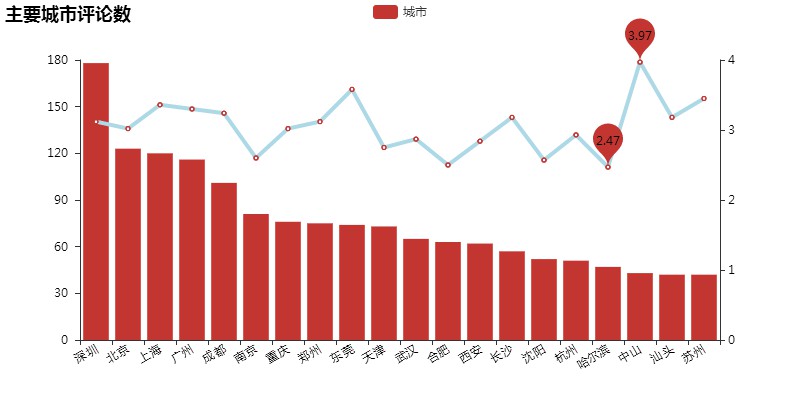
由圖中可看出,各大城市觀眾打分均為3星級左右,這與貓眼評分6.6基本吻合;打出最高分與最低分分別是哈爾濱與中山。同時也能看出,一二線城市觀眾對此很失望。
有些人的良心被狗吃了?
看過了評分,我們看一下評論生成的詞雲圖:

由詞雲圖可以看出,愛情公寓、盜墓電影二詞顯目在列,整部電影就30秒和《愛情公寓》有關,所謂的集齊原班人馬回歸也只是個幌子,《愛情公寓》大電影完全是一部盜墓筆記,真正毀了《愛情公寓》這個ip,也毀了《盜墓筆記》這個ip。
但即便是在這樣觀眾一致認為徹底失望的情況之下,依然有一波忠實的『粉絲們』堅守陣地。他們的手中依然緊握著情懷牌,打分也是一水的五星。

對於這些水軍以及說《愛情公寓》好看的人,大家可以絕交了;作為觀眾,任何的關註都是助長《愛情公寓》的囂張氣焰,我們也有責任自發抵制爛片,決不讓詐騙電影多賺一分錢。
以上資訊具體程式碼為:
from wordcloud import WordCloud,STOPWORDS
import pandas as pd
import jieba
import matplotlib.pyplot as plt
#import seaborn as sns
from pyecharts import Geo,Style,Line,Bar,Overlap
f = open('愛情公寓_new.txt',encoding='utf-8')
data = pd.read_csv(f,sep=',',essay-header=None,encoding='utf-8',names=['date','nickname','city','rate','comment'])
city = data.groupby(['city'])
rate_group = city['rate']
city_com = city['rate'].agg(['mean','count'])
#print(city_com)
city_com.reset_index(inplace=True)
city_com['mean'] = round(city_com['mean'],2)
#熱力圖分析
data_map = [(city_com['city'][i],city_com['count'][i]) for i in range(0,city_com.shape[0])]
#print(data_map)
style = Style(title_color="#fff",title_pos = "center",
width = 1200,height = 600,background_color = "#404a59")
geo = Geo("《愛情公墓》粉絲人群地理位置","資料來源:戀習Python",**style.init_style)
while True:
try:
attr,val = geo.cast(data_map)
geo.add("",attr,val,visual_range=[0,20],
visual_text_color="#fff",symbol_size=20,
is_visualmap=True,is_piecewise=True,
visual_split_number=4)
except ValueError as e:
e = str(e)
e = e.split("No coordinate is specified for ")[1]#獲取不支援的城市名
for i in range(0,len(data_map)):
if e in data_map[i]:
data_map.pop[i]
break
else:
break
geo.render('愛情公墓.html')
#折線+柱圖分析
city_main = city_com.sort_values('count',ascending=False)[0:20]
#print(city_main)
attr = city_main['city']
v1 = city_main['count']
v2 = city_main['mean']
#print(attr,v1,v2)
line = Line("主要城市評分")
line.add("城市",attr,v2,is_stack=True,xaxis_rotate=30,yaxix_min=4.2,
mark_point=['min','max'],xaxis_interval=0,line_color='lightblue',
line_width=4,mark_point_textcolor='black',mark_point_color='lightblue',
is_splitline_show=False)
bar = Bar("主要城市評論數")
bar.add("城市",attr,v1,is_stack=True,xaxis_rotate=30,yaxix_min=4.2,
xaxis_interval=0,is_splitline_show=False)
overlap = Overlap()
overlap.add(bar)
overlap.add(line,yaxis_index=1,is_add_yaxis=True)
overlap.render('主要城市評論數_平均分.html')
#詞雲分析
#分詞
comment = jieba.cut(str(data['comment']),cut_all=False)
wl_space_split = " ".join(comment)
#匯入背景圖
backgroud_Image = plt.imread('lan.jpg')
stopwords = STOPWORDS.copy()
#print("STOPWORDS.copy()",help(STOPWORDS.copy()))
wc = WordCloud(width=1024,height=768,background_color='white',
mask=backgroud_Image,font_path="C:simhei.ttf",
stopwords=stopwords,max_font_size=400,
random_state=50)
wc.generate_from_text(wl_space_split)
plt.imshow(wc)
plt.axis('off')#不顯示坐標軸
plt.show()
wc.to_file(r'laji.jpg')最後,作為《愛情公寓》之前的鐵粉,只想評價一個字:爛。
爛在哪裡?並不是爛在盜墓劇情,也不爛在演員特效。爛在它消費粉絲熱情和愛戴,玩弄觀眾。
2.4分我想更多是對韋正和汪遠的評價。為了賺錢,上映前吹噓誇大,不設點映;為了賺錢,宣傳片預告片MV大量回憶殺,關谷展博無限出鏡;為了賺錢,藏著掖著不見光不露臉,以9.9分的保票“催”著粉絲買預售票。上映第一天3億。賺的盆滿缽滿。
反過來看觀眾,哭著臉走出影院的,多數是被結尾彩蛋感動,彩蛋才真正傳達了“愛情公寓精神”。主演們對著鏡頭的自白,說出了我們最想聽到的幾段話,才真正喚起了我們腦海裡對愛情公寓的美好回憶。
電影結尾的彩蛋,小姨媽呼喚關谷的那一段,算是愛情公寓最感人的地方了吧。

但是,一個彩蛋真的配3億票房嗎?
用近乎做作的猶抱琵琶半遮面的營銷手段,讓大家對它憧憬,希望它能給我們的記憶畫上一個圓滿的句號,可卻用一部近乎玩笑的垃圾影片嘲笑我們對它的喜愛。
打著情懷的旗號,將一個個劇版粉絲騙進電影院,將電影票錢裝進自己的腰包。
這就是它最爛的地方。
●編號483,輸入編號直達本文
●輸入m獲取文章目錄

演演算法與資料結構
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
