容器技術越來越普遍,很多公司已經將容器技術作為基礎架構的一部分,容器中可以執行任何軟體,包括 Web Server、Application Server、資料庫和儲存系統等,其中 Nginx 作為 Web Server 使用也非常的普遍,接下來本文簡要分析下 Nginx 在容器內使用遇到的一點小問題。
我們在物理機上配置 Nginx 時通常會將 Nginx 的 worker 行程數配置為 CPU 核心數並且會將每個 worker 系結到特定 CPU 上,這可以有效提升行程的 Cache 命中率,從而減少記憶體訪問損耗,不放過任何能夠榨取系統效能的機會;對於需要手動配置 Nginx 行程個數的場景不在本文的討論範疇內,例如:磁碟 IO 密集型業務可能會導致 Nginx 行程阻塞,我們通常會將 Nginx 的行程數設定為 CPU 核數的 2 倍,用於提高整體的併發。
在 Nginx 配置中指定 worker_processes 指令的引數為 auto 來自動檢測系統的 CPU 核心數從而啟動相應個數的 worker 行程,那麼在 Linux 系統上 Nginx 是怎樣獲取 CPU 核心數的呢?答案是透過系統呼叫 sysconf(_SC_NPROCESSORS_ONLN) 獲取到系統當前可用的 CPU 核心數。如果我們在一個 CPU 是 32 cores 的物理機上啟動 Nginx,那麼 sysconf(_SC_NPROCESSORS_ONLN) 傳回值為 32。
假如我們將 Nginx 放進 Docker 啟動的容器內,sysconf(_SC_NPROCESSORS_ONLN) 的傳回值是多少呢?
透過 docker run 啟動一個帶有 Nginx 的容器,暫時不對此容器的 CPU 資源做任何限制也就是可以使用物理機上的所有資源,我們來觀察 Nginx 行程啟動的行程數(確認 Nginx 配置中的 worker_processes 指令設定為 auto),答案其實大家都清楚的 Nginx 啟動了 32 個 worker 行程。
接下來我們對容器的 CPU 資源做限制,透過 docker run 時指定 –cpuset-cpus=”0,1″ 引數系結容器內的行程到 CPU-0 和 CPU-1 上,然後再來觀察 Nginx 行程啟動的行程數,同樣還是 32 個 worker 行程;對容器設定 cpu-shares 和 cpu-quota 也會得到同樣的結果。
-
與我們預期的相符嗎?
-
指定了 –cpuset-cpus 能使用的核心數為 2 個,為什麼獲取到的 CPU 核心數還是 32 呢?
很多人都是知道的,我們更期望的結果對於上邊的設定只啟動兩個 worker 行程,行程得到的 CPU 時間片期望被 2 個行程分攤,現在需要被 32 個行程分攤;從 Nginx 角度來看想要獲得更多的時間片就需要減少在這個 CPU 上執行的行程,這樣整體效能才會提升。對於 Nginx 來說也就是期望根據可用的 CPU 核數啟動相應的行程數,而不是根據物理機上可用的 CPU 核數來設定行程數。
對於容器來說目前還只是一個輕量級的隔離環境,它並不是一個真正的作業系統,那麼在容器中獲取可用 CPU 核心數和 Memory 大小均是物理機配置。在沒有容器的時候很多軟體依賴於作業系統的資源進行初始化配置的,例如:JVM 根據 CPU 核數啟動相應的 gc 執行緒,根據物理機的 memroy 設定堆大小。
我們透過一個簡單的壓測對比一下在容器中 Nginx 啟動不同 worker 行程對 QPS 和 Latency 影響有多大。
cpu-quota=400000(即容器內的行程最多可以使用 400% 的 CPU)
wrk -t 32 -c 500 -d 180 http://container_ip
容器內安裝 Openresty、將 worker_processes 修改為 4 和 32,關閉 access 日誌,響應資料為 541byte。
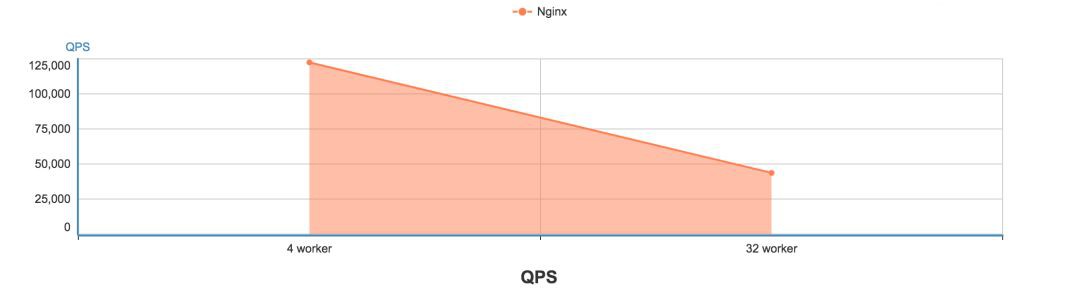
以下是 Nginx 的 QPS 和 Latency 壓測結果,QPS 從 12 萬 + 降到了 4 萬 +,Latency 也從 6+ms 降到了 25+ms。
從以上壓測資料可以看出,Nginx 在設定 worker 行程數為 4 和 32 時 QPS 和 Latency 有很大的差距的,瞭解了以上問題我們該如何解決呢?
