眾所周知,Kubernetes是目前最為火熱的容器編排工具之一,其背後有如此多的追隨者必然是有原因的。首先Kubernetes非常輕量,通常Kubernetes都是以容器作為載體,而容器本來就具有輕量級秒級部署的特點;再者Kubernetes有火熱的開源社群,自從Kubernetes加入CNCF(Cloud Native Computing Foundation,雲原生計算基金會)後,來自世界各地的許多容器開發者參與其中,其中不乏有像Redhat、IBM、華為等大廠的開發人員,因此良好的生態圈成為了最受關註的原因之一。
在Kubernetes中部署應用是一件容易的事,因其有著彈性伸縮,橫向擴充套件的優勢並同時提供負載均衡能力以及良好的自愈性(自動部署、自動重啟、自動複製、自動擴充套件等),那麼這些Kubernetes的優勢在叢集中又是如何被體現出來的呢?
Kubernetes的架構分為Master和Node兩部分,如圖1所示。由上圖可以看出這兩部分由五種主要的元件構成,它們之間協同工作從而完成整個叢集的管理,這五種元件分別為API Server、Controller Manager、Scheduler、Kubelet、etcd。本文主要從一個簡單的Pod工作流出發,涉及到架構中的元件並深入講解其工作機制,下麵先簡單介紹下Kubernetes中元件和資源物件的基本概念。
-
Pod:Kubernetes中執行應用或服務的最小單元,其設計理念是支援多個容器在一個Pod中共享網路地址和檔案系統
-
Service:訪問Pod的代理抽象服務,主要用於叢集內部的服務發現和負載均衡
-
Replication Controller:用於伸縮Pod副本數量的元件
-
API Server:對以上1、2、3資源物件進行增、刪、改、查的Rest API伺服器
-
Scheduler:叢集中資源物件的排程控制器
-
Controller Manager:負責叢集中資源物件管理同步的元件
-
etcd:分散式鍵值對(k,v)儲存服務,儲存整個叢集的狀態資訊
-
Kubelet:負責維護Pod容器的生命週期
-
Label:用於Service及Replication Controller 與Pod關聯的標簽
假設此Kubernetes環境包含一個Master節點,若干個Node節點。後面說明一律按照此環境作為假設。接下來給大家展示一個簡單的Pod工作流,如圖2所示:
(1)提交請求:使用者通常提交一個yaml檔案,向API Server傳送請求建立一個Pod, yaml檔案含有此Pod的詳細資訊,包含此Pod執行副本數、映象、Labels、名稱,埠暴露情況等。API Server接收到請求後將yaml檔案中的spec資料存入etcd中;
(2)資源狀態同步:這一步涉及到Replication元件,Replication元件監控著資料庫中的資料變化,對已有的Pod進行數量上的同步;
(3)資源分配:Scheduler會檢查Etcd資料庫中記錄的沒有被分配的Pod,將此類Pod分配至具有執行能力的Node節點中,並更新Etcd資料庫中的Pod分配情況;
(4)新建容器:kubernetes叢集節點中的Kubelet對Etcd資料庫中的Pod部署狀態進行同步,標的Node節點上的Kubelet將Pod相關yaml檔案中的spec資料遞給後面的容器執行時引擎(如Docker等),後者負責Pod容器的執行停止和更新;Kubelet會透過容器執行時引擎獲取Pod的狀態並將資訊更新至API Server,最後寫入etcd中;
(5)節點通訊:Kube-proxy負責各節點中Pod的網路通訊,包括服務發現和負載均衡。
從以上Kubernetes工作流可看出,從客戶端傳送建立Pod請求到Pod最終部署至節點期間參與的主要元件有API Server、 Controller-Manager、 Scheduler、 Kubelet、etcd。
etcd元件在整個Pod工作流中主要為其它四個元件提供元件狀態儲存,不多做解釋。下麵將分別對其它四個元件的工作機制予以具體說明。

API Server元件在如上Pod工作流中體現的功能主要分為以下幾個部分:
-
為整個Pod工作流提供了資源物件(Pod,Deployment,Service等)的增刪改查以及用於叢集管理的Rest API介面,叢集管理主要包括認證授權,叢集狀態管理和資料校驗等。
-
提供叢集中各元件的通訊以及互動的功能。
-
提供資源配額控制入口功能。
-
安全的訪問控制機制。
以下是API Server的工作原理圖,如圖3所示:
在Kubernetes叢集中,API Server執行在Master節點上,預設開放兩個埠,分別為本地埠8080(非認證或授權的http請求透過該埠訪問API Server)和安全埠6443( 該埠用於接收https請求並且用於token檔案或客戶端證書及HTTP Basic的認證同時用於基於策略的授權),Kubernetes中預設為不啟動https安全訪問控制。
