
(本文由深度學習與NLP編譯)
DeepMind在強化學習領域具有非常重要的作用,其創造了舉世震驚的AI智慧AlphaGo,以及後來的AlphaGo Zero。這是第一個在19 x 19棋盤上打敗人類職業圍棋手的計算機程式。還擊敗了圍棋世界冠軍李世石、柯潔(當時世界排名第一的玩家)和許多其他排名靠前的玩家。圍棋比賽是一個複雜且困難的比賽,因為它在每一步都具有非常大的分支因素,這使得經典的搜尋技術如alpha-beta剪枝和啟髮式搜尋都變得無用。本文原作者dylandjian對AlphaGo的工作進行了復現,在次,下文將盡可能詳細地介紹複製的具體工作。閱讀本文需要一些機器學習和Python方面的背景知識,也需要一點關於圍棋的知識。
(文末付實戰完整程式碼下載地址)
簡介
本文參考了文章《This Amazing Info Graphic by David Foster》,按照Deep mind發表的論文《Mastering the game of Go without human knowledge》來構建篇文章的結構。
AlphaGo簡介
整個AlphaGo Zero pipeline被分成三個主要部分,每個部分都有各自獨立的程式碼。第一個組成部分負責Self-Play,負責生產訓練資料。第二個組成部分是Training,透過self-play部分新生成的資料用於改進當前的最佳網路。最後一部分是Evaluation,它決定訓練好的Agent是否優於當之前的Agent。最後一部分至關重要,因為生成的資料應該總是來自最好的可用網路,因為只有更好的Agent可以生產更優質的資料,用於去訓練更好的Agent。
為了更好地理解這些部分是如何相互作用的,我將分別描述各個模組的構建,然後將它們組成一起,形成一個全域性的系統。
The Environment
理想情況下,一個好的環境應該是一個可以玩得很快並且融合了圍棋的所有規則( Atari、ko、Komi等)。經過一些研究,我偶然發現了OpenAI Gym提供一個由Pachi_py編寫的現成的環境(一個舊版本的Board Environment),Pachi_py是一個與c++ Pachi GoEngine系結的Python語言。經過以下幾步調整後,現實可用的環境就可以使用了。
第一個調整是Agent的輸入是board的一個special representation,如下圖所示。該狀態由黑子的當前位置作為二進製圖( 1表示黑子,0表示其他)以及過去的7個board state組成。白子也做同樣的處理並於黑子狀態特徵圖concatenate一起作為Agent的輸入。這主要是在ko的情況下完成的。
最後,新增一個滿是0或1的map來表示哪個玩家將要走下一步。為了易於實現,所以採用這種方式表示,但它也可以用一個位元位來編碼。

第二個調整是確保有可能與Engine一起玩,無論只有一個Agent在玩(self-play、online)還是兩個player(evaluation或played with another agent)。此外,為了充分利用CPU的資源,必須修改程式碼,以便並行執行Engine的多個實體。
除了這些調整之外,程式碼還必須進行調整,以便能夠使用Tromp – Taylor評分來準確估計比賽中的獲勝者,以防比賽提前結束(這將在下麵的訓練部分中詳細解釋)。
。。。
The Agent
該Agent由三個協同工作的神經網路組成:特徵提取器(Feature extractor)、策略網路(Policy Network)和價值網路(Value network)。這也是為什麼AlphaGo Zero有時被稱為“Two Headed Beast”:一個身體,它是特徵提取器,兩個腦袋:policy和value。特徵提取器模型建立自己的board state表示。策略網路輸出所有可能move的機率分佈,價值模型(value model)模型預測一個[- 1,1]範圍內的標量值,用於表示在一個給定的board state狀態下,走那一步更容易獲勝。策略和價值模型都使用特徵提取器的輸出作為輸入。讓我們看看它們實際上是如何工作的。
特徵提取器
特徵提取器模型由一個殘差神經網路(Residual Neural Network)構成,一種特殊的摺積神經網路( CNN )。它的特殊性在於它在層與層之間採用skip connection。這種型別的連線在進行ReLU啟用之前使用,將block的最後一個連線的輸出與輸入相加,如下圖所示。

