
需求背景:
最近誤入一個免費(daoban)資源的分享群(正經臉),群裡每天都在刷資源連結。但是大家都知道,百度雲的分享連結是很容易被河蟹的,群裡除了分享連結外,就是各種抱怨 “怎麼又失效了”,“又河蟹了…”。本著學習技術的初心,於是我就開始研究怎樣自動爬取微信群的訊息並自動轉存到自己的雲盤。

需求:
1、爬取微信群裡的百度雲分享連結
2、將資源轉存到自己的網盤
涉及:
1、正則運算式
2、如何分析cookie和api
3、selenium(webdriver)
本篇文章目錄:
1.、爬取微信群聊資訊裡的網盤資源
2、尋找並分析百度雲的轉存api
3、爬取shareid、from、filelist,傳送請求轉存到網盤
4、完整程式碼
5、參考
爬取微信群聊資訊裡的網盤資源
爬取微信群聊資訊可以用微信網頁版的api,這裡推薦一個高度封裝,使用簡單的工具:wxpy: 用 Python 玩微信

這是個不錯的工具,可以實現網頁版微信的所有功能,之前博主利用它還實現了機器人聊天功能,自己的個人賬號華麗轉變 微軟小冰 。雖然微軟還沒有公開小冰的 api ,不過我們完全可以利用這個工具的轉發功能來實現,思路很簡單,微信上領養一個小冰,把別人說的話轉發給小冰,再把小冰說的話轉發回去。

扯遠了,總之利用這個工具,就可以對微信群聊裡的資訊進行監聽,接著就是利用正則運算式把網盤連結抓取出來。具體的程式碼我就不貼了,使用起來很簡單。
尋找並分析百度雲的轉存api
這個部分才是我們的重點,首先你得有一個百度雲盤的賬號,然後登入,用瀏覽器(這裡用火狐瀏覽器做示範)開啟一個分享連結。F12開啟控制檯進行抓包。手動進行轉存操作:全選檔案->儲存到網盤->選擇路徑->確定。點選【確定】前建議先清空一下抓包記錄,這樣可以精確定位到轉存的api,這就是我們中學時學到的【控制變數法】2333。

可以看到上圖中抓到了一個帶有 “transfer” 單詞的 post 請求,這就是我們要找的轉存(transfer)api 。接下來很關鍵,就是分析它的請求頭和請求引數,以便用程式碼模擬。
https://pan.baidu.com/share/transfer?shareid=3927175953&from;=140959320&ondup;=newcopy&async;=1&bdstoken;=xxx&channel;=chunlei&clienttype;=0&web;=1&app;_id=250528&logid;=xxx點選它,再點選右邊的【Cookies】就可以看到請求頭裡的 cookie 情況。

cookie分析:
因為轉存是登入後的操作,所以需要模擬登入狀態,將與登入有關的 cookie 設定在請求頭裡。我們繼續使用【控制變數法】,先將瀏覽器裡關於百度的 cookie 全部刪除(在右上角的設定裡面,點選【隱私】,移除cookies。具體做法自己百度吧。)
然後登入,右上角進入瀏覽器設定->隱私->移除cookie,搜尋 “bai” 觀察 cookie 。這是所有跟百度相關的 cookie ,一個個刪除,刪一個掃清一次百度的頁面,直到刪除了 BDUSS ,掃清後登入退出了,所以得出結論,它就是與登入狀態有關的 cookie 。
同理,刪除掉 STOKEN 後,進行轉存操作會提示重新登入。所以,這兩個就是轉存操作所必須帶上的 cookie 。
弄清楚了 cookie 的情況,可以像下麵這樣構造請求頭。
def __init__(self,bduss,stoken,bdstoken):
self.bdstoken = bdstoken
self.essay-headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Content-Length': '161',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie': 'BDUSS=%s;STOKEN=%s;' % (bduss, stoken),
'Host': 'pan.baidu.com',
'Origin': 'https://pan.baidu.com',
'Referer': 'https://pan.baidu.com/s/1dFKSuRn?errno=0&errmsg;=Auth%20Login%20Sucess&&bduss;=&ssnerror;=0',
'User-Agent': self.pro.get_user_agent(),# 作為應對反爬蟲機制的策略,這是博主寫的一個隨機抽取user_agent的方法,你也可以自己到網上去搜集一些,寫一個隨機方法。
'X-Requested-With': 'XMLHttpRequest',
}
除了上面說到的兩個 cookie ,其他的請求頭引數可以參照手動轉存時抓包的請求頭。這兩個 cookie 預留出來做引數的原因是 cookie 都是有生存週期的,過期了需要更新,不同的賬號登入也有不同的 cookie 。
引數分析:
接下來分析引數,點選【Cookies】右邊的【Params】檢視引數情況。如下:

上面的query string(也就是?後跟的引數)裡,除了框起來的shareid、from、bdstoken需要我們填寫以外,其他的都可以不變,模擬請求的時候直接抄下來。
前兩個與分享的資源有關,bdstoken與登入的賬號有關。下麵的form data裡的兩個引數分別是資源在分享使用者的網盤的所在目錄和剛剛我們點選儲存指定的目錄。
所以,需要我們另外填寫的引數為:shareid、from、bdstoken、filelist 和 path,bdstoken 可以手動轉存抓包找到,path 根據你的需要自己定義,前提是你的網盤裡有這個路徑。其他三個需要從分享連結裡爬取,這個將在後面的【爬取shareid、from、filelist,傳送請求轉存到網盤】部分中進行講解。
搞清楚了引數的問題,可以像下麵這樣構造轉存請求的 url 。
def transfer(self,share_id,uk,filelist_str,path_t_save):# 需要填寫的引數,分別對應上圖的shareid、from、filelist 和 path
# 通用引數
ondup = "newcopy"
async = "1"
channel = "chunlei"
clienttype = "0"
web = "1"
app_id = "250528"
logid = "你的logid"
url_trans = "https://pan.baidu.com/share/transfer?shareid=%s" \
"&from;=%s" \
"&ondup;=%s" \
"&async;=%s" \
"&bdstoken;=%s" \
"&channel;=%s" \
"&clienttype;=%s" \
"&web;=%s" \
"&app;_id=%s" \
"&logid;=%s" % (share_id, uk, ondup, async, self.bdstoken, channel, clienttype, web, app_id, logid)
form_data = {
'filelist': filelist_str,
'path': path_t_save,
}
proxies = {'http': self.pro.get_ip(0, 30, u'國內')}# 為了應對反爬蟲機制,這裡用了代理,稍後做解釋
response = requests.post(url_trans, data=form_data, proxies = proxies,essay-headers=self.essay-headers)
print response.content
jsob = json.loads(response.content)
if "errno" in jsob:
return jsob["errno"]
else:
return None
爬取shareid、from、filelist,傳送請求轉存到網盤
https://pan.baidu.com/s/1jImSOXg
以上面這個資源連結為例(隨時可能被河蟹,但是沒關係,其他連結的結構也是一樣的),我們先用瀏覽器手動訪問,F12 開啟控制檯先分析一下原始碼,看看我們要的資源資訊在什麼地方。控制檯有搜尋功能,直接搜 “shareid”。
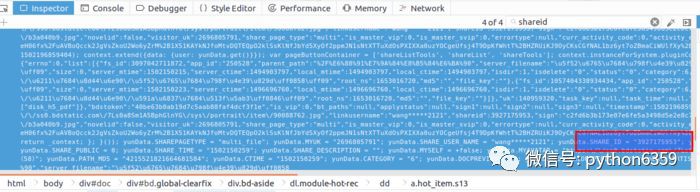
定位到4個shareid,前三個與該資源無關,是其他分享資源,最後一個定位到該 html 檔案的最後一個標簽塊裡。雙擊後可以看到格式化後的 js 程式碼,可以發現我們要的資訊全都在裡邊。如下節選:
yunData.SHAREPAGETYPE = "multi_file";
yunData.MYUK = "";
yunData.SHARE_USER_NAME = "wang*****2121";
yunData.SHARE_ID = "3927175953";
yunData.SIGN = "7f166e9b5cf54486074ccce2fc0548e8aa50bdfb";
yunData.sign = "7f166e9b5cf54486074ccce2fc0548e8aa50bdfb";
yunData.TIMESTAMP = "1502175170";
yunData.SHARE_UK = "140959320";
yunData.SHARE_PUBLIC = 0;
yunData.SHARE_TIME = "1502150259";
yunData.SHARE_DESCRIPTION = "";
yunData.MYSELF = +false;
yunData.MYAVATAR = "";
yunData.NOVELID = "";
yunData.FS_ID = "3097042711872";
yunData.FILENAME = "歸來的福丹芝(58)";
yunData.PATH = "\/我的資源\/歸來的福丹芝(58)";
yunData.PATH_MD5 = "4215521821664681584";
yunData.CTIME = "1502150259";
yunData.CATEGORY = "6";
yunData.DOCPREVIEW = "";
yunData.IS_BAIDUSPIDER = "";
yunData.ARTISTNAME = "";
yunData.ALBUMTITLE = "";
yunData.TRACKTITLE = "";