API Server在整個Pod工作流中主要負責各個元件間的通訊,Scheduler,Controller Manager,Kubelet透過API Server將資源物件資訊存入etcd中,當各元件需要這些資料時又透過API Server的Rest介面來實現資訊互動,以下分別說明:
在Pod工作流中,位於叢集中每個Node節點上的Kubelet會定期呼叫API Server的Rest介面去告知當前自身狀態,API Sever接收到狀態資訊後,將其更新至etcd中,Kubelet也同時透過API Server的Watch介面去監聽Pod資訊,從而對各個Node節點上的Pod進行管理,主要監聽資訊如表1所示:
|
監聽資訊
|
Kubelet 執行
|
|
是否有新的Pod被系結到Node節點
|
執行Pod對應容器的建立和啟動
|
|
是否有Pod物件被刪除
|
刪除Node上相應Pod容器
|
|
是否有修改Pod資訊
|
修改Node上Pod的資訊
|
2、kube-controller-manager與API Server
Controller Manager包含許多控制器,例如Endpoint Controller、Replication Controller、Service Account Controller等, 具體會在後面Controller Manager部分說明,這些控制器透過API Server提供的介面去實時監控當前Kubernetes叢集中每個資源物件的狀態變化並將最新的資訊儲存在etcd中,當叢集中發生各種故障導致系統發生變化時,各個控制器會從etcd中獲取資源物件資訊並嘗試將系統狀態修複至理想狀態。
3、kube-scheduler與API Server
Scheduler透過API Server的Watch介面監聽Master節點新建的Pod副本資訊並檢索所有符合該Pod要求的Node串列同時執行排程邏輯,成功後將Pod系結在標的節點處。
由於在叢集中各元件頻繁對API Server進行訪問,各元件採用了快取機制來緩解請求量,各元件定時從API Server獲取資源物件資訊並將其儲存在本地快取中,所以元件大部分時間是透過訪問快取資料來獲得資訊的。
Controller Manager在Pod工作流中起著管理和控制整個叢集的作用,主要對資源物件進行管理,當Node節點中執行的Pod物件或是Node自身發生意外或故障時,Controller Manager會及時發現並處理,以確保整個叢集處於理想工作狀態。
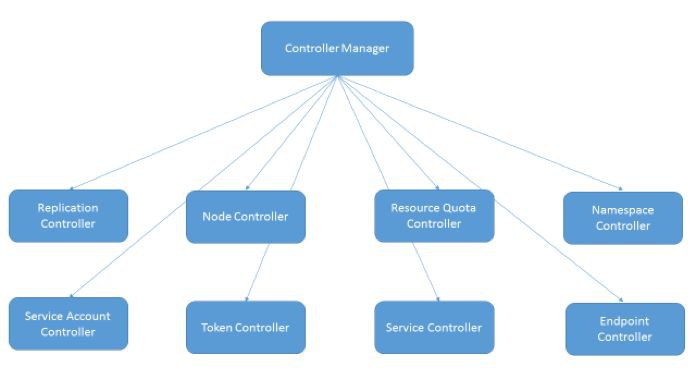
Controller Manager組成如圖4所示:
由圖4我們可以看出Controller Manager由8個不同的控制器組成。以下主要對Replication Controller、Endpoint Controller予以說明。
Replication Controller稱為副本控制器,在Pod工作流中主要用於保證叢集中Replication Controller所關聯的Pod副本數始終保持在預期值,比如若發生節點故障的情況導致Pod被意外殺死,Replication Controller會重新排程保證叢集仍然執行指定副本數,另外還可透過調整Replication Controller中spec.replicas屬性值來實現擴容或縮容。
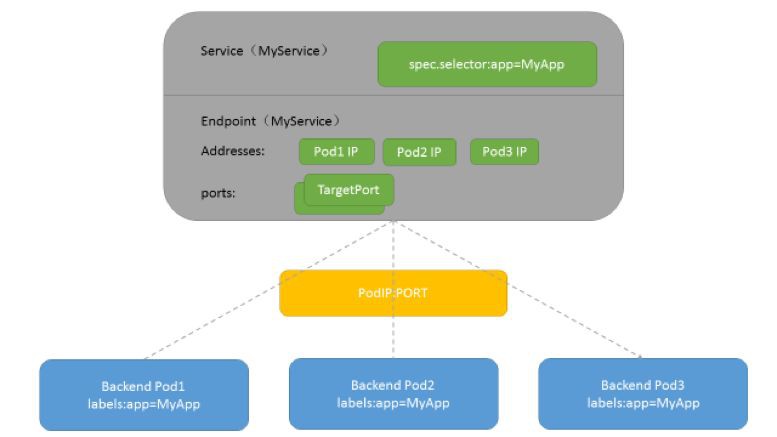
Endpoint用來表示kubernetes叢集中Service對應的後端Pod副本的訪問地址,Endpoint Controller則是用來生成和維護Endpoints物件的控制器,其主要負責監聽Service和對應Pod副本變化。如果監測到Service被刪除,則刪除和該Service同名的Endpoints物件;如果監測到新的Service被建立或是被修改,則根據該Service資訊獲得相關的Pod串列,然後建立或更新對應的Endpoints物件;如果監測到Pod的事件,則更新它對應的Service的Endpoints物件。圖5所示為Service、Endpoint、Pod的關係:
Scheduler在整個Pod工作流中負責排程Pod到具體的Node節點,Scheduler透過API Server監聽Pod狀態,如果有待排程的Pod,則根據Scheduler Controller中的預選策略和優選策略給各個預備Node節點打分排序,最後將Pod排程到分數最高的Node上,然後由Node中的Kubelet元件負責Pod的啟停。當然如果部署的Pod指定了NodeName屬性,Scheduler會根據NodeName屬性值排程Pod到指定Node節點。
