作者:Guest Blog;翻譯:張玲;校對:丁楠雅
本文約4700字,建議閱讀10+分鐘。
本文簡要介紹深度學習以及它支援的一些現有資訊保安應用,並提出一個基於深度學習的TOR流量檢測方案。
簡介
我們看到的大多數深度學習應用程式通常面向市場、銷售、金融等領域,但在使用深度學習來保護這些領域的產品和業務、避免惡意軟體和駭客攻擊方面,則鮮有文章或資源。
像谷歌、臉譜、微軟和SalesForce這樣的大型科技公司已經將深度學習嵌入他們的產品之中,但網路安全行業仍在迎頭趕上。這是一個具有挑戰性的領域,需要我們全力關註。

本文中,我們簡要介紹深度學習(Deep Learning,DL)以及它支援的一些現有資訊保安(此處稱為InfoSec)應用。然後,我們深入研究匿名TOR流量檢測這個有趣的問題,並提出一個基於深度學習的TOR流量檢測方案。
本文的標的讀者是已經從事機器學習專案的資料科學專業人員。本文內容假設您具備機器學習的基礎知識,而且當前是深度學習和其應用案例的初學者或探索者。
為了能夠充分理解本文,強烈推薦預讀以下兩篇文章:
-
《使用資料科學解開資訊保安的神秘面紗》
-
《深度學習的基礎知識-啟用功能以及何時使用它們》
目錄
一、資訊保安領域中深度學習系統的現狀
二、前饋神經網路概述
三、案例研究:使用深度學習檢測TOR流量
四、資料實驗-TOR流量檢測
一、資訊保安領域中深度學習系統的現狀
深度學習不是解決所有資訊保安問題的“靈丹妙藥”,因為它需要廣泛的標註資料集。不幸的是,沒有這樣的標記資料集可供使用。但是,有幾個深度學習網路對現有解決方案做出重大改進的資訊保安案例。惡意軟體檢測和網路入侵檢測恰是兩個這樣的領域,深度學習已經顯示出比基於規則和經典機器學習的解決方案有更顯著的改進。
網路入侵檢測系統通常是基於規則和簽名的控制元件,它們部署在外圍以檢測已知威脅。攻擊者改變惡意軟體簽名,就可以輕易地避開傳統的網路入侵檢測系統。Quamar等[1]在他們的IEEE學報論文中指出,有望採用自學的基於深度學習的系統來檢測未知的網路入侵。基於深度神經網路的系統已經用來解決傳統安全應用問題,例如檢測惡意軟體和間諜軟體[2]。

與傳統的機器學習方法相比,基於深度學習的技術的泛化能力更好。Jung等[3]基於深度學習的系統甚至可以檢測零日惡意軟體。畢業於巴塞羅那大學的Daniel已經做了大量有關CNN(Convolutional Neural Networks,摺積神經網路)和惡意軟體檢測的工作。他在博士論文中提及,CNNs甚至可以檢測變形惡意軟體。
現在,基於深度學習的神經網路正在使用者和物體行為分析(User and Entity Behaviour Analytics,UEBA)中使用。傳統上,UEBA採用異常檢測和機器學習演演算法。這些演演算法提取安全事件以分析和基線化企業IT環境中的每一個使用者和網路元素。任何偏離基線的重大偏差都會被觸發為異常,進一步引發安全分析師調查警報。UEBA強化了內部威脅的檢測,儘管程度有限。
現在,基於深度學習的系統被用來檢測許多其他型別的異常。波蘭華沙大學的Pawel Kobojek[4]使用擊鍵動力學來驗證使用者是否使用LSTM網路。Capital one安全資料工程總監JasonTrost 發表了幾篇部落格[5],其中包含一系列有關深度學習在InfoSec應用的技術論文和演講。
二、前饋神經網路概述
人工神經網路的靈感來自生物神經網路。神經元是生物神經系統的基本單元。每一個神經元由樹突、細胞核和軸突組成。它透過樹突接收訊號,並透過軸突進行傳遞(圖1)。計算在核中進行。整個網路由一系列神經元組成。
AI研究人員借用這個原理設計出人工神經網路(Artificial Neural Network,ANN)。在這樣的設定下,每個神經元完成三個動作:
-
它收集來自其他不同神經元的輸入或者經過加權處理的輸入
-
它對所有的輸入進行求和
-
基於求和值,它呼叫啟用函式
因此,每個神經元可以把一組輸入歸為一類或者其他類。當僅使用單個神經元時,這種能力會受到限制。但是,使用一組神經元足以使其成為分類和序列標記任務的強大機制。
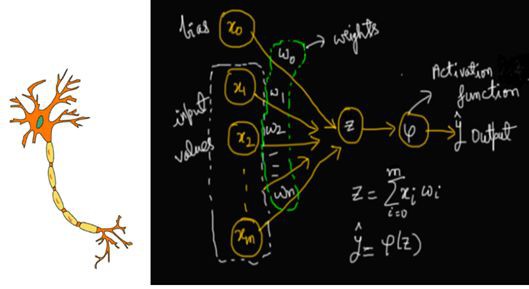
圖1:我們能獲得的最大靈感來自大自然——圖中描繪了一個生物神經元和一個人工神經元
可以使用神經元層來構建神經網路。網路需要實現的標的不同,其架構也是不同的。常見的網路架構是前饋神經網路(Feed ForWard Neural Network,FFN)。神經元在無環的情況下線性排列,形成FFN。因為資訊在網路內部向前傳播,它被稱為前饋。資訊首先經過輸入神經元層,然後經過隱藏神經元層和輸出神經元層(圖2)。

