作者:張家江
來自:樂得技術(ID:lede_tech)
引言
redis不是垃圾桶也不是 SUPER MAN,能力和資源都有限,不合理的使用會降低它的健康度,嚴重時甚至會引起redis抖動、阻塞等進而導致服務不可用,每一個使用redis的開發人員都應當掌握規範的開發和使用方法。本文整理出redis開發過程中七個較常出現的使用不合理的場景,並輔以案例進行分析說明。

某活動需求,每天10點對昨天參加某活動的使用者進行推送提醒。開發人員使用redis儲存每天參加活動的使用者,透過ZRANGEBYSCORE命令獲取標的使用者進行提醒,提醒完後使用ZREMRANGEBYSCORE命令從redis中清除這批使用者。某一天ZRANGEBYSCORE、ZREMRANGEBYSCORE均出現了慢日誌報警,排查發現這一天參加該活動的使用者約有5萬。
案例中使用了redis的sortedset來儲存使用者資訊,其中value是使用者的賬號、score是使用者參加活動的時間,由於ZRANGEBYSCORE和ZREMRANGEBYSCORE命令的時間複雜度是 O(log(N) + M),其中M是操作的元素個數,N是集合元素總數,本例中當使用者數量為5萬時出現慢日誌。可以透過縮小每次查詢的集合數量,可以將一天分成多段,分批次查詢,比如把查24小時範圍的使用者改為查4小時範圍的使用者,分別查6次處理即可。
Q
如果使用者參加活動的時間很集中,在某一
個時間段(比如晚18點到22點)查出來的
數量還是特別多怎麼辦?
A
可以把粒度分得更細一些比如1小時或者30分鐘,如果確定使用者參加活動集中在某個時間點,可以考慮使用ZSCAN遍歷操作並刪除。另外,對於標的時間範圍有確定的首尾元素時,還可以透過ZRANK命令查出元素的位置,透過 ZRANGE 以及ZREMRANGEBYRANK來進行查詢和刪除操作,這樣每次操作可以控制運算元量,有效避免慢日誌。
使用 sortedset、set、list、hash等集合類的O(N)操作時要評估當前元素個數的規模以及將來的增長規模,對於短期就可能變為大集合的key,要預估O(N)操作的元素數量,避免全量操作,可以使用HSCAN、SSCAN、ZSCAN進行漸進操作。集合元素數量過大在使用過程中會影響redis的實際效能,元素個數建議儘量不要超過5000,元素數量過大可考慮拆分成多個key進行處理。
合理設定過期時間

