在過去一年裡,Kubernetes以其架構簡潔性和靈活性,流行度持續快速上升,我們有理由相信在不遠的未來,Kubernetes將成為通用的基礎設施標準。而京東早在2016年年底上線了京東新一代容器引擎平臺JDOS2.0,成功從OpenStack切換到JDOS 2.0的Kubernetes技術棧,打造了完整高效的PaaS平臺。
京東的容器主要是自用,京東的資料中心現在規模已經比較大,實際上我們用Kubernetes或者是以前用OpenStack的思路完全是克隆谷歌資料中心管理的理念。
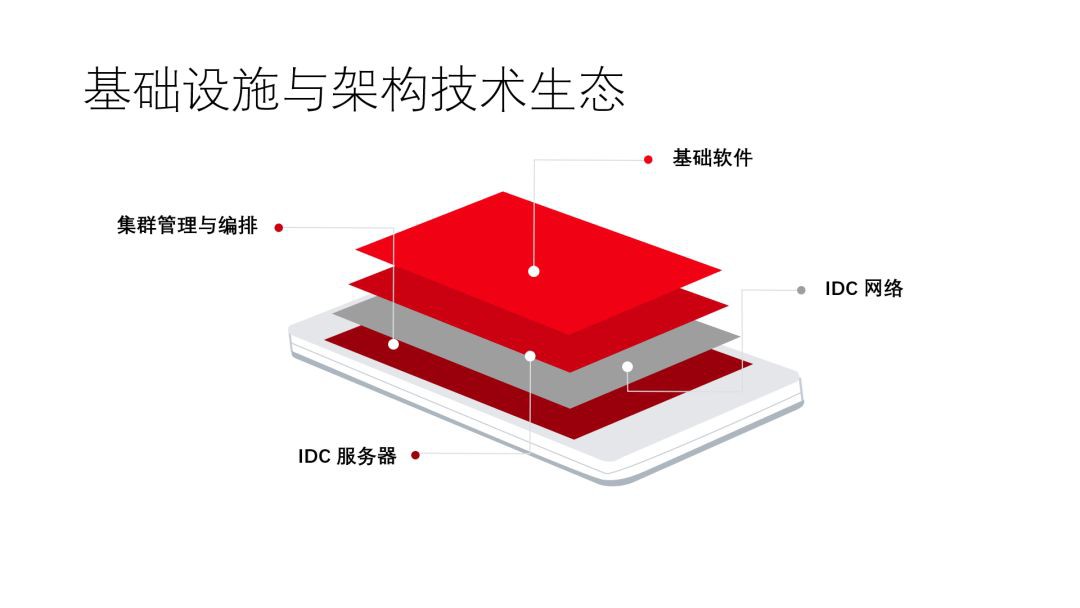
其實資料中心就是圍繞著幾個東西來說:伺服器、網路以及一些基礎軟體,剩下的就是叢集的管理。這裡要說明一下,我們認為基礎軟體是資料中心非常重要的一個環節,比如,域名解析、負載均衡、時鐘這些東西,雖然Kubernetes管理了整個叢集,但是這些東西它依然沒有。也就是說,要是想把它用得非常好的話,這些軟體也要進行一些適當的變革。
京東在使用Kubernetes管理大資料中心的時候,也圍繞著Kubernetes在我們內部的資料中心建了很多生態。首先是適合容器化的DNS,以及適合容器化的負載均衡,還有適合容器化的檔案系統、映象中心等等。這裡面特別要說明一點,就是DNS跟LB,Kubernetes 1.9合入了高效能的負載均衡。
如果在大規模生產環境中,高效能的負載均衡是必不可少的,但這個負載均衡又涉及到另外一些問題。首先,要跟現有的資料中心適配,京東自主研發了一套負載均衡以及DNS。雖然社群裡有CoreDNS等等,但是這些DNS存在一個問題,就像昨天某廠的一個故障那樣,你把所有的東西這個引導這個,那個引導那個。如果你的DNS不在容器內的話,帶來的後果是很難料想的。因為京東容器已經發展了很多年,資料中心也比較大,我們單個Kubernetes叢集能夠做到8000到10000臺。因為我們的機器實在太多,如果不做大叢集的話,人力管理的投入上會非常大。後面我會解釋怎麼做到這麼大規模的叢集。
京東容器化的資料中心建設已經四五年了,已經比較穩定了,雖然我們的Kubernetes還比較老,是1.6版本,但是我們已經有很多改進,我們現在的重點就是往阿基米德,也就是往資料中心的資源排程這個方向發展。去年雙十一的時候阿基米德已經上線了,Kubernetes使用到後期的時候,你會發現Kubernetes並不能解決資料中心資源使用率的問題,它其實僅僅解決了你的釋出,或者是管理資源的容器這方面的一些東西。
上圖是我們資料中心的基礎架構,其實比較傳統,我們會把負載均衡、域名,以及我們包的這個Kubernetes的API統一抽象出來,整個就是一套。然後在每個資料中心部署若干套Kubernetes叢集,每一個Kubernetes叢集,會管理三個物理Pod,大概是一萬臺的規模。
為了配合這個規模,我們做了一些工作。DNS最早的時候,還沒有CoreDNS來適配,大家知道每個資料中心最老的DNS是bind9,適配起來是非常痛苦的,它缺API,缺很多東西。所以我們就自己研發了一套基於etcd的分散式DNS,當時提供了RestfulAPI,直接對接的Kubernetes的watch,這樣的話我們就能夠做一個非常好的適配。但是後來我們發現一個問題,原來你有可能10萬臺物理機,也就假設就是你的hostname的解析也就10萬個,現在不一樣了,一臺物理機是100多個容器,即你增長了100倍。這時運維解析的請求量會激增,增長之後會帶來一個問題,抖動、延遲都非常大,間接的就影響了你的業務的TP響應。因此我們後來又把我們域名解析的服務,改成了DPDK的服務,現在的效能是bind9的19倍,是CoreOS的60多倍,每秒查詢率能衝到800萬QBS。