圖2:具有兩個隱藏層的前饋網路
與任何監督學習模型一樣,FFN需要使用標記的資料進行訓練。訓練的形式是透過減少輸出值和真值之間的誤差來最佳化引數。要最佳化的一個重要引數是每個神經元賦予其每個輸入訊號的權重。對於單個神經元來說,使用權重可以很容易地計算出誤差。
然而,在多層中調整一組神經元時,基於輸出層算出的誤差來最佳化多層中神經元的權重是具有挑戰性的。反向傳播演演算法有助於解決這個問題[6]。反向傳播是一項舊技術,屬於計算機代數的分支。這裡,自動微分法用來計算梯度。網路中計算權重的時候需要用到梯度。
在FFN中,基於每個連線神經元的啟用獲得結果。誤差逐層傳播。基於輸出與最終結果的正確性,計算誤差。接著,將此誤差反向傳播,以修正內部神經元的誤差。對於每個資料實體來說,引數是經過多次迭代優化出來的。
三、案例研究:使用深度學習檢測TOR流量
網路攻擊的主要目的是竊取企業使用者資料、銷售資料、智慧財產權檔案、原始碼和軟體秘鑰。攻擊者使用加密流量將被盜資料混夾在常規流量中,傳輸到遠端伺服器上。
大多數經常攻擊的攻擊者使用匿名網路,使得安全保護人員難以跟蹤流量。此外,被盜資料通常是加密的,這使得基於規則的網路入侵工具和防火牆失效。最近,匿名網路以勒索軟體/惡意軟體的變體形式用於C&C;。例如,洋蔥勒索[7]使用TOR網路和其C&C;伺服器進行通訊。

圖3:Alice與標的伺服器之間TOR通訊的說明。通訊開始於Alice向伺服器請求一個地址。TOR網路給出AES加密的路徑。路徑的隨機化發生在TOR網路內部。包的加密路徑用紅色顯示。當到達TOR網路的出口節點時,將簡單分組轉發給伺服器。出口節點是TOR網路的外圍節點。
匿名網路/流量可以透過多種方式完成,它們大體可分為:
-
基於網路(TOR,I2P,Freenet)
-
基於自定義系統(子圖作業系統,Freepto)
其中,TOR是比較流行的選擇之一。TOR是一款免費軟體,能夠透過稱為洋蔥路由協議的專用路由協議在網際網路上進行匿名通訊[9]。該協議依賴於重定向全球範圍內多個免費託管中繼的網際網路流量。在中繼期間,就像洋蔥皮的層一樣,每個HTTP包使用接收器的公鑰加密。
在每個接收點,使用私鑰對資料包進行解密。解密後,下一個標的中繼地址就會披露出來。這個過程會持續下去,直到找到TOR網路的出口節點為止。在這裡資料包解密結束,一個簡單的HTTP資料包會被轉發到原始標的伺服器。在圖3中展示了Alice和伺服器之間的一個示例路由方案。
啟動TOR最初的目的是保護使用者隱私。但是,攻擊者卻用它代替其他不法方式,來威逼善良的人。截至2016年,約有20%的TOR流量涉及非法活動。在企業網路中,透過不允許安裝TOR客戶端或者攔截保護或入口節點的IP地址來遮蔽TOR流量。
不管怎樣,有許多手段可以讓攻擊者和惡意軟體訪問TOR網路以傳輸資料和資訊。IP攔截策略不是一個合理的策略。一篇來自Distil網站[5]的自動程式情勢不佳報告顯示,2017年70%的自動攻擊使用多個IP,20%的自動攻擊使用超過100個IP。
可以透過分析流量包來檢測TOR流量。這項分析可以在TOR 節點上進行,也可以在客戶端和入口節點之間進行。分析是在單個資料包流上完成的。每個資料包流構成一個元組,這個元組包括源地址、源埠、標的地址和標的埠。
提取不同時間間隔的網路流,並對其進行分析。G.He等人在他們的論文“從TOR加密流量中推斷應用型別資訊”中提取出突發的流量和方向,以建立HMM(Hidden Markov Model,隱馬爾科夫模型)來檢測可能正在產生那些流量的TOR應用程式。這個領域中大部分主流工作都利用時間特徵和其他特徵如大小、埠資訊來檢測TOR流量。
我們從Habibi等人的“利用時間特徵來發現TOR流量的特點”論文中得到啟發,並遵循基於時間的方法提取網路流,用於本文TOR流量的檢測。但是,我們的架構使用了大量可以獲得的其他元資訊,來對流量進行分類。這本質上是由於我們已經選擇使用深度學習架構來解決這個問題。
四、資料實驗-TOR流量檢測
為了完成本文的資料實驗,我們從紐布倫斯威克大學的Habibi Lashkari等人[11]那裡獲取了資料。他們的資料由從校園網路流量分析中提取的特徵組成。從資料中提取的元資訊如下表所示:
|
元資訊引數 |
引數解釋 |
|
FIAT |
前向中間達到時間,向前傳送兩個資料包之間的時間(平均值,最大值,最小值,標準方差) |
|
BIAT |
後向中間達到時間,向後傳送兩個資料包之間的時間(平均值,最大值,最小值,標準方差) |
|
FLOWIAT |
流中間達到時間,向任何一個方向傳送兩個資料包之間的時間(平均值,最大值,最小值,標準方差) |
|
ACTIVE |
時間量,在變成空閑之前的活躍時間 |
|
IDLE |
時間量,在變成空閑之前的活躍時間 |
|
FB PSEC |
每秒流位元組數。每秒流量包。持續時間:資料流的持續時間。 |
表1:從[ 1 ]獲得的元資訊引數
除了這些引數之外,其他基於流的引數也包括在內。圖4顯示了一個資料集的樣例。

