來源:Vamei
www.cnblogs.com/vamei/p/9329278.html
記憶體是計算機的主儲存器。記憶體為行程開闢出行程空間,讓行程在其中儲存資料。我將從記憶體的物理特性出發,深入到記憶體管理的細節,特別是瞭解虛擬記憶體和記憶體分頁的概念。
記憶體
簡單地說,記憶體就是一個資料貨架。記憶體有一個最小的儲存單位,大多數都是一個位元組。記憶體用記憶體地址(memory address)來為每個位元組的資料順序編號。因此,記憶體地址說明瞭資料在記憶體中的位置。記憶體地址從0開始,每次增加1。這種線性增加的儲存器地址稱為線性地址(linear address)。為了方便,我們用十六進位制數來表示記憶體地址,比如0x00000003、0x1A010CB0。這裡的“0x”用來表示十六進位制。“0x”後面跟著的,就是作為記憶體地址的十六進位制數。
記憶體地址的編號有上限。地址空間的範圍和地址匯流排(address bus)的位數直接相關。CPU透過地址匯流排來向記憶體說明想要存取資料的地址。以英特爾32位的80386型CPU為例,這款CPU有32個針腳可以傳輸地址資訊。每個針腳對應了一位。如果針腳上是高電壓,那麼這一位是1。如果是低電壓,那麼這一位是0。32位的電壓高低資訊透過地址匯流排傳到記憶體的32個針腳,記憶體就能把電壓高低資訊轉換成32位的二進位制數,從而知道CPU想要的是哪個位置的資料。用十六進製表示,32位地址空間就是從0x00000000 到0xFFFFFFFF。
記憶體的儲存單元採用了隨機讀取儲存器(RAM, Random Access Memory)。所謂的“隨機讀取”,是指儲存器的讀取時間和資料所在位置無關。與之相對,很多儲存器的讀取時間和資料所在位置有關。就拿磁帶來說,我們想聽其中的一首歌,必須轉動帶子。如果那首歌是第一首,那麼立即就可以播放。如果那首歌恰巧是最後一首,我們快進到可以播放的位置就需要花很長時間。我們已經知道,行程需要呼叫記憶體中不同位置的資料。如果資料讀取時間和位置相關的話,計算機就很難把控行程的執行時間。因此,隨機讀取的特性是記憶體成為主儲存器的關鍵因素。
記憶體提供的儲存空間,除了能滿足內核的執行需求,還通常能支援執行中的行程。即使行程所需空間超過記憶體空間,記憶體空間也可以透過少量拓展來彌補。換句話說,記憶體的儲存能力,和計算機執行狀態的資料總量相當。記憶體的缺點是不能持久地儲存資料。一旦斷電,記憶體中的資料就會消失。因此,計算機即使有了記憶體這樣一個主儲存器,還是需要硬碟這樣的外部儲存器來提供持久的儲存空間。
虛擬記憶體
記憶體的一項主要任務,就是儲存行程的相關資料。我們之前已經看到過行程空間的程式段、全域性資料、棧和堆,以及這些這些儲存結構在行程執行中所起到的關鍵作用。有趣的是,儘管行程和記憶體的關係如此緊密,但行程並不能直接訪問記憶體。在Linux下,行程不能直接讀寫記憶體中地址為0x1位置的資料。行程中能訪問的地址,只能是虛擬記憶體地址(virtual memory address)。作業系統會把虛擬記憶體地址翻譯成真實的記憶體地址。這種記憶體管理方式,稱為虛擬記憶體(virtual memory)。
每個行程都有自己的一套虛擬記憶體地址,用來給自己的行程空間編號。行程空間的資料同樣以位元組為單位,依次增加。從功能上說,虛擬記憶體地址和物理記憶體地址類似,都是為資料提供位置索引。行程的虛擬記憶體地址相互獨立。因此,兩個行程空間可以有相同的虛擬記憶體地址,如0x10001000。虛擬記憶體地址和物理記憶體地址又有一定的對應關係,如圖1所示。對行程某個虛擬記憶體地址的操作,會被CPU翻譯成對某個具體記憶體地址的操作。

