

在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @TwistedW。基於流的生成模型在 2014 年已經被提出,但是一直被忽視。由 OpenAI 帶來的 Glow 展示了流生成模型強大的影象生成能力。文章使用可逆 1 x 1 摺積在已有的流模型 NICE 和 RealNVP 基礎上進行擴充套件,精確的潛變數推斷在人臉屬性上展示了驚艷的實驗效果。
如果你對本文工作感興趣,點選底部閱讀原文即可檢視原論文。
關於作者:武廣,合肥工業大學碩士生,研究方向為影象生成。
■ 論文 | Glow: Generative Flow with Invertible 1×1 Convolutions
■ 連結 | https://www.paperweekly.site/papers/2101
■ 原始碼 | https://github.com/openai/glow
影象生成在 GAN 和 VAE 誕生後得到了很快的發展,現在圍繞 GAN 的論文十分火熱。生成模型只能受限於 GAN 和 VAE 嗎?OpenAI 給出了否定的答案,OpenAI 帶來了 Glow,一種基於流的生成模型。
雖然基於流的生成模型在 2014 年就已經提出來了,但是一直沒有得到重視。Glow 的作者在之前已經在基於流的生成模型上提出了 NICE [1] 和 RealNVP [2],Glow 正是在這兩個模型基礎加入可逆 1 x 1 摺積進行擴充套件,精確的潛在變數推斷在人臉屬性上展示了驚艷的實驗效果,具體效果可在 OpenAI 放出的 Demo [3] 下檢視。
論文引入
隨著深度神經網路的發展,生成模型也得到了巨大的飛躍。目前已有的生成模型除了 Glow 外包括三大類,GAN、VAE 和 Autoregressive Model(自回歸模型)。 其中自回歸模型和 VAE 是基於似然的方法,GAN 則是透過縮小樣本和生成之間的分佈實現資料的生成。文中對這些已有的生成模型也做了一個小結:
1. 自回歸模型(Autoregressive Model):自回歸模型在 PixelCNN 和 PixelRNN 上展示了很不錯的實驗效果,但是由於是按照畫素點去生成影象導致計算成本高, 在可並行性上受限,在處理大型資料如大型影象或影片是具有一定麻煩的。
2. 變分自編碼器(VAE):VAE 是在 Autoencoder 的基礎上讓影象編碼的潛在向量服從高斯分佈從而實現影象的生成,優化了資料對數似然的下界,VAE 在影象生成上是可並行的, 但是 VAE 存在著生成影象模糊的問題,Glow 文中稱之為最佳化相對具有挑戰性。
3. 生成對抗網路(GAN):GAN 的思想就是利用博弈不斷的最佳化生成器和判別器從而使得生成的影象與真實影象在分佈上越來越相近。GAN 生成的影象比較清晰, 在很多 GAN 的拓展工作中也取得了很大的提高。但是 GAN 生成中的多樣性不足以及訓練過程不穩定是 GAN 一直以來的問題,同時 GAN 沒有潛在空間編碼器,從而缺乏對資料的全面支援。
基於流的生成模型,首先在 NICE 中得到提出併在 RealNVP 中延伸。可以說流的生成模型被 GAN 的光芒掩蓋了,但是是金子總會發光。Glow 一文算是將流生成模型推到了學術的前沿,已經有很多學者在討論 Glow 的價值,甚至有說 Glow 將超越 GAN。
