
第一步:收集和清洗資料
資料連結:https://grouplens.org/datasets/movielens/
下載檔案:ml-latest-small

import pandas as pd
import numpy as np
import tensorflow as tf
匯入ratings.csv檔案
ratings_df = pd.read_csv('./ml-latest-small/ratings.csv')
ratings_df.tail()
#tail命令用於輸入檔案中的尾部內容。tail命令預設在螢幕上顯示指定檔案的末尾5行。
結果:
| userId | movieId | rating | timestamp | |
|---|---|---|---|---|
| 99999 | 671 | 6268 | 2.5 | 1065579370 |
| 100000 | 671 | 6269 | 4.0 | 1065149201 |
| 100001 | 671 | 6365 | 4.0 | 1070940363 |
| 100002 | 671 | 6385 | 2.5 | 1070979663 |
| 100003 | 671 | 6565 | 3.5 | 1074784724 |
匯入movies.csv檔案
movies_df = pd.read_csv('./ml-latest-small/movies.csv')
movies_df.tail()
結果:
| movieId | title | genres | |
|---|---|---|---|
| 9120 | 162672 | Mohenjo Daro (2016) | Adventure|Drama|Romance |
| 9121 | 163056 | Shin Godzilla (2016) | Action|Adventure|Fantasy|Sci-Fi |
| 9122 | 163949 | The Beatles: Eight Days a Week – The Touring Y… | Documentary |
| 9123 | 164977 | The Gay Desperado (1936) | Comedy |
| 9124 | 164979 | Women of ’69, Unboxed | Documentary |
將movies_df中的movieId替換為行號
movies_df['movieRow'] = movies_df.index
#生成一列‘movieRow’,等於索引值index
movies_df.tail()
結果:
| movieId | title | genres | movieRow | |
|---|---|---|---|---|
| 9120 | 162672 | Mohenjo Daro (2016) | Adventure|Drama|Romance | 9120 |
| 9121 | 163056 | Shin Godzilla (2016) | Action|Adventure|Fantasy|Sci-Fi | 9121 |
| 9122 | 163949 | The Beatles: Eight Days a Week – The Touring Y… | Documentary | 9122 |
| 9123 | 164977 | The Gay Desperado (1936) | Comedy | 9123 |
| 9124 | 164979 | Women of ’69, Unboxed | Documentary | 9124 |
篩選movies_df中的特徵
movies_df = movies_df[['movieRow','movieId','title']]
#篩選三列出來
movies_df.to_csv('./ml-latest-small/moviesProcessed.csv', index=False, essay-header=True, encoding='utf-8')
#生成一個新的檔案moviesProcessed.csv
movies_df.tail()
結果:
| movieRow | movieId | title | |
|---|---|---|---|
| 9120 | 9120 | 162672 | Mohenjo Daro (2016) |
| 9121 | 9121 | 163056 | Shin Godzilla (2016) |
| 9122 | 9122 | 163949 | The Beatles: Eight Days a Week – The Touring Y… |
| 9123 | 9123 | 164977 | The Gay Desperado (1936) |
| 9124 | 9124 | 164979 | Women of ’69, Unboxed |
根據movieId,合併rating_df和movie_df
ratings_df = pd.merge(ratings_df, movies_df, on='movieId')
ratings_df.head()
結果:
| userId | movieId | rating | timestamp | movieRow | title | |