圖1 虛擬記憶體地址和物理記憶體地址的對應
應用程式來說對物理記憶體地址一無所知。它只可能透過虛擬記憶體地址來進行資料讀寫。程式中表達的記憶體地址,也都是虛擬記憶體地址。行程對虛擬記憶體地址的操作,會被作業系統翻譯成對某個物理記憶體地址的操作。由於翻譯的過程由作業系統全權負責,所以應用程式可以在全過程中對物理記憶體地址一無所知。因此,C程式中表達的記憶體地址,都是虛擬記憶體地址。比如在C語言中,可以用下麵指令來列印變數地址:
int v = 0;
printf(“%p”, (void*)&v);
本質上說,虛擬記憶體地址剝奪了應用程式自由訪問物理記憶體地址的權利。行程對物理記憶體的訪問,必須經過作業系統的審查。因此,掌握著記憶體對應關係的作業系統,也掌握了應用程式訪問記憶體的閘門。藉助虛擬記憶體地址,作業系統可以保障行程空間的獨立性。只要作業系統把兩個行程的行程空間對應到不同的記憶體區域,就讓兩個行程空間成為“老死不相往來”的兩個小王國。兩個行程就不可能相互篡改對方的資料,行程出錯的可能性就大為減少。
另一方面,有了虛擬記憶體地址,記憶體共享也變得簡單。作業系統可以把同一物理記憶體區域對應到多個行程空間。這樣,不需要任何的資料複製,多個行程就可以看到相同的資料。內核和共享庫的對映,就是透過這種方式進行的。每個行程空間中,最初一部分的虛擬記憶體地址,都對應到物理記憶體中預留給內核的空間。這樣,所有的行程就可以共享同一套核心資料。共享庫的情況也是類似。對於任何一個共享庫,計算機只需要往物理記憶體中載入一次,就可以透過操縱對應關係,來讓多個行程共同使用。IPO中的共享記憶體,也有賴於虛擬記憶體地址。
記憶體分頁
虛擬記憶體地址和物理記憶體地址的分離,給行程帶來便利性和安全性。但虛擬記憶體地址和物理記憶體地址的翻譯,又會額外耗費計算機資源。在多工的現代計算機中,虛擬記憶體地址已經成為必備的設計。那麼,作業系統必須要考慮清楚,如何能高效地翻譯虛擬記憶體地址。
記錄對應關係最簡單的辦法,就是把對應關係記錄在一張表中。為了讓翻譯速度足夠地快,這個表必須載入在記憶體中。不過,這種記錄方式驚人地浪費。如果樹莓派1GB物理記憶體的每個位元組都有一個對應記錄的話,那麼光是對應關係就要遠遠超過記憶體的空間。由於對應關係的條目眾多,搜尋到一個對應關係所需的時間也很長。這樣的話,會讓樹莓派陷入癱瘓。
因此,Linux採用了分頁(paging)的方式來記錄對應關係。所謂的分頁,就是以更大尺寸的單位頁(page)來管理記憶體。在Linux中,通常每頁大小為4KB。如果想要獲取當前樹莓派的記憶體頁大小,可以使用命令:
$getconf PAGE_SIZE
得到結果,即記憶體分頁的位元組數:
4096
傳回的4096代表每個記憶體頁可以存放4096個位元組,即4KB。Linux把物理記憶體和行程空間都分割成頁。
記憶體分頁,可以極大地減少所要記錄的記憶體對應關係。我們已經看到,以位元組為單位的對應記錄實在太多。如果把物理記憶體和行程空間的地址都分成頁,核心只需要記錄頁的對應關係,相關的工作量就會大為減少。由於每頁的大小是每個位元組的4000倍。因此,記憶體中的總頁數只是總位元組數的四千分之一。對應關係也縮減為原始策略的四千分之一。分頁讓虛擬記憶體地址的設計有了實現的可能。