yunData.FILEINFO = [{"fs_id":3097042711872,"app_id":"250528","parent_path":"%2F%E6%88%91%E7%9A%84%E8%B5%84%E6%BA%90","server_filename":"歸來的福丹芝(58)","size":0,"server_mtime":1502150215,"server_ctime":1494903797,"local_mtime":1494903797,"local_ctime":1494903797,"isdir":1,"isdelete":"0","status":"0","category":6,"share":"0","path_md5":"4215521821664681584","delete_fs_id":"0","extent_int3":"0","extent_tinyint1":"0","extent_tinyint2":"0","extent_tinyint3":"0","extent_tinyint4":"0","path":"\/我的資源\/歸來的福丹芝(58)","root_ns":1653016720,"md5":"","file_key":""},{"fs_id":1057404338934434,"app_id":"250528","parent_path":"%2F%E6%88%91%E7%9A%84%E8%B5%84%E6%BA%90","server_filename":"多樣的兒媳(46)","size":0,"server_mtime":1502150223,"server_ctime":1496696760,"local_mtime":1496696760,"local_ctime":1496696760,"isdir":1,"isdelete":"0","status":"0","category":6,"share":"0","path_md5":"5972282562760833248","delete_fs_id":"0","extent_int3":"0","extent_tinyint1":"0","extent_tinyint2":"0","extent_tinyint3":"0","extent_tinyint4":"0","path":"\/我的資源\/多樣的兒媳(46)","root_ns":1653016720,"md5":"","file_key":""}];
可以看到這兩行
yunData.SHARE_ID = "3927175953";
yunData.SHARE_UK = "140959320"; // 經過對比,這就是我們要的 "from"
yunData.PATH 只指向了一個路徑資訊,完整的 filelist 可以從 yunData.FILEINFO 裡提取,它是一個 json ,list 裡的資訊是Unicode編碼的,所以在控制檯看不到中文,用Python程式碼訪問並獲取輸出一下就可以了。
直接用request請求會收穫 404 錯誤,可能是需要構造請求頭引數,不能直接請求,這裡博主為了節省時間,直接用selenium的webdriver來get了兩次,就收到了傳回信息。第一次get沒有任何 cookie ,但是baidu 會給你傳回一個BAIDUID ,在第二次 get 就可以正常訪問了。
yunData.FILEINFO 結構如下,你可以將它複製貼上到json.cn裡,可以看得更清晰。
[{"fs_id":3097042711872,"app_id":"250528","parent_path":"%2F%E6%88%91%E7%9A%84%E8%B5%84%E6%BA%90","server_filename":"歸來的福丹芝(58)","size":0,"server_mtime":1502150215,"server_ctime":1494903797,"local_mtime":1494903797,"local_ctime":1494903797,"isdir":1,"isdelete":"0","status":"0","category":6,"share":"0","path_md5":"4215521821664681584","delete_fs_id":"0","extent_int3":"0","extent_tinyint1":"0","extent_tinyint2":"0","extent_tinyint3":"0","extent_tinyint4":"0","path":"\/我的資源\/歸來的福丹芝(58)","root_ns":1653016720,"md5":"","file_key":""},{"fs_id":1057404338934434,"app_id":"250528","parent_path":"%2F%E6%88%91%E7%9A%84%E8%B5%84%E6%BA%90","server_filename":"多樣的兒媳(46)","size":0,"server_mtime":1502150223,"server_ctime":1496696760,"local_mtime":1496696760,"local_ctime":1496696760,"isdir":1,"isdelete":"0","status":"0","category":6,"share":"0","path_md5":"5972282562760833248","delete_fs_id":"0","extent_int3":"0","extent_tinyint1":"0","extent_tinyint2":"0","extent_tinyint3":"0","extent_tinyint4":"0","path":"\/我的資源\/多樣的兒媳(46)","root_ns":1653016720,"md5":"","file_key":""}]

