
專欄介紹:PaddleFluid 是用來讓使用者像 PyTorch 和 Tensorflow Eager Execution 一樣執行程式。在這些系統中,不再有模型這個概念,應用也不再包含一個用於描述 Operator 圖或者一系列層的符號描述,而是像通用程式那樣描述訓練或者預測的過程。
本專欄將推出一系列技術文章,從框架的概念、使用上對比分析 TensorFlow 和 Paddle Fluid,為對 PaddlePaddle 感興趣的同學提供一些指導。
前四篇文章我們介紹了 PaddleFluid 和 TensorFlow 的設計原理基本使用概念,分別透過在兩個平臺上實現完全相同的模型完成影象分類,語言模型和序列標註三個任務,瞭解我們的使用經驗如何在兩個平臺之間遷移,以此來瞭解非序列模型和序列模型在兩個平臺之上設計和使用的差異。
到目前為止我們依然遺留了一個對在單機上使用深度學習框架來說最重要 的問題:如何利用 GPU, 也包括利用多個 GPU 進行訓練。深度學習模型的訓練往往非常耗時,在較大資料集上訓練或是訓練複雜模型往往會藉助於 GPU 強大的平行計算能力。 如何能夠讓模型執行在單個/多個 GPU 上,充分利用多個 GPU 卡的計算能力,且無需關註框架在多裝置、多卡通訊實現上的細節是這一篇要解決的問題。
這一篇我們以 RNN 語言模型為例。RNN 語言模型在 第三篇已經介紹過,這一篇我們維持原有的模型結構不變,在以下兩處對第三節原有的例子進行改建:
1. 為 PaddleFluid 和 TensorFlow 模型新增上多 GPU 卡執行的支援。
2. 使用 TensorFlow 的 dataset API 為 TensorFlow 的 RNN 語言模型重寫資料讀取 部分,以提高 I/O 效率。
請註意,這一篇我們主要關於 如何利用多 GPU 卡進行訓練,請儘量在有多 塊 GPU 卡的機器上執行本節示例。
如何使用程式碼
本篇文章配套有完整可執行的程式碼, 請隨時從 github [1] 上獲取最新程式碼。程式碼包括以下幾個檔案:

在執行訓練任務前,請首先進入 data 檔案夾,在終端執行下麵的命令進行訓練資料下載以及預處理。
sh download.sh在終端執行以下命令便可以使用預設結構和預設引數執行 PaddleFluid 訓練序列標註模型。
python train_fluid_model.py在終端執行以下命令便可以使用預設結構和預設引數執行 TensorFlow 訓練序列標註模型。
python train_tf_model.py資料並行與模型並行
這一篇我們僅考慮單機多裝置情況,暫不考慮網路中的不同計算機。當我們單機上有多種計算裝置(包括 CPU,多塊不同的 GPU 卡),我們希望能夠充分利用這些裝置一起完成訓練任務,常用的並行方式分為三種:
模型並行( model parallelism ):不同裝置(GPU/CPU 等)負責網路模型的不同部分 例如,神經網路模型的不同網路層被分配到不同的裝置,或者同一層內部的不同引數被分配到不同裝置。
-
每個裝置都只有一部分 模型;不同裝置之間會產生通訊開銷 ;
-
神經網路的計算本身有一定的計算依賴,如果計算本身存在依賴無法並行進行,不同裝置之間可能會產生等待。
資料並行( data parallelism ):不同的裝置有同一個模型的多個副本,每個裝置分配到不同的資料,然後將所有機器的計算結果按照某種方式合併。
-
每個計算裝置都有一份完整的模型各自計算,指定某個裝置作為 controller,將多個裝置的計算結果進行合併;
-
在神經網路中,通常需要合併的是多個裝置計算的梯度,梯度合併後再進行 clipping,計算正則,計算更新量,更新引數等步驟;
-
最大化計算效率的關鍵是盡可能降低序列避免計算裝置的等待。
混合併行(Hybrid parallelism):既有模型並行,又有資料並行。
模型並行往往使用在模型大到單個計算裝置已經無法儲存整個模型(包括模型本身和計算過程中產生的中間結果)的場景,或是模型在計算上天然就存在多個 沒有強計算依賴的部分,那麼很自然的可以將這些沒有計算依賴的部分放在不同裝置上並行地進行計算。
然而,隨著計算裝置的不斷增多,模型並行較難以一種通用的可擴充套件的方法達到接近線性加速的效果。一方面如何重疊(overlap)計算開銷與跨裝置通訊開銷依賴於對系統硬體豐富的知識和經驗,另一方面神經網路計算的依賴性 會讓模型的拆分隨著裝置的增加越發困難。
資料並行中每一個裝置都維護了完整的模型,與模型並行相比往往會耗費更多的儲存空間。但資料並行的優點是:通用性很好,適用於所有可能的神經網路模型結構。同樣地,隨著裝置數目的增加通訊代價也會越來越高,一般情況下在 2~8 卡時依然可以做到接近線性加速比。