下麵是是在程式碼中的定義:

定義好Residual Block之後,參考原始文章,將其加入到最終特徵提取器模型中。

最終的網路僅僅是result或convolution layer,該層的輸出被作為其他層的輸入。
Policy Head
策略網路模型是一個簡單的摺積網路(在特徵提取器輸出的channel上進行1×1摺積編碼)、一個批處理歸一化(batch normalization)層和一個全連線的層構成,該層的輸出board上的機率分佈,以及一個額外的pass move。


Value Head
價值網路模型更加複雜。它包含一個couple convolution、batch normalization、ReLU和一個全連線層,在此基礎上增加了另一個完全連線的層構成。最後,應用雙曲正切函式來輸出一個[ – 1,1 ]的值,表示在當前遊戲狀態下玩家獲勝的可能性。


蒙特卡羅樹搜尋
AlphaGo Zero的另一個主要組成部分是非同步蒙特卡羅樹搜尋( MCTS )。這種樹搜尋演演算法是有用的,因為它使網路能夠提前思考,並透過它所做的模擬選擇最佳的move,而無需在每一步都探索所有節點。由於Go是一款完美的Information Game,有了完美的模擬器,就有可能模擬環境的狀態,並像人類一樣提前思考計劃對手可能的反應。讓我們看看這些步驟是如何做到的。
Node
樹中的每個節點代表一個board state,並儲存不同的統計資料:節點被訪問的次數( n )、總的action value( w )、到達該節點的先驗機率( p )、平均動作值( q,即q = w / n )以及從父節點到達該節點的move、指向父節點的指標,最後是從該節點開始的所有合法move,這些move擁有具有非零機率的子孩子(children)。

Rollout
PUCT選擇演演算法
樹搜尋中的第一個action是選擇最大化多項式上限樹( Polynomial Upper Confidence Trees,PUCT )公式variant的action。藉助探索常數(exploration constant)C_puct,網路可以在早期探索看不見的路徑,或者在以後進一步搜尋可能的最佳move。
選擇公式定義如下。
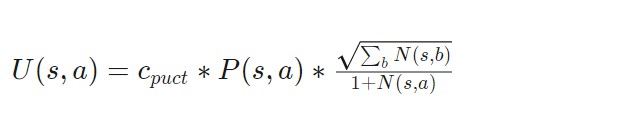
其中,P ( s,a )表示處於該狀態的機率,N ( s,a )表示在模擬過程中訪問該特定狀態的次數。
下麵表述在程式碼中如何定義和實現。這個版本的可讀性稍差,因為它是使用numba最佳化的。

ENDING
Selection過程一直持續到達到一個葉子節點為止。葉子節點表示尚未擴充套件的節點,這意味著它沒有子節點。

一旦遇到葉子節點,就使用值和策略網路來評估它包含的狀態的random rotation或reflection(因為Go規則在rotation或reflection條件下是不變的,更多是針對訓練部分),以獲得當前狀態的value和所有下一次move的機率。所有forbidden move的機率都變為0,然後機率向量被重新歸一化為1。
在此之後,在給定節點狀態的情況下,節點會隨著每一次的合法move(在probas陣列中具有非零機率的move)而擴充套件,其函式如下。

BACKUP
一旦expansion完成之後,節點及其父節點的統計資訊將使用以下函式和loop以及值網路預測的值進行更新。

Move Selection
現在simulation部分就完成了,每一次潛在的下一次move都包含了描述move質量的統計資料。move的選擇遵循兩種情況。
第一種是AlphaGo進行competition的地方,所選的move是最優的simulated move。這種情況在除了evaluation和training之外的一般比賽中應用。
第二種情況是,透過使用以下方案將訪問計數矩陣轉換為機率分佈,隨機選擇move。

