點選上方“Java技術驛站”,選擇“置頂公眾號”。
有內涵、有價值的文章第一時間送達!
這篇文章源於【死磕Sharding-jdbc】—–重寫的遺留問題,相關sharding-jdbc原始碼如下:
private void appendLimitRowCount(final SQLBuilder sqlBuilder, final RowCountToken rowCountToken, final int count, final List<SQLToken> sqlTokens, final boolean isRewrite) {
SelectStatement selectStatement = (SelectStatement) sqlStatement;
Limit limit = selectStatement.getLimit();
if (!isRewrite) {
... ...
} else if ((!selectStatement.getGroupByItems().isEmpty() || !selectStatement.getAggregationSelectItems().isEmpty()) && !selectStatement.isSameGroupByAndOrderByItems()) {
// 如果要重寫sql中的limit的話,且sql中有group by或者有group by & order by,例如"select user_id, sum(score) from t_order group by user_id order by sum(score) desc limit 5",那麼limit 5需要重寫為limit Integer.MAX_VALUE,原因接下來分析
sqlBuilder.appendLiterals(String.valueOf(Integer.MAX_VALUE));
} else {
... ...
}
... ...
}
構造資料
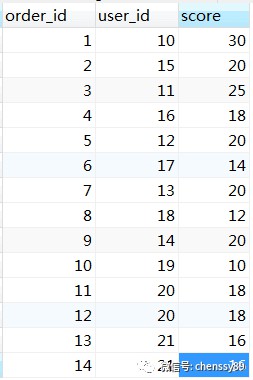
為瞭解釋為什麼limit rowCount中的rowCount需要重寫為Integer.MAX_VALUE,需要先構造一些資料,如下圖所示:

如果不分庫分表的話,資料如下圖所示:
執行SQL
假定執行如下SQL:
select user_id, sum(score) from t_order group by user_id order by sum(score) desc limit 5;
結果如下所示:

假定 selectuser_id,sum(score)fromt_ordergroupbyuser_id orderbysum(score)desc limit5;這個SQL不重寫為 limit0,Integer.MAX_VALUE,那麼 t_order_0和 t_order_1的結果分別如下; t_order_0的結果:
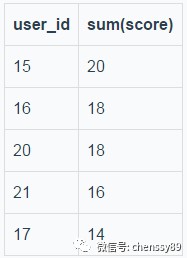
t_order_1的結果:
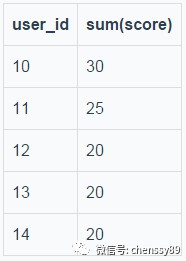
路由到兩個表的執行結果歸併後的結果如下:

分析
根據執行結果可知,主要差異在於,真實結果有userid為20,21的資料。我們在看一下 t_order_0和 t_order_1兩個分表中這兩個userid的資料有什麼特殊之處:
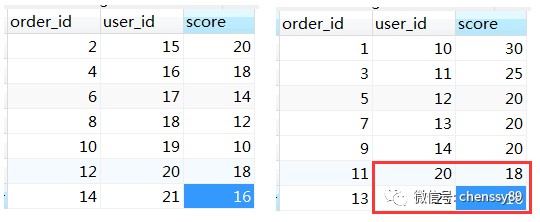
在 t_order_1這個分表中,由於userid為20,21的score值在TOP 5以外。但是合併 t_order_0和 t_order_1兩個分表的結果,userid為20的sum(score)能夠排在第一(18+18=36);所以,如果group by這類的SQL不重寫為 limit0,Integer.MAX_VALUE的話,會導致結果有誤。所以sharding-jdbc的原始碼必須要這樣重寫,沒有其他辦法!
延伸
事實上不只是sharding-jdbc,任何有sharding概念的中介軟體例如es,都要這麼處理,因為sharding後資料處理的流程幾乎都要經過解析->重寫->路由->執行->結果歸併這幾個階段;
END