|---|---|---|---|---|---|---|
| 0 | 1 | 31 | 2.5 | 1260759144 | 30 | Dangerous Minds (1995) |
| 1 | 7 | 31 | 3.0 | 851868750 | 30 | Dangerous Minds (1995) |
| 2 | 31 | 31 | 4.0 | 1273541953 | 30 | Dangerous Minds (1995) |
| 3 | 32 | 31 | 4.0 | 834828440 | 30 | Dangerous Minds (1995) |
| 4 | 36 | 31 | 3.0 | 847057202 | 30 | Dangerous Minds (1995) |
篩選ratings_df中的特徵
ratings_df = ratings_df[['userId','movieRow','rating']]
#篩選出三列
ratings_df.to_csv('./ml-latest-small/ratingsProcessed.csv', index=False, essay-header=True, encoding='utf-8')
#匯出一個新的檔案ratingsProcessed.csv
ratings_df.head()
結果:
| userId | movieRow | rating | |
|---|---|---|---|
| 0 | 1 | 30 | 2.5 |
| 1 | 7 | 30 | 3.0 |
| 2 | 31 | 30 | 4.0 |
| 3 | 32 | 30 | 4.0 |
| 4 | 36 | 30 | 3.0 |
第二步:建立電影評分矩陣rating和評分紀錄矩陣record
userNo = ratings_df['userId'].max() + 1
#userNo的最大值
movieNo = ratings_df['movieRow'].max() + 1
#movieNo的最大值
rating = np.zeros((movieNo,userNo))
#建立一個值都是0的資料
flag = 0
ratings_df_length = np.shape(ratings_df)[0]
#檢視矩陣ratings_df的第一維度是多少
for index,row in ratings_df.iterrows():
#interrows(),對錶格ratings_df進行遍歷
rating[int(row['movieRow']),int(row['userId'])] = row['rating']
#將ratings_df表裡的'movieRow'和'userId'列,填上row的‘評分’
flag += 1
record = rating > 0
record
record = np.array(record, dtype = int)
#更改資料型別,0表示使用者沒有對電影評分,1表示使用者已經對電影評分
record
結果:
array([[0, 0, 0, ..., 0, 1, 1],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
...,
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0],
[0, 0, 0, ..., 0, 0, 0]])
第三步:構建模型
def normalizeRatings(rating, record):
m, n =rating.shape
#m代表電影數量,n代表使用者數量
rating_mean = np.zeros((m,1))
#每部電影的平均得分
rating_norm = np.zeros((m,n))
#處理過的評分
for i in range(m):
idx = record[i,:] !=0
#每部電影的評分,[i,:]表示每一行的所有列
rating_mean[i] = np.mean(rating[i,idx])
#第i行,評過份idx的使用者的平均得分;
#np.mean() 對所有元素求均值
rating_norm[i,idx] -= rating_mean[i]
#rating_norm = 原始得分-平均得分
return rating_norm, rating_mean
rating_norm, rating_mean = normalizeRatings(rating, record)
結果:
/root/anaconda2/envs/python3/lib/python3.6/site-packages/numpy/core/fromnumeric.py:2957: RuntimeWarning: Mean of empty slice.
out=out, **kwargs)
/root/anaconda2/envs/python3/lib/python3.6/site-packages/numpy/core/_methods.py:80: RuntimeWarning: invalid value encountered in double_scalars
ret = ret.dtype.type(ret / rcount)
註:如果資料出現較多的NaNN,對後面的運算影響較大
rating_norm =np.nan_to_num(rating_norm)