有人問,京東做一個這麼大的Kubernetes叢集,是不是特別複雜特別容易出錯。確實,如果你的叢集非常多,假設你有50個叢集,那麼你誤操作的機率可能就是這50的機率相加。因此京東會把整個Kubernetes的叢集做減法,並沒有做加法,當然這是代表京東的一家之言了,因為我們是自用,並不是往外賣,所以我們主要是做減法,以適合我們使用。
為了適用上萬臺Server的這種規模,最大的問題就是API的負載容易崩潰。比如你把config-map存到etcd裡面去,這個設計本身就是有問題的。如果你的規模比較大的話,一定要去改,如果不改,你的叢集很快就會崩潰。其實我們的做法其實還比較傳統,就是採用一些快取技術,就比如說config-map我們壓根是不會放在etcd裡去的。因為如果你把config-map放到etcd裡去的話,首先假設有一個使用者,給你傳一百個20M的配置檔案,你就完蛋了。
其次,京東對controller也做了很多重構,雖然社群提供了很多controller,但我可以保證,這些controller絕對沒有做嚴格的關聯性測試,也就是說有些controller之間互相是有影響的。建議啟用任何一個controller前都要做嚴格的分析跟測試。想做大叢集的Kubernetes,必須得去改,而且是做減法式的改。
還有一點,Kubernetes號稱有各式各類功能,我可能要潑一下冷水。京東很多東西的確是基於Kubernetes建設起來的,Kubernetes對我們的幫助非常大,但是它也不是萬能的。
Kubernetes號稱的deployment、金絲雀釋出等等一切都非常美好,但是我來自京東基礎架構部門,基礎部門要服務業務,而業務會給你提很多需求,第一次你聽上去可能覺得這需求非常扯,但是你跟他仔細溝通之後,你會發現人家的需求是非常合理的。比如說,他說你金絲雀釋出的時候,副本數隨機的挑幾個,升級了50%,但有的業務方會要求就要升級某一個特定IP。他不是對這個IP特別有感情,而是因為他配了很多host,除了有研發還有測試等等,所以你不得不去面臨這個問題,像IP不變等等這樣的一些需求就會蹦出來,我們都要滿足他,才能繼續往下走。
還有比如說你的節點被物理故障重啟等等,這個時候你要充分的考慮是先拉起新排程過來的容器,還是先拉起原來老的容器,這些策略都要針對你自己的業務去改變。
還有,比如有人說京東大促的時候,我們Kubenetes整個的彈性速度非常快等等。但是我可以向你保證,如果真正是那種流量高峰瞬間來的時候,這個彈性是絕對跟不上的。因為等你還沒彈完,老的已經被打死了,彈幾個死幾個,所以一般來說,你要用更多的實體,用排程的方式來做,而不是說透過scale out這種彈來做,來不及的。
剛才也提到這些策略IP不變,還有我們這有一個很有意思的東西,就是支援容器的rebuild。我們的資源使用率,透過阿基米德排程之後,我們的資源使用率非常緊張,因為少買了很多機器,同時業務又在不斷地增長,這個時候我們資源的限額都會被耗盡,在某些情況下甚至排程器也無能為力。
這怎麼辦?我們採取了一種古老的方法,跳過排程器,進行本地rebuild。因為你的排程有的在排隊,有的depending,但是有一些業務在釋出的時候,他會提出一個問題,我原來有100個容器,我釋出完之後只剩80了,另外20個容器的資源被別的業務搶走了,這是不能接受的,所以我們也有了這種所謂的優先rebuild,就是就地rebuild,這會帶來很多好處。