清楚了這三個引數的位置,我們就可以用正則運算式進行提取了。程式碼如下:
from wechat_robot.business import proxy_mine # 這是我自己的代理類,測試時可以先用本機ip
pro = proxy_mine.Proxy()
url = "https://pan.baidu.com/s/1jImSOXg"
driver = webdriver.Chrome()
print u"初始化代理..."
driver = pro.give_proxy_driver(driver)
def get_file_info(url):
driver.get(url)
time.sleep(1)
driver.get(url)
script_list = driver.find_elements_by_xpath("//body/script")
innerHTML = script_list[-1].get_attribute("innerHTML")# 獲取最後一個script的innerHTML
pattern = 'yunData.SHARE_ID = "(.*?)"[\s\S]*yunData.SHARE_UK = "(.*?)"[\s\S]*yunData.FILEINFO = (.*?);[\s\S]*' # [\s\S]*可以匹配包括換行的所有字元,\s表示空格,\S表示非空格字元
srch_ob = re.search(pattern, innerHTML)
share_id = srch_ob.group(1)
share_uk = srch_ob.group(2)
file_info_jsls = json.loads(srch_ob.group(3))# 解析json
path_list = []
for file_info in file_info_jsls:
path_list.append(file_info['path'])
return share_id,share_uk,path_list
try:
print u"傳送連線請求..."
share_id,share_uk,path_list = get_file_info(url)
except:
print u"連結失效了,沒有獲取到fileinfo..."
else:
print share_id
print share_uk
print path_list
爬取到了這三個引數,就可以呼叫之前的 transfer 方法進行轉存了。
完整程式碼
# -*- coding:utf-8 -*-
import requests
import json
import time
import re
from selenium import webdriver
from wechat_robot.business import proxy_mine
class BaiduYunTransfer:
essay-headers = None
bdstoken = None
pro = proxy_mine.Proxy()
def __init__(self,bduss,stoken,bdstoken):
self.bdstoken = bdstoken
self.essay-headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Connection': 'keep-alive',
'Content-Length': '161',
'Content-Type': 'application/x-www-form-urlencoded; charset=UTF-8',
'Cookie': 'BDUSS=%s;STOKEN=%s;' % (bduss, stoken),
'Host': 'pan.baidu.com',
'Origin': 'https://pan.baidu.com',
'Referer': 'https://pan.baidu.com/s/1dFKSuRn?errno=0&errmsg;=Auth%20Login%20Sucess&&bduss;=&ssnerror;=0',
'User-Agent': self.pro.get_user_agent(),
'X-Requested-With': 'XMLHttpRequest',
}
def transfer(self,share_id,uk,filelist_str,path_t_save):
# 通用引數
ondup = "newcopy"
async = "1"
channel = "chunlei"
clienttype = "0"
web = "1"
app_id = "250528"
logid = "你的logid"
url_trans = "https://pan.baidu.com/share/transfer?shareid=%s" \
"&from;=%s" \
"&ondup;=%s" \
"&async;=%s" \
"&bdstoken;=%s" \
"&channel;=%s" \
"&clienttype;=%s" \
"&web;=%s" \
"&app;_id=%s" \
"&logid;=%s" % (share_id, uk, ondup, async, self.bdstoken, channel, clienttype, web, app_id, logid)
form_data = {
'filelist': filelist_str,
'path': path_t_save,
}
proxies = {'http': self.pro.get_ip(0, 30, u'國內')}
response = requests.post(url_trans, data=form_data, proxies = proxies,essay-headers=self.essay-headers)
print response.content
jsob = json.loads(response.content)
if "errno" in jsob:
return jsob["errno"]
else:
return None
def get_file_info(self,url):
driver = webdriver.Chrome()
print u"初始化代理..."
driver = self.pro.give_proxy_driver(driver)
print u"嘗試開啟"
driver.get(url)
time.sleep(1)
print u"正式開啟連結"
driver.get(url)
print u"成功獲取並載入頁面"
script_list = driver.find_elements_by_xpath("//body/script")
innerHTML = script_list[-1].get_attribute("innerHTML")
pattern = 'yunData.SHARE_ID = "(.*?)"[\s\S]*yunData.SHARE_UK = "(.*?)"[\s\S]*yunData.FILEINFO = (.*?);[\s\S]*' # [\s\S]*可以匹配包括換行的所有字元,\s表示空格,\S表示非空格字元
srch_ob = re.search(pattern, innerHTML)
share_id = srch_ob.group(1)
share_uk = srch_ob.group(2)
file_info_jsls = json.loads(srch_ob.group(3))
path_list_str = u'['
for file_info in file_info_jsls:
path_list_str += u'"' + file_info['path'] + u'",'
path_list_str = path_list_str[:-1]
path_list_str += u']'
return share_id, share_uk, path_list_str
def transfer_url(self,url_bdy,path_t_save):
try:
print u"傳送連線請求..."
share_id, share_uk, path_list = self.get_file_info(url_bdy)
except:
print u"連結失效了,沒有獲取到fileinfo..."
else:
error_code = self.transfer(share_id, share_uk, path_list, path_t_save)
if error_code == 0:
print u"轉存成功!"
else:
print u"轉存失敗了,錯誤程式碼:" + str(error_code)
bduss = '你的BDUSS'
stoken = '你的STOKEN'
bdstoken = "你的bdstoken"
bdy_trans = BaiduYunTransfer(bduss,stoken,bdstoken)
url_src = "https://pan.baidu.com/s/1jImSOXg"
path = u"/電影"
bdy_trans.transfer_url(url_src,path)

作者:王雨城
源自:https://www.jianshu.com/p/56f0c07e0ecb