這種選擇方法允許AlphaGo在training期間早期探索更多潛在選項。經過一定量的move(temperature constant),move選擇將變得有競爭力。
Final pipeline
現在已經分別解釋了每一個單獨的block,現在讓我們把它們拼接起來看看AlphaGo實際上是如何訓練的。
在專案開始時,至少啟動了兩個“核心”流程。第一個是self-play,第二個是training。理想情況下,兩個行程都將透過RAM進行通訊。然而,在不同的過程之間傳遞資訊並不簡單,在這種情況下,它將self-play過程中生成的遊戲狀態傳送到訓練過程中,以便用最佳質量的遊戲資料來更新資料集,使Agent更快地從更好的遊戲state中學習。為了做到這一點,本文將採用MongoDB資料庫儲存資料,使每個行程能夠獨立執行,同時只有一個真正的資訊源。
Self-play
self-play部分負責生成資料。它透過使用當前最好的Agent來於自己對抗。遊戲結束後(採用兩個玩家樣式,採用一人走一次或多次的樣式進行play),遊戲的每個registered動作都會隨著遊戲的獲勝者而更新,從( board_state,move,player_color )變為( board_state,move,winner )。每次生成一個batch資料時,該過程都會驗證用於生成遊戲的當前Agent仍然是最佳Agent。下麵的函式是如何進行self-play的一個rough sketch。

Training
Training則相對簡單。使用新生成的遊戲state資料訓練當前最佳Agent。資料中的所有state都採用中使用均方的二面角旋轉(dihedral rotations of a square)(旋轉和對稱)來擴充資料。每經過幾次迭代,訓練過程都會檢查資料庫,看看self-play過程是否已經生成了新的遊戲資料,如果是,訓練過程就會提取新的資料並更新相應的資料集。在經過幾次迭代之後,訓練好的Agent被非同步傳送到另一個過程中進行評估,如下麵的函式所述。

用來訓練agent的損失函式是遊戲實際輸贏值和預測值之間的均方差之和,以及move分佈和預測機率分佈之間的交叉熵構成的損失函式。它在程式碼中定義如下。

Evaluation
Evaluation由使用最新訓練的agent與當前最優的Agent進行比賽。他們會互相玩一定數量的遊戲,如果最新訓練的的Agent在一定時間內打敗了當前的最佳Agent(論文中55 %的時間),那麼最新訓練的Agent就會被儲存下來,成為新的最佳Agent。

Results
在本地的伺服器上訓練了一週之後,Agent人在9x 9圍棋棋盤上玩了大約20k個self-played的遊戲,使用了128個MCTS模擬,並行玩了10個遊戲,更新了大約463k引數,更換了417次最佳Agent。這是一段最佳agent與自己對戰的片段。
影片顯示,Agent並沒有學習遊戲的“基本原理”,比如life 和death,甚至Atari。然而,它似乎已經學習到answer locally似乎是一個很好的move。看起來agent也知道Go是關於territory,而不是正面作戰的遊戲,這在最初的幾個動作中有所顯示。Shapes也很糟糕,Agent仍然只在在自己的living groups中play,透過剝奪自由來殺死他們。
Discussion
最終沒能獲得一個不錯的結果。這提出了一個問題,是否是在程式碼實現中除了錯誤,或者也許是使用了錯誤的超引數。AlphaGo Zero使用490萬個遊戲進行訓練,但是模擬次數( 1600次)更高,所以較差的結果也可能是由於計算更新次數不夠導致的。
參考文獻
1. Mastering the game of Go without human knowledge—DeepMind
2. Very nice infographic on AlphaGo Zero – David Foster
3. Pachi Go game engine——佩特·鮑迪斯
本文所有程式碼
https://github.com/dylandjian/superGo
往期精彩內容推薦
模型彙總20-TACOTRON一種端到端的Text-to-Speech合成模型
最佳化策略5 Label Smoothing Regularization_LSR原理分析



DeepLearning_NLP


深度學習與NLP
商務合作請聯絡微訊號:lqfarmerlq