這麼做最明顯的一個好處,就是拉映象至少省了一些時間。還有一個明顯的好處是,雖然在資料中心依然很複雜,但當業務部署在某一臺容器機器上之後,呼叫的依賴、呼叫資料庫的鏈路都是經過了大量壓測的,已達到相對最優的狀態。如果你今天把這容器從pod1搬到pod2,我說物理pod,從房間1搬到房間2去了,那可能會帶來抖動或者等等情況。當然這並不代表你損失了Kubernetes的很多特性。
補充前面的一點,我們的deployment做了大量定製,原生的deployment其實還是很難滿足這樣的要求。比如說線上上,因為是面向生產環境,但是生產環境不會那麼美好。首先業務,可能上100個容器就有兩個容器,它的響應很差,這個時候要去排查或者要去進行其他的操作,這個時候用deployment做不到,因為一升級就沒了。而我們,讓它可以指定把這兩個停掉,或者是其他操作,反正就是能夠指定,就相當於你要改一些東西,改動量不大,只是在它原來基礎之上改。
下麵說說我們目前的工作重點。京東整個資料中心規模很大,有老有新,整體的資源使用率會有明顯的波峰波谷。比如上圖黑底圖上藍色的線,1點到6點時中國整個網際網路的流量都比較低,但是到8點以後流量就開始逐漸攀升。那麼1點到6點是一個非常浪費的階段,因為我們有大量的計算資源,這時候我們就可以跟大資料產生互補,把線上應用的波谷算力貢獻給大資料做離線計算,剛好大資料也是後半夜,相對來說離線任務更多,因為第二天早上要出報表,於是我們做了一個融合的混合部署的專案,就叫阿基米德,就是把大資料的業務給調到線上業務的平臺上去。
這裡面就涉及到一個問題,就是隔離性。大家都覺得Docker的隔離性已經很優秀了,其實並非如此,它的隔離性沒有大家想象的那麼好,你看到的隔離都是Namespace的隔離,真正的效能隔離其實並沒有完全做到位。例如記憶體回收,它其實是作業系統統一進行回收的。比如上面10個容器有5個容器狂讀小檔案,這時候突然記憶體已經到一定閥值了,它就要做一次slab回收。一旦slab回收,它就都被block住了,其他的線上業務都會被卡住,雖然只是毫秒級的,但是會有毛刺,業務就會來問你發生了什麼。特別是線上大資料進來之後,這個問題就會被無限放大,因此在這塊你要做適當的改動。京東做得比較早,從2013年就開始做容器,在過去幾年我們在這塊已經做了很多工作。
還有另外一個,大家也都感同身受。業務說我需要100個容器,每個容器八個核,其實之後發現每個容器只跑了不到10%的CPU,這種情況是有可能的。那怎麼辦?你不能粗暴地只給業務兩個核,出問題誰負責?那怎麼辦?我們就告訴業務我們給了他八個核(其實沒有),只要不出事就行了,出了事解釋也無用。這會帶來一個巨大的收益,就像上圖,綠色的部分是我們給的CPU,紅色是實際使用的,那我們至少給他砍一半。這樣做了之後你就會發現,即使一年不買機器,機器也是夠的。
排程方面的問題,京東整個資料中心都是用Kubenretes來管,我們取名為JDOS,即JD Datacenter OS,封包了Kubernetes然後做了大量的定製。往上層看,JDOS支援京東的線上業務。線上業務在2016年6·18之前全部遷完了。然後2017年雙十一的時候資料庫全部都遷完了,到2018年初的時候,我們基本上像中介軟體類的也都大部分遷上來了,也就是說現在我們除了單純的儲存圖片,還在用物理機那種儲存型的伺服器之外,剩下的全在容器上,現在京東已經看不到物理機了。現在正在做的就是把大資料也往上面導。這會帶來一個非常好的收益。