預選策略的主要工作機制是遍歷所有當前Kubernetes叢集中的Node,按照具體的預選策略選出符合要求的Node串列;如果沒有符合的Node節點,則該Pod會被暫時掛起,直到有Node節點能滿足條件。通用的預選策略篩選規則有:PodFitsResources、PodFitsHostPorts、HostName、MatchNodeSelector。
有了第一步預選策略的篩選後,再根據優選策略給待選Node節點打分,最終選擇一個分值最高的節點去部署Pod。Kubernetes用一組優先順序函式處理每一個待選的主機。每一個優先順序函式會傳回一個0-10的分數,分數越高表示節點越適應需求,同時每一個函式也會對應一個表示權重的值。最終主機的得分用以下公式計算得出:
FinalScoreNode =(weight1 priorityFunc1)+(weight2 priorityFunc2)+ … +(weightn * priorityFuncn)
如果新的 Pod 要分配一個Node節點,這個節點的優先順序就由節點空閑的那部分與總容量的比值((總容量-節點上Pod的容量總和-新Pod的容量)/總容量)來決定。cpu和 memory權重相當,比值最大的Node節點得分最高。這個優先順序函式起到了按照資源消耗來跨Node節點分配 Pods 的作用。計算公式如下:
FinalScoreNode = cpu((capacity – sum(requested))10 / capacity)+ memory((capacity – sum(requested))10 / capacity)/ 2
2、BalancedResourceAllocation
優先從備選節點串列中選擇各項資源使用率最均衡的Node節點。BalancedResourceAllocation 必須和 LeastRequestedPriority同時使用而不能單獨使用,它們分別計算主機上的cpu和memory的比重,Node節點分值由cpu比重和memory比重的“距離”決定。計算公式如下:
FinalScoreNode = 10 – abs(cpuFraction-memoryFraction)*10
對於屬於同一個 Service、Replication Controller的Pod,儘量分散在不同的Node上。如排程一個Pod的時候,先查詢Pod對應的Service或Replication Controller,然後查詢Service或Replication Controller中已存在的Pod,Node節點上執行的已存在的Pod越少,Node的打分越高。
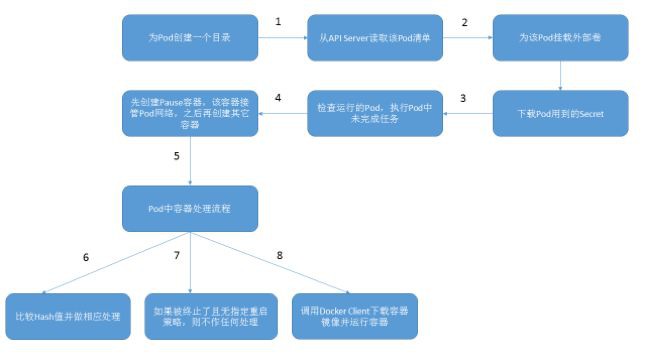
簡而言之,Kubelet在Pod工作流中是為保證它所在的節點Pod能夠正常工作,核心為監聽API Server,當發現節點的Pod配置發生變化則根據最新的配置執行相應的動作,保證Pod在理想的預期狀態,其中對Pod進行啟停更新操作用到的是容器執行時(Docker、Rocket、LXD)。另外Kubelet也負責Volume(CVI)和網路(CNI)的管理。
在Pod工作流中,當Pod被分配至Node節點後Kubelet就去管理此Pod的生命週期,流程如下:
以上是對Kubernetes四個重要元件API Server、Controller Manager、Scheduler、Kubelet工作機制的解析,相信大家讀完以後對這四種元件一定有了自己的見解,筆者建議在Kubernetes環境中部署應用前一定要理解kubernetes的元件架構,這樣不僅有益於叢集出現問題時的故障排查,也有助於個人理解Kubernetes機制。
Kubernetes版本迭代十分頻繁,目前已更新到v 1.11,以上關於Kubernetes相關特性在之後的版本中可能會被棄用或更改,筆者的觀點也只限於v1.11及之前的版本,希望感興趣的同學們密切關註官方檔案的更新狀況以獲取最新訊息。
Kubernetes專案實戰訓練將於2018年8月17日在深圳開課,3天時間帶你係統掌握Kubernetes。本次培訓包括:Docker介紹、Docker映象、網路、儲存、容器安全;Kubernetes架構、設計理念、常用物件、網路、儲存、網路隔離、服務發現與負載均衡;Kubernetes核心元件、Pod、外掛、微服務、雲原生、Kubernetes Operator、叢集災備、Helm等,點選下方圖片檢視詳情。
長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。
![]()
微信掃一掃
使用小程式