圖4:本文使用的資料集實體
請註意,源IP/埠、標的IP/埠和協議欄位已經從實體中刪除,因為它們會導致模型過擬合。我們使用具有N隱藏層的深度前饋神經網路來處理其他所有特徵。神經網路的架構如圖5所示。

圖5:用於Tor流量檢測的深度學習網路表示。
隱藏層層數在2和10之間變化。當N=5時是最優的。為了啟用,線性整流函式(Rectified Linear Unit, ReLU)用於所有隱藏層。隱藏層每一層實際上都是密集的,有100個維度。
Keras中的FFN的Python程式碼片段:
model = Sequential()
model.add(Dense(feature_dim, input_dim= feature_dim, kernel_initializer=’normal’, activation=’relu’))
for _ in range(0, hidden_layers-1):
model.add(Dense(neurons_num, kernel_initializer=’normal’, activation=’relu’))
model.add(Dense(1,kernel_initializer=’normal’, activation=’sigmoid’))
model.compile(optimizer=’adam’, loss=’binary_crossentropy’, metrics=[“accuracy”])
輸出節點由Sigmoid函式啟用。這被用來輸出二分類結果-TOR或非TOR。
我們在後端使用帶有TensorFlow的Keras來訓練深度學習模組。使用二元交叉熵損失來最佳化FFN。模型會被訓練不同次數。圖7顯示,在一輪模擬訓練中,隨著訓練次數的增加,效能也在增加,損失值也在下降。