但是把大資料及很多其他業務放上JDOS之後我們發現,整個排程變得非常複雜,原來的排程器只是考慮哪一臺適合放就可以了,用一句話說,它只負責殺,不負責埋。這會帶來一個問題,容器執行之後,帶來的影響Kubernetes是無能為力的,除非崩潰了,它給你再重新拉副本等等。這看上去會很美好,實際上業務會天天投訴你。
為解決這一問題,我們應用上線的時候會要選優先順序,如果你的優先順序不高的話,有可能會被優先順序高的驅逐掉,相當於我們單獨對Kubernetes重新做一個東西,即我們的驅逐器。驅逐器會對Pod打上很多標簽,比如優先順序、容忍度、副本數等等(例如只有一個副本的話,它優先順序再低也不能殺)。這很像OM的排序,當宿主機的CPU、記憶體load達到一定上限的時候,我們就會啟動這種排序,很快地把它排出來,立馬就驅逐,而且驅逐之後,會告訴排程器不要再往這臺上調了。因為有可能資源滿了,它又給調回來了,你又給驅逐,就形成一個死迴圈了。其實基本的理念也非常簡單,就是保障優先順序的系統,大資料是最先優先順序,但是線上業務的話,也要往下放,這樣就能在有限資源的情況下發揮最大的作用,特別是大促的時候,如果都是靠買機器來支撐的話,這是非常恐怖的一件事情。因為每次大促我們都要按20倍來估,這要買多少機器啊。
京東最早是OpenStack,在2016年切換到了Kubernetes,這兩種系統我一直做下來的,我的感受就是, Kubernetes正在往OpenStack這條路上走,越做越龐大,這是一個非常大的問題。誠然,它有很多feature要加,這個也可以理解,可它還是得拆,拆成非常小的模組來做。像現在CNI、CRI、CSI這些模組的拆離應該是比較好的一個開始。Kubernetes在中小規模叢集是沒有問題的,但是它肯定沒有官方號稱的那樣5000臺沒問題,如果是非常大的規模的話,肯定要去改,否則的話會崩潰。我們在早期的時候,上了一些非重要的系統,經歷了非常痛苦的一段時間,它時常崩掉了。
有時候etcd跑著跑著就發現版本差異越來越大,那隻能把另外兩個幹掉,把另外一個副本用來複制另外兩份,這會帶來巨大的問題。etcd的運維現在應該沒有特別成熟的一些方案,它不像資料庫有很成熟的運維方案,畢竟資料放在裡面,如果它崩了,資料就很難找回來,這是非常麻煩的一件事。
還有它的API,因為它是長連結,一般的負載均衡要特別註意起API的時候不能一個一個起,起完了它都來連,搞不好都堆到一臺上去了,會導致負載不均衡,所以正常來說要先把API起好,再去起Kubernetes,這樣負載均衡才會起到作用。
另外,大家一定要特別註意Kubernetes對心跳的判斷,因為它發生not ready的機率太高了。一旦發生節點not ready的話,會產生一系列難以預料的狀態,比如網路抖動,某臺交換機壞了,有可能它就會這樣。所以我們建議心跳檢測這一塊儘量用另外一套系統來做,把你檢測的結果反饋給Kubernetes,這樣可能會更好一些。
本次培訓包括:Docker介紹、Docker映象、網路、儲存、容器安全;Kubernetes架構、設計理念、常用物件、網路、儲存、網路隔離、服務發現與負載均衡;Kubernetes核心元件、Pod、外掛、微服務、雲原生、Kubernetes Operator、叢集災備、Heml等,點選瞭解具體培訓內容。

長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。
文章已於修改
![]()
微信掃一掃
使用小程式