無論是虛擬頁,還是物理頁,一頁之內的地址都是連續的。這樣的話,一個虛擬頁和一個物理頁對應起來,頁內的資料就可以按順序一一對應。這意味著,虛擬記憶體地址和物理記憶體地址的末尾部分應該完全相同。大多數情況下,每一頁有4096個位元組。由於4096是2的12次方,所以地址最後12位的對應關係天然成立。我們把地址的這一部分稱為偏移量(offset)。偏移量實際上表達了該位元組在頁內的位置。地址的前一部分則是頁編號。作業系統只需要記錄頁編號的對應關係。
 圖2 地址翻譯過程
圖2 地址翻譯過程
多級分頁表
記憶體分頁制度的關鍵,在於管理行程空間頁和物理頁的對應關係。作業系統把對應關係記錄在分頁表(page table)中。這種對應關係讓上層的抽象記憶體和下層的物理記憶體分離,從而讓Linux能靈活地進行記憶體管理。由於每個行程會有一套虛擬記憶體地址,那麼每個行程都會有一個分頁表。為了保證查詢速度,分頁表也會儲存在記憶體中。分頁表有很多種實現方式,最簡單的一種分頁表就是把所有的對應關係記錄到同一個線性串列中,即如圖2中的“對應關係”部分所示。
這種單一的連續分頁表,需要給每一個虛擬頁預留一條記錄的位置。但對於任何一個應用行程,其行程空間真正用到的地址都相當有限。我們還記得,行程空間會有棧和堆。行程空間為棧和堆的增長預留了地址,但棧和堆很少會佔滿行程空間。這意味著,如果使用連續分頁表,很多條目都沒有真正用到。因此,Linux中的分頁表,採用了多層的資料結構。多層的分頁表能夠減少所需的空間。
我們來看一個簡化的分頁設計,用以說明Linux的多層分頁表。我們把地址分為了頁編號和偏移量兩部分,用單層的分頁表記錄頁編號部分的對應關係。對於多層分頁表來說,會進一步分割頁編號為兩個或更多的部分,然後用兩層或更多層的分頁表來記錄其對應關係,如圖3所示。
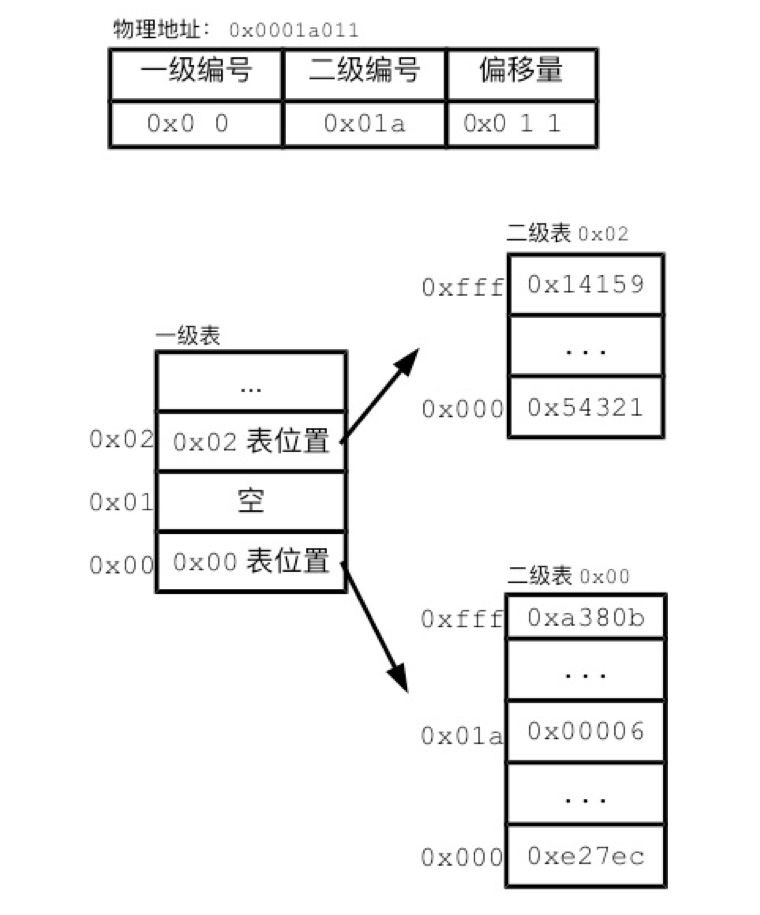 圖3 多層分頁表
圖3 多層分頁表
在圖3的例子中,頁編號分成了兩級。第一級對應了前8位頁編號,用2個十六進位制數字表示。第二級對應了後12位頁編號,用3個十六進位制編號。二級表記錄有對應的物理頁,即儲存了真正的分頁記錄。二級表有很多張,每個二級表分頁記錄對應的虛擬地址前8位都相同。比如二級表0x00,裡面記錄的前8位都是0x00。翻譯地址的過程要跨越兩級。我們先取地址的前8位,在一級表中找到對應記錄。該記錄會告訴我們,標的二級表在記憶體中的位置。我們再在二級表中,透過虛擬地址的後12位,找到分頁記錄,從而最終找到物理地址。
多層分頁表就好像把完整的電話號碼分成區號。我們把同一地區的電話號碼以及對應的人名記錄同通一個小本子上。再用一個上級本子記錄區號和各個小本子的對應關係。如果某個區號沒有使用,那麼我們只需要在上級本子上把該區號標記為空。同樣,一級分頁表中0x01記錄為空,說明瞭以0x01開頭的虛擬地址段沒有使用,相應的二級表就不需要存在。正是透過這一手段,多層分頁表佔據的空間要比單層分頁表少了很多。
多層分頁表還有另一個優勢。單層分頁表必須存在於連續的記憶體空間。而多層分頁表的二級表,可以散步於記憶體的不同位置。這樣的話,作業系統就可以利用零碎空間來儲存分頁表。還需要註意的是,這裡簡化了多層分頁表的很多細節。最新Linux系統中的分頁表多達3層,管理的記憶體地址也比本章介紹的長很多。不過,多層分頁表的基本原理都是相同。
綜上,我們瞭解了記憶體以頁為單位的管理方式。在分頁的基礎上,虛擬記憶體和物理記憶體實現了分離,從而讓核心深度參與和監督記憶體分配。應用行程的安全性和穩定性因此大為提高。
●編號564,輸入編號直達本文
●輸入m獲取文章目錄

運維
更多推薦《18個技術類微信公眾號》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