圖7:網路訓練過程中Tensorboard生成的靜態圖
我們將深度學習系統的結果與其他預測系統進行了比較。使用召回率(Recall)、精準率(Precision)和F-Score這些標準分類指標來衡量預測系統效能。我們基於深度學習的系統能夠很好地檢測TOR類。但是,我們更加重視非TOR類。可以看出,基於深度學習的系統可以減少非TOR類的假陽性情況。結果如下表:
|
Classifier used |
Precision |
Recall |
F-Score |
|
Logistic Regression |
0.87 |
0.87 |
0.87 |
|
SVM |
0.9 |
0.9 |
0.9 |
|
Naïve Bayes |
0.91 |
0.6 |
0.7 |
|
Random Forest |
0.96 |
0.96 |
0.96 |
|
Deep Learning |
0.95 |
0.95 |
0.95 |
表2:用於TOR流量檢測實驗的深度學習和機器學習模型結果
在各種分類器中,隨機森林和基於深度學習的方法比其他方法更好。所示結果基於5,500個訓練實體。本實驗中使用資料集的大小相對小於典型的基於深度學習的系統。隨著訓練資料的增加,基於深度學習的系統和隨機森林分類器的效能將會進一步提升。
但是,對於大型資料集來說,基於深度學習的分類器通常優於其他分類器,並且可以針對相似型別的應用程式進行推廣。例如,如果需要訓練檢測使用TOR的應用程式,那麼只需要重新訓練輸出層,並且其他所有層可以保持不變。而其他機器學習分類器則需要在整個資料集上重新訓練。請記住,對於大型資料集來說,重新訓練模型需要耗費巨大的計算資源。
尾記
每個企業面臨的匿名流量檢測的挑戰是存在細微差別的。攻擊者使用TOR通道以匿名樣式偷竊資料。當前流量檢測供應商的方法依賴於攔截TOR網路的已知入口節點。這不是一個可拓展的方法,而且很容易繞過。一種通用的方法是使用基於深度學習的技術。
本文中,我們提出了一個基於深度學習的系統來檢測TOR流量,具有高召回率和高精準率。請下麵的評論部分告訴我們您對當前深度學習狀態的看法,或者如果您有其他替代方法。
References
[1]: Quamar Niyaz, Weiqing Sun, Ahmad Y Javaid, and Mansoor Alam, “A Deep Learning Approach for Network Intrusion Detection System,” IEEE Transactions on Emerging Topics in Computational Intelligence, 2018.
[2]: Daniel Gibert, “Convolutional Neural Networks for Malware Classification,” Thesis 2016.
[3]: Wookhyun Jung, Sangwon Kim,, Sangyong Choi, “Deep Learning for Zero-day Flash Malware Detection,” IEEE security, 2017.
[4]: Paweł Kobojek and Khalid Saeed, “Application of Recurrent Neural Networks for User
Verification based on Keystroke Dynamics,” Journal of telecommunications and information technology, 2016.
[5]:Deep Learning Security Papers, http://www.covert.io/the-definitive-security-datascience-and-machinelearning-guide/#deep-learning-and-security-papers, accessed on May 2018.
[6]: “Deep Learning,” Ian Goodfellow, Yoshua Bengio, Aaaron Courville; pp 196, MIT Press, 2016.
[7]: “The Onion Ransomware,” https://www.kaspersky.co.in/resource-center/threats/onion-ransomware-virus-threat, Retrieved on November 29, 2017.
[8]: “5 best alternative to TOR.,” https://fossbytes.com/best-alternatives-to-tor-browser-to-browse-anonymously/, Retrieved on November 29,2017.
[9]: Tor. Wikipedia., https://en.wikipedia.org/wiki/Tor_(anonymity_network), Retrieved on November 24, 2017.
[10]: He, G., Yang, M., Luo, J. and Gu, X., “ Inferring Application Type Information from Tor Encrypted Traffic,” Advanced Cloud and Big Data (CBD), 2014 Second International Conference on (pp. 220-227), Nov. 2014.
[11]: Habibi Lashkari A., Draper Gil G., Mamun M. and Ghorbani A., “Characterization of Tor Traffic using Time based Features,” Proceedings of the 3rd International Conference on Information Systems Security and Privacy – Volume 1, pages 253-262, 2017.
[13]: Juarez, M., Afroz, S., Acar, G., Diaz, C. and Greenstadt, R., “A critical evaluation of website fingerprinting attacks,” Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security (pp. 263-274), November 2014
[14]: Bai, X., Zhang, Y. and Niu, X., “Traffic identification of tor and web-mix,” Intelligent Systems Design and Applications, ISDA’08. Eighth International Conference on (Vol. 1, pp. 548-551). IEEE, November 2008
viumi
原文標題:
Using the Power of DeepLearning for Cyber Security
原文連結:
https://www.analyticsvidhya.com/blog/2018/07/using-power-deep-learning-cyber-security/
譯者簡介:張玲,在崗資料分析師,計算機碩士畢業。從事資料工作,需要重塑自我的勇氣,也需要終生學習的毅力。但我依舊熱愛它的嚴謹,痴迷它的藝術。資料海洋一望無境,資料工作充滿挑戰。感謝資料派THU提供如此專業的平臺,希望在這裡能和最專業的你們共同進步!
版權宣告:本號內容部分來自網際網路,轉載請註明原文連結和作者,如有侵權或出處有誤請和我們聯絡。
關聯閱讀
原創系列文章:
資料運營 關聯文章閱讀:
資料分析、資料產品 關聯文章閱讀:
80%的運營註定了打雜?因為你沒有搭建出一套有效的使用者運營體系
商務合作|約稿 請加qq:365242293
更多相關知識請回覆:“ 月光寶盒 ”;
資料分析(ID : ecshujufenxi )網際網路科技與資料圈自己的微信,也是WeMedia自媒體聯盟成員之一,WeMedia聯盟改寫5000萬人群。