需要註意的是,隨著越來越多裝置的加入,資料並行會導致 batch size 增大,一個 epoch 內引數更新次數減少,往往都需要對學習率,學習率 decay 進行再調參,否則可能會引起學習效果的下降。
鑒於在使用中的通用性和有效性,這一篇中我們主要介紹更加通用的資料並行方法。非常籠統的,資料並行遵從一下的流程,其中一個 | 代表一個計算裝置:
| 1. 將模型引數複製到不同的裝置
| 2. 對輸入資料均勻切分到不同的計算裝置
|||| 3. 多個裝置並行進行前向計算
|||| 4. 多個裝置形象進行反向計算
| 5. 多個裝置計算的梯度在主卡合併
| 6. 計算引數更新量,更新引數
| to 1
PaddleFluid使用多GPU卡進行訓練
在 PaddleFluid 中使用多個 GPU 卡以資料並行的方式訓練需要引入 parallel_do 原語。顧名思義, parallel_do 會負責資料的切分,在多個裝置上並行地執行一段相同的計算,最後合併計算結果。
與 ParallelDo 函式功能相近的函式還有 ParallelExecutor,大家也可以自行嘗試一下。ParallelExecutor 的具體使用方式可以參考 API 檔案:
http://www.paddlepaddle.org/docs/develop/api/fluid/en/executor.html
圖 1 是 parallel_do 的原理示意圖:
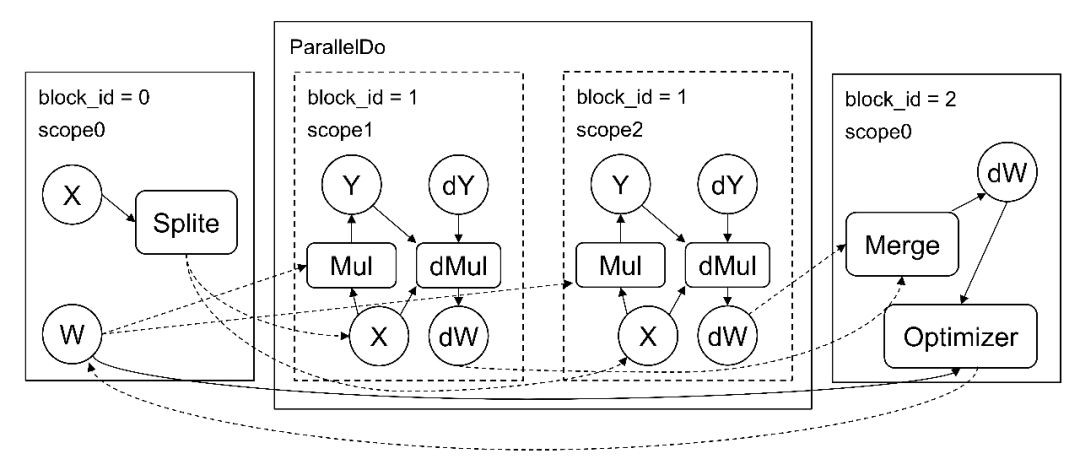
▲ 圖1. PaddleFluid中的Parallel do
下麵我們來看看如何使用 parallel_do 讓我們在第三篇中實現的 RNN LM 可在多個 GPU 上訓練 ,下麵是核心程式碼片段,完整程式碼請參考 rnnlm_fluid.py。
places = fluid.layers.get_places()
pd = fluid.layers.ParallelDo(places)
with pd.do():
word_ = pd.read_input(word)
lbl_ = pd.read_input(lbl)
prediction, cost = self.__network(word_, lbl_)
pd.write_output(cost)
pd.write_output(prediction)
cost, prediction = pd()
avg_cost = fluid.layers.mean(x=cost)呼叫 places = fluid.layers.get_places() 獲取所有可用的計算裝置 。可以透過設定 CUDA_VISIBLE_DEVICES 來控制可見 GPU 的資料。
pd = fluid.layers.ParallelDo(places) 指定將在 那些裝置上並行地執行。
parallel_do 會構建一段 context,在其中定義要並行執行的計算,呼叫 pd.read_input 切分輸入資料,在 parallel_do 的 context 之外呼叫 pd() 獲取合併後的最終計算結果。
with pd.do():
x_ = pd.read_input(x) # 切分輸入資料 x
y_ = pd.read_input(y) # 切分輸入資料 y
# 定義網路
cost = network(x_, y_)
pd.write_output(cost)
cost = pd() # 獲取合併後的計算結果TensorFlow中使用多GPU卡進行訓練
在 TensorFlow 中,透過呼叫 with tf.device() 建立一段 device context,在這段 context 中定義所需的計算,那麼這 些計算將執行在指定的裝置上。
TensorFlow 中實現多卡資料並行有多種方法,常用的包括單機 ParameterServer 樣式;Tower 樣式 [2],甚至也 可以使用最新的 nccl [3] all reduce 系列 op 來實現梯度的聚合。這裡我們以 Tower 樣式為基礎,介紹一種簡單易用的多 GPU 上的資料並行方式。下麵是核心程式碼片段,完整程式碼請參考 rnnlm_tensorflow.py。
def make_parallel(fn, num_gpus, **kwargs):
in_splits = {}
for k, v in kwargs.items():