某投票功能,用於統計今日環比昨日的增長數量,開發人員使用redis儲存每天的投票數,key設計為vote_count_{date},其中{date}為當天的日期,由於沒有設定過期時間,一年以後產生了360多個key,實際在用的key始終只有2個。
該案例中,每個生成的key在2天以後都不會再使用了,可將key加上過期時間。
某統計功能,使用者會不定期的匯入一批資料進 redis,每一批資料需要在30分鐘後、1天后、3天后、7天后進行計算統計,統計結果發給使用者。開發人員使用redis的同一個sortedset儲存這些匯入的資料,每天定時任務執行計算任務。由於沒有清理,導致大量結束計算任務的廢棄資料殘留redis。
該案例中,每一批資料都有相應的生命週期,在匯入的第7天執行完最後一次計算任務生命週期結束,由於集合裡的元素不能單獨設定過期時間,可在程式碼邏輯中對最後一次使用這批資料後進行清理操作。
如果key沒有設定超時時間,會導致一直佔用記憶體。對於可以預估使用生命週期的key應當設定合理的過期時間或在最後一次操作時進行清理,避免垃圾資料殘留redis。
合理利用批操作命令
某運營需求,需要給使用者生成短鏈,短鏈由短鏈字首+短碼組成,根據短碼找到使用者對應的手機號,開發人員使用redis hash結構儲存短碼到手機號的對映。介面每次會匯入5萬個手機號。
下麵是開發人員的三種操作redis方案的偽程式碼
方案1:直接使用redis的HSET逐個設定
for(50000;)
HSET(key,短碼,手機號)
結果:失敗。redis ops飆升,同時介面響應超時
方案2:改用redis的 HMSET一次將所有元素設定到hash中
map 50000個元素
HMSET(key,map)
結果:失敗。出現redis慢日誌
方案3:依然使用 HMSET,只是每次設定500個,迴圈100次
map 500個元素
for(100;)
HMSET(key,map)
結果:成功
對於大量頻繁的hset操作可以使用 HMSET替代減少redis操作次數同時提升處理速度,但是要考慮單次請求操作的數量,避免慢日誌。
在redis使用過程中,要正視網路往返時間,合理利用批次操作命令,減少通訊時延和redis訪問頻次。redis為了減少大量小資料CMD操作的網路通訊時間開銷 RTT (Round Trip Time),支援多種批操作技術:
- MSET/HMSET等都支援一次輸入多個key,LPUSH/RPUSH/SADD等命令都支援一次輸入多個value,也要註意每次運算元量不要過多,建議控制在500個以內;
- PipeLining 樣式 可以一次輸入多個指令。redis提供一個 pipeline 的管道操作樣式,將多個指令彙總到佇列中批次執行,可以減少tcp互動產生的時間,一般情況下能夠有10%~30%不等的效能提升;
- 更快的是Lua Script樣式,還可以包含邏輯。redis內嵌了 lua 解析器,可以執行lua 腳本,指令碼可以透過eval等命令直接執行,也可以使用script load等方式上傳到伺服器端的script cache中重覆使用。
減少不必要的請求
![]()
某業務系統,當使用者進入某個頁面時會同時請求多個介面,每個介面都會校驗使用者狀態是否有效,使用者狀態存在redis裡並設定有過期時間,對於key未過期但是過期時間大於指定閾值的,需要重新設定有效時間,否則需要使用del命令刪除掉。但是部分key由於過期其實已經不存在了,所以出現部分無效del命令。使用者越多,就會有越多的無效命令。
ttl命令對於key不存在的情況會傳回-2,若key不存在則不需要再呼叫del命令,可減少無效請求。
redis的所有請求對於不存在的key都會有輸出傳回,合理利用傳回值處理,避免不必要的請求,提升業務吞吐量。
避免value設定過大
![]()
某開發人員將一個商品集合資訊序列化後用redis的字串型別儲存,使用的時候再反序列化成物件串列使用,大小超過1MB,在網路傳輸的時候由於資料比較大會觸發拆包,會降低redis的吞吐量。
數量比較多時可以考慮改用hash結構儲存,每一個field是商品id,value是該商品物件,如果數量較大可使用hscan獲取。
String型別儘量控制在10KB以內。雖然redis對單個key可以快取的物件長度能夠支援的很大,但是實際使用場合一定要合理拆分過大的快取項,1k 基本是redis效能的一個拐點。當快取項超過10k、100k、1m效能下降會特別明顯。關於吞吐量與資料大小的關係可見下麵官方網站提供的示意圖。
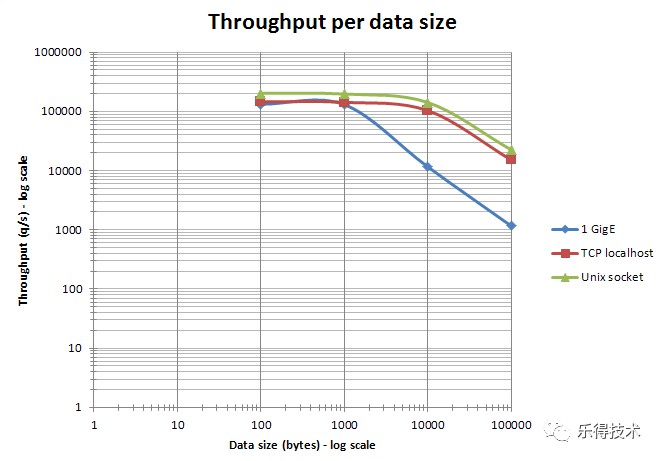
吞吐量與資料大小的關係
在局域網環境下只要傳輸的包不超過一個 MTU(乙太網下大約 1500 bytes),那麼對於 10、100、1000 bytes不同包大小的處理吞吐能力實際結果差不多。
設計規範的key名
以業務名為字首,用冒號分隔,可使用業務名:子業務名:id的結構命名,子業務下多單詞可再用下劃線分隔
舉例:活動系統-人拉人紅包活動-id,可命名為 ACTIVITY:INVITE_REDPACKET:001
保證語意的前提下,控制key的長度,當key較多時,記憶體佔用也不容忽視
不包含空格、換行、單雙引號以及其他跳脫字元
留心禁用命令
keys、monitor、flushall、flushdb應當透過redis的rename機制禁掉命令,若沒有禁用,開發人員要謹慎使用。其中flushall、flushdb會清空redis資料;keys命令可能會引起慢日誌;monitor命令在開啟的情況下會降低redis的吞吐量,根據壓測結果大概會降低redis50%的吞吐量,越多客戶端開啟該命令,吞吐量下降會越多。
keys和monitor在一些必要的情況下還是有助於排查線上問題的,建議可在重新命名後在必要情況下由redis相關負責人員在redis備機使用,monitor命令可藉助redis-faina等指令碼工具進行輔助分析,能更快排查線上ops飆升等問題。
本文整理出的幾點redis開發規範主要是涉及redis客戶端的使用部分,每個開發人員在使用redis開發過程中幾乎都會涉及到上述提到的幾個問題,需要多多留心,提高程式碼質量,提升redis的健康度。
●編號375,輸入編號直達本文
●輸入m獲取文章目錄

Web開發
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