先來說一下普遍使用的 Lxcfs,對於上邊提到的場景是不適用的,Lxcfs 目前僅支援改變容器的 CPU 檢視(/proc/cpuinfo 檔案內容)並且只有 –cpuset-cpus 引數可以生效,對於系統呼叫 sysconf(_SC_NPROCESSORS_ONLN) 傳回的同樣還是物理機的 CPU 核數。
透過建立引導程式根據容器可以使用的物理資源自動計算出合理值並設定應用程式的啟動引數,例如:透過 shell 指令碼動態修改 Nginx 的 worker 行程數。
應用程式自行解析容器內的 cgroup 資訊,並設定程式的啟動引數。Docker 在 1.8 版本以後將容器分配的 cgroup 資訊掛載進了容器內部,在容器內可以透過解析 cgroup 資訊獲取到當前容器可以使用的資源資訊。例如:JDK 10 中引入了支援 Docker 容器的資源檢測並配置 JVM 的執行時引數,它的原理就是解析容器內的 cgroup 資訊配置 gc 執行緒數以及堆大小。
劫持系統呼叫 sysconf,在類 Unix 系統上可以透過 LD_PRELOAD 這種機制預先載入個人編寫的的動態連結庫,在動態連結庫中劫持系統呼叫 sysconf 並根據 cgroup 資訊動態計算出可用的 CPU 核心數。

我們團隊也參考了 JVM 的實現並根據 Nginx 的程式碼風格給 Nginx 打了一個 patch,使 Nginx 的 worker_processes auto 引數能夠根據當前容器的可用資源自動計算出合理的 worker 行程數,同時也提交給了 Nginx 社群,但是很遺憾 Nginx 社群負責人 Maxim 並不願意接受這種實現方式,他更希望的是容器能透明支援 sysconf(_SC_NPROCESSORS_ONLN) 系統呼叫的功能,而不是用這種解析 cgroup 檔案的方式實現,於是我們就實現了一個可以劫持系統呼叫 sysconf 的動態連結庫。
可能有人會有疑問,為什麼 JVM 能接受解析 cgroup 檔案這種方式,而 Nginx 卻不能接受這種方式呢?
根據我的理解目前這個小問題對 Nginx 不是最痛的,不支援也不妨礙使用,另一點是 Nginx 作者以及現在的主要維護者 Maxim 都有重度程式碼潔癖,從程式碼風格以及程式碼中幾乎無註釋可以感受的到,Nginx 推崇的是程式碼即檔案,要求寫程式碼的人像寫檔案一樣使程式碼的可讀性非常高,對於這種用幾百行程式碼解決的問題他們更不能忍受。而 JVM 支援的這種方式很大原因是這個問題的確很痛,網上有很多人都有報 JVM 在容器內的配置不合理導致執行時出現各種問題,所以目前通用的解決方案也只能是解析 cgroup 檔案來自動化支援。
Kubernetes專案實戰訓練將於2018年8月17日在深圳開課,3天時間帶你係統掌握Kubernetes。本次培訓包括:Docker介紹、Docker映象、網路、儲存、容器安全;Kubernetes架構、設計理念、常用物件、網路、儲存、網路隔離、服務發現與負載均衡;Kubernetes核心元件、Pod、外掛、微服務、雲原生、Kubernetes Operator、叢集災備、Helm等,點選下方圖片檢視詳情。

長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。
![]()
微信掃一掃
使用小程式