in_splits[k] = tf.split(v, num_gpus)
out_split = []
for i in range(num_gpus):
with tf.device(tf.DeviceSpec(device_type="GPU", device_index=i)):
with tf.variable_scope(
tf.get_variable_scope(), reuse=tf.AUTO_REUSE):
out_i = fn(**{k: v[i] for k, v in in_splits.items()})
out_split.append(out_i)
return tf.reduce_sum(tf.add_n(out_split)) / tf.to_float(
self.batch_size)
make_parallel 的第一個引數是一個函式,也就是我們自己定義的如何建立神經網路模型函式。第二個引數指定 GPU 卡數,資料將被平均地分配給這些 GPU。除此之外的引數將以 keyword argument 的形式傳入,是神經網路的輸入層 Tensor 。
在定義神經網路模型時,需要建立 varaiable_scope ,同時指定 reuse=tf.AUTO_REUSE ,保證多個 GPU 卡上的可學習引數會是共享的。
make_parallel 中使用 tf.split op 對輸入資料 Tensor 進行切分,使用 tf.add_n 合併多個 GPU 卡上的計算結果。
一些情況下同樣可以使用 tf.concat 來合併多個卡的結算結果,這裡因為使用了 dataset api 為 dynamic rnn feed 資料,在定義計算圖時 batch_size 和 max_sequence_length 均不確定,無法使用 tf.concat 。
下麵是對 make_parallel 的呼叫,從中可看到如何使用 make_parallel 方法。
self.cost = self.make_parallel(
self.build_model,
len(get_available_gpus()),
curwd=curwd,
nxtwd=nxtwd,
seq_len=seq_len)
除了呼叫 make_parallel 之外,還有一處修改需要註意:在定義最佳化方法時,需要將 colocate_gradients_with_ops 設定為 True,保證前向 Op 和反向 Op 被放置在相同的裝置上進行計算。
optimizer.minimize(self.cost, colocate_gradients_with_ops=True)
總結
如何利用多個 GPU 卡進行訓練對複雜模型或是大規模資料集上的訓練任務往往是必然的選擇。鑒於在使用中的有效性和通用性,這一節我們主要介紹了在 PaddleFluid 和 TensorFlow 上透過資料並行使用多個 GPU 卡最簡單的方法。
這一篇所有可執行的例子都可以在 04_rnnlm_data_parallelism [4] 找到,更多實現細節請參考具體的程式碼。值得註意的是,不論是 PaddleFluid 還是 TensorFlow 都還有其他多種利用多計算裝置提高訓練並行度的方法。請大家隨時關註官方的最新檔案。
參考文獻
[1]. 本文配套程式碼
https://github.com/JohnRabbbit/TF2Fluid/tree/master/04_rnnlm_data_parallelism
[2]. Tower樣式
https://github.com/tensorflow/models/blob/master/tutorials/image/cifar10/cifar10_multi_gpu_train.py
[3]. nccl
https://www.tensorflow.org/api_docs/python/tf/contrib/nccl
[4]. 04_rnnlm_data_parallelism
https://github.com/JohnRabbbit/TF2Fluid/tree/master/04_rnnlm_data_parallelism
PaddlePaddle開發者交流群
想獲取更多深度學習框架乾貨?
加入交流群和工程師實時交流
框架介紹√技術乾貨√線上Q&A;√
申請入群
長按識別二維碼,新增小助手
*加好友請備註「PaddlePaddle」

關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 加入社群刷論文