#對值為NaNN進行處理,改成數值0
rating_norm
結果:
array([[ 0. , 0. , 0. , ..., 0. ,
-3.87246964, -3.87246964],
[ 0. , 0. , 0. , ..., 0. ,
0. , 0. ],
[ 0. , 0. , 0. , ..., 0. ,
0. , 0. ],
...,
[ 0. , 0. , 0. , ..., 0. ,
0. , 0. ],
[ 0. , 0. , 0. , ..., 0. ,
0. , 0. ],
[ 0. , 0. , 0. , ..., 0. ,
0. , 0. ]])
–
rating_mean =np.nan_to_num(rating_mean)
#對值為NaNN進行處理,改成數值0
rating_mean
結果:
array([[3.87246964],
[3.40186916],
[3.16101695],
...,
[3. ],
[0. ],
[5. ]])
構建模型
num_features = 10
X_parameters = tf.Variable(tf.random_normal([movieNo, num_features],stddev = 0.35))
Theta_parameters = tf.Variable(tf.random_normal([userNo, num_features],stddev = 0.35))
#tf.Variables()初始化變數
#tf.random_normal()函式用於從服從指定正太分佈的數值中取出指定個數的值,mean: 正態分佈的均值。stddev: 正態分佈的標準差。dtype: 輸出的型別
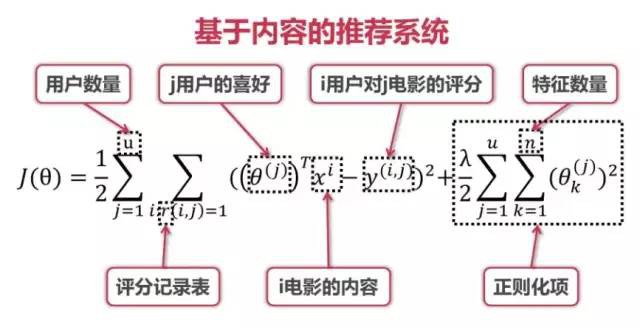
loss = 1/2 * tf.reduce_sum(((tf.matmul(X_parameters, Theta_parameters, transpose_b = True) - rating_norm) * record) ** 2) + 1/2 * (tf.reduce_sum(X_parameters ** 2) + tf.reduce_sum(Theta_parameters ** 2))
#基於內容的推薦演演算法模型
# 函式解釋:
# reduce_sum() 就是求和,reduce_sum( input_tensor, axis=None, keep_dims=False, name=None, reduction_indices=None)
# reduce_sum() 引數解釋:
# 1) input_tensor:輸入的張量。
# 2) axis:沿著哪個維度求和。對於二維的input_tensor張量,0表示按列求和,1表示按行求和,[0, 1]表示先按列求和再按行求和。
# 3) keep_dims:預設值為Flase,表示預設要降維。若設為True,則不降維。
# 4) name:名字。
# 5) reduction_indices:預設值是None,即把input_tensor降到 0維,也就是一個數。對於2維input_tensor,reduction_indices=0時,按列;reduction_indices=1時,按行。
# 6) 註意,reduction_indices與axis不能同時設定。
# tf.matmul(a,b),將矩陣 a 乘以矩陣 b,生成a * b
# tf.matmul(a,b)引數解釋:
# 1) a:型別為 float16,float32,float64,int32,complex64,complex128 和 rank > 1的張量。
# 2) b:與 a 具有相同型別和 rank。
# 3) transpose_a:如果 True,a 在乘法之前轉置。
# 4) transpose_b:如果 True,b 在乘法之前轉置。
# 5) adjoint_a:如果 True,a 在乘法之前共軛和轉置。
# 6) adjoint_b:如果 True,b 在乘法之前共軛和轉置。
# 7) a_is_sparse:如果 True,a 被視為稀疏矩陣。
# 8) b_is_sparse:如果 True,b 被視為稀疏矩陣。
# 9) name:操作名稱(可選)
最佳化演演算法
optimizer = tf.train.AdamOptimizer(1e-4)
# https://blog.csdn.net/lenbow/article/details/52218551
train = optimizer.minimize(loss)
# Optimizer.minimize對一個損失變數基本上做兩件事
# 它計算相對於模型引數的損失梯度。
# 然後應用計算出的梯度來更新變數。
第四步:訓練模型
# tf.summary的用法 https://www.cnblogs.com/lyc-seu/p/8647792.html
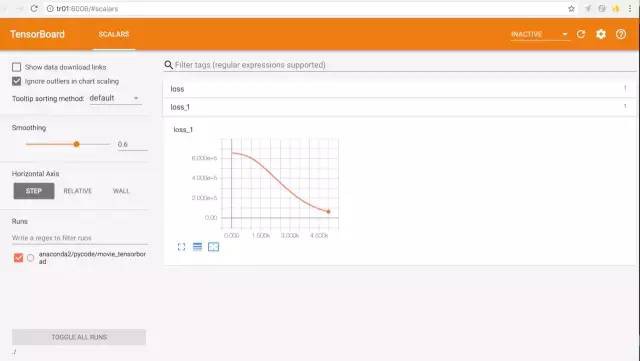
tf.summary.scalar('loss',loss)
#用來顯示標量資訊
結果:
summaryMerged = tf.summary.merge_all()
#merge_all 可以將所有summary全部儲存到磁碟,以便tensorboard顯示。
filename = './movie_tensorborad'
writer = tf.summary.FileWriter(filename)
#指定一個檔案用來儲存圖。
sess = tf.Session()
#https://www.cnblogs.com/wuzhitj/p/6648610.html
init = tf.global_variables_initializer()
sess.run(init)
#執行
for i in range(5000):
_, movie_summary = sess.run([train, summaryMerged])
# 把訓練的結果summaryMerged存在movie裡
writer.add_summary(movie_summary, i)
# 把訓練的結果儲存下來
檢視訓練結果: 在終端輸入 tensorboard –logir=./

第五步:評估模型
Current_X_parameters, Current_Theta_parameters = sess.run([X_parameters, Theta_parameters])
# Current_X_parameters為使用者內容矩陣,Current_Theta_parameters使用者喜好矩陣
predicts = np.dot(Current_X_parameters,Current_Theta_parameters.T) + rating_mean
# dot函式是np中的矩陣乘法,np.dot(x,y) 等價於 x.dot(y)
errors = np.sqrt(np.sum((predicts - rating)**2))
# sqrt(arr) ,計算各元素的平方根
errors
結果:4037.9002717628305
第六步:構建完整的電影推薦系統
user_id = input('您要想哪位使用者進行推薦?請輸入使用者編號:')
sortedResult = predicts[:, int(user_id)].argsort()[::-1]
# argsort()函式傳回的是陣列值從小到大的索引值; argsort()[::-1] 傳回的是陣列值從大到小的索引值
idx = 0
print('為該使用者推薦的評分最高的20部電影是:'.center(80,'='))
# center() 傳回一個原字串居中,並使用空格填充至長度 width 的新字串。預設填充字元為空格。
for i in sortedResult:
print('評分: %.2f, 電影名: %s' % (predicts[i,int(user_id)],movies_df.iloc[i]['title']))
# .iloc的用法:https://www.cnblogs.com/harvey888/p/6006200.html
idx += 1
if idx == 20:break
結果:
您要想哪位使用者進行推薦?請輸入使用者編號:123
==============================為該使用者推薦的評分最高的20部電影是:===============================
評分: 5.03, 電影名: Fireworks Wednesday (Chaharshanbe-soori) (2006)
評分: 4.88, 電影名: Woman on the Beach (Haebyeonui yeoin) (2006)
評分: 4.73, 電影名: Mummy's Ghost, The (1944)
評分: 4.66, 電影名: Maborosi (Maboroshi no hikari) (1995)
評分: 4.63, 電影名: Boiling Point (1993)
評分: 4.60, 電影名: Mala Noche (1985)
評分: 4.49, 電影名: All-Star Superman (2011)
評分: 4.47, 電影名: Bill Hicks: Relentless (1992)
評分: 4.45, 電影名: Something Borrowed (2011)
評分: 4.37, 電影名: Box of Moon Light (1996)
評分: 4.37, 電影名: Kwaidan (Kaidan) (1964)
評分: 4.35, 電影名: Sacrifice, The (Offret - Sacraficatio) (1986)
評分: 4.29, 電影名: Hotel de Love (1996)
評分: 4.27, 電影名: Aria (1987)
評分: 4.23, 電影名: Querelle (1982)
評分: 4.22, 電影名: Rocky VI (1986)
評分: 4.21, 電影名: Little Lord Fauntleroy (1936)
評分: 4.19, 電影名: Hardcore (1979)
評分: 4.16, 電影名: Three of Hearts (1993)
評分: 4.15, 電影名: White Stripes Under Great White Northern Lights, The (2009)
作者:Kervin_Chan
源自:https://juejin.im/post/5afbfe316fb9a07aa5427d73#heading-5