具體還要看學術圈的進一步發展,不過 Glow 確實在影象的生成,尤其是在影象編碼得到的潛在向量精確推斷上展示了很好的效果。在 OpenAI 放出的 Demo 上展示了很驚艷的實驗效果,就人臉合成和屬性變化上可以看出 Glow 確實可以媲美 GAN。
基於流的生成模型總結一下具有以下優點:
1. 精確的潛在變數推斷和對數似然評估,在 VAE 中編碼後只能推理出對應於資料點的潛在變數的近似值,GAN 根本就沒有編碼器更不用談潛在變數的推斷了。在 Glow 這樣的可逆生成模型中,可以在沒有近似的情況下實現潛在變數的精確的推理,還可以最佳化資料的精確對數似然,而不是其下限。
2. 高效的推理和合成,自回歸模型如 PixelCNN,也是可逆的,然而這樣的模型合成難以實現並行化,並且通常在並行硬體上效率低下。而基於流的生成模型如 Glow 和 RealNVP 都能有效實現推理與合成的並行化。
3. 對下游任務有用的潛在空間,自回歸模型的隱藏層有未知的邊際分佈,使其執行有效的資料操作上很困難;在 GAN 中,由於模型沒有編碼器使得資料點通常不能在潛在空間中直接被表徵,並且表徵完整的資料分佈也是不容易的。而在可逆生成模型和 VAE 中不會如此,它們允許多種應用,例如資料點之間的插值,和已有資料點的有目的修改。
4. 記憶體的巨大潛力,如 RevNet 論文所述,在可逆神經網路中計算梯度需要一定量的記憶體,而不是線性的深度。
基於流的生成模型的優勢展示了 Glow 的魅力,但是在 Glow 論文解讀前,我們還是先回顧一下前兩個基於流的生成模型 NICE 和 RealNVP。
NICE
NICE 的全稱為 NON-LINEAR INDEPENDENT COMPONENTS ESTIMATION,翻譯過來就是“非線性獨立分量估計”。整體上來說,NICE 是為了對複雜的高維資料進行非線性變換,將高維資料對映到潛在空間,產生獨立的潛在變數。這個過程是可逆的,即可以從高維資料對映到潛在空間,也可以從潛在空間反過來對映到高維資料。
為了實現這個可逆的對映關係,就需要找到一個滿足對映的函式 f,使得 h=f(x),這裡的 x 就是高維資料,對應到影象生成上 x 就是輸入的影象,h 就是對映到的潛在空間。這個過程是可逆的,也就是 。這個潛在空間可以給定一個先驗分佈 pH(h),即 h∼pH(h)。 所以實現 NICE 的關鍵就是找到這個可逆的對映 f,這個不是一件容易的事,此時就引入了一個矩陣用於輔助實現對映,這就是雅可比矩陣。
。這個潛在空間可以給定一個先驗分佈 pH(h),即 h∼pH(h)。 所以實現 NICE 的關鍵就是找到這個可逆的對映 f,這個不是一件容易的事,此時就引入了一個矩陣用於輔助實現對映,這就是雅可比矩陣。
雅可比矩陣
假設 是一個從歐式 n 維空間轉換到歐式 m 維空間的函式。這個函式由 m 個實函式組成
是一個從歐式 n 維空間轉換到歐式 m 維空間的函式。這個函式由 m 個實函式組成 。 這些函式的偏導數(如果存在)可以組成一個 m 行 n 列的矩陣,這就是所謂的雅可比矩陣:
。 這些函式的偏導數(如果存在)可以組成一個 m 行 n 列的矩陣,這就是所謂的雅可比矩陣:

此矩陣表示為: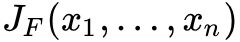 ,或者
,或者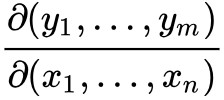 。
。
雅可比行列式
如果 m=n,那麼 F 是從 n 維空間到 n 維空間的函式,且它的雅可比矩陣是一個方塊矩陣,此時存在雅克比行列式。
雅克比矩陣有個重要的性質就是一個可逆函式(存在反函式的函式)的雅可比矩陣的逆矩陣即為該函式的反函式的雅可比矩陣。即,若函式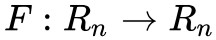 在點
在點 的雅可比矩陣是連續且可逆的,則 F 在點 p 的某一鄰域內也是可逆的,且有
的雅可比矩陣是連續且可逆的,則 F 在點 p 的某一鄰域內也是可逆的,且有 。
。
對雅克比矩陣有所瞭解後就可以實現對映:

其中 就是 x 處的函式 f 的雅可比矩陣。
就是 x 處的函式 f 的雅可比矩陣。
設計這個對映函式 f 的核心就是將輸入 x 進行分塊,即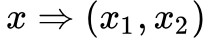 。
。

其中 m 是任意複雜的函式,但是這個分塊對於任何 m 函式都具有單位雅可比行列式,且下麵是可逆的:

上面的對映用對數表示就是:
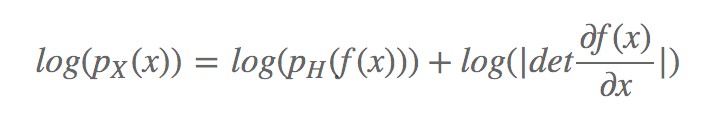
計算具有高維域函式的雅可比行列式並計算大矩陣的行列式通常計算量是很大的,所以直接去算雅克比行列式是不現實的,所以需要對計算做一定的簡化。 NICE論文采用分層和組合變換的思想處理,即 (此處符號根據 NICE 一文與 Glow 有些許出入)。 在一些細節最佳化上可以採用矩陣的上三角矩陣和下三角矩陣做變換表示方陣。
(此處符號根據 NICE 一文與 Glow 有些許出入)。 在一些細節最佳化上可以採用矩陣的上三角矩陣和下三角矩陣做變換表示方陣。
有了分層和組合變換的處理,接著就是對組合關係的確立,文中採用尋找三角形雅克比矩陣函式簇,透過耦合層關聯組合關係,也就是對 x 做分塊找到合適的函式 m。 具體的細節這裡不展開了,有興趣的可以閱讀原文瞭解。
RealNVP
RealNVP 的全稱為 Real-valued Non-volume Preserving 強行翻譯成中文就是“實值非體積保持”,文章的全稱為 DENSITY ESTIMATION USING REAL NVP, 翻譯過來就是“使用 RealNVP 進行密度估計”。RealNVP 是在 NICE 的基礎上展開的,在 NICE 的基礎上將分層和組合變換的思想進一步延伸。
NICE 中採用的耦合關係是加性耦合層,即對於一般的耦合層:

所謂加性耦合層就是取 g(a;b)=a+b,其中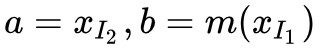 ,此時:
,此時:

除了可以選擇加性耦合層,還可以選擇乘法耦合層或者仿射耦合層(affine coupling layer)。
而 RealNVP 正是採用仿射耦合層來代替加性耦合層,仿射耦合層採用 g(a;b)=a⊙b1+b2,其中 b1≠0,此時的 m 函式為: ,⊙ 為哈達馬積,也就是矩陣的乘法表示,RealNVP 引入仿射耦合層後模型更加靈活。 用 s 代表尺度,t 代表平移量,此時的分塊表示為:
,⊙ 為哈達馬積,也就是矩陣的乘法表示,RealNVP 引入仿射耦合層後模型更加靈活。 用 s 代表尺度,t 代表平移量,此時的分塊表示為:

這樣就實現了透過堆疊一系列簡單的雙射來構建靈活且易處理的雙射函式。
RealNVP 在 NICE 的基礎上的另一大改進就是做多尺度框架的設計。所謂的多尺度就是對映得到的最終潛在空間不是一次得到的,而是透過不同尺度的 潛在變數拼接而成的。我們看一下 RealNVP 給出的多樣性示例解釋圖,這個圖其實還不太清晰,在 Glow 中給的圖就已經很清晰了。

上圖的意思就是每一次做流生成潛在變數時,由於要將兩個潛在變數拼接後輸出,為了保證多尺度就每次保留一個潛在變數,將另一個潛在變數傳回到輸入再次進行流操作, 經過 L−1 次流操作後將不再傳回到輸入而是直接輸出和之前的 L−1 個潛在變數拼接形成最後的潛在變數的輸出。我們再結合公式理解一下,這裡稍微有點繞:

舉個例子就是,比如輸入 x 有 D 維,第一次經過流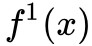 得到潛在變數 (z1,h1) 其中 z1 和 h1 維度都是
得到潛在變數 (z1,h1) 其中 z1 和 h1 維度都是![]() , 保留 z1,將 h1 送入下一輪流將得到
, 保留 z1,將 h1 送入下一輪流將得到![]() 的潛在變數,保留一個,送入另一個,直到第 L−1 輪將潛在變數直接輸出和其餘的潛在變數拼接形成最終的輸出 z。 這裡強調一下,多尺度框架的迴圈和流內部的經歷的次數沒關係,這裡為了保留 RealNVP 原文的符號,採用的符號都是原文中的符號。
的潛在變數,保留一個,送入另一個,直到第 L−1 輪將潛在變數直接輸出和其餘的潛在變數拼接形成最終的輸出 z。 這裡強調一下,多尺度框架的迴圈和流內部的經歷的次數沒關係,這裡為了保留 RealNVP 原文的符號,採用的符號都是原文中的符號。
RealNVP 基本上就是這樣,但是細節還有很多,這裡不詳細展開,深入瞭解的可讀原文。
Glow模型
我們先一起來看看 Glow 的模型框架:
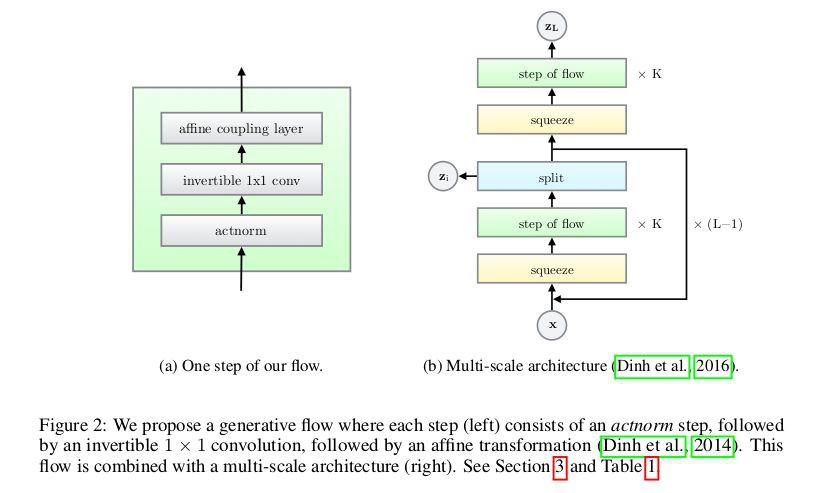
可以看到整個模型分為 (a) 和 (b),其實 (a) 只是對 (b) 中的“step of flow”的展開。Glow 的思想和前兩篇整體上是一致的,都是為了找到可逆的雙射來實現輸入和潛在空間的相互轉換。
在設計對映函式時,採用分層變換的思想,將對映 f 函式變換為 ,也就是一個完整的流需要 K 次單步流才能完成,即
,也就是一個完整的流需要 K 次單步流才能完成,即 (這裡的 h 值是內部流的過渡符號和上文提到的多尺度結構不同)。在完整流結束後經過 split 後做多尺度迴圈,經過 L−1 迴圈最終的潛在變數就是
(這裡的 h 值是內部流的過渡符號和上文提到的多尺度結構不同)。在完整流結束後經過 split 後做多尺度迴圈,經過 L−1 迴圈最終的潛在變數就是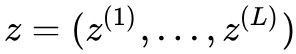 。
。
我們把單步流的框架再仔細分析一下。
Actnorm
單步流中的第一層就是 Actnorm 層,全稱為 Activation Normalization 翻譯為啟用標準化,整體的作用類似於批歸一化。但是批次歸一化新增的啟用噪聲的方差與 GPU 或其他處理單元(PU)的小批次大小成反比,這樣造成了效能上的下降,所以文章推出了 Actnorm。
Actnorm 使用每個通道的標度和偏差引數執行啟用的仿射變換,類似於批次標準化,初始化這些引數,使得在給定初始資料小批次的情況下,每個通道的後行為動作具有零均值和單位方差。初始化後,標度和偏差被視為與資料無關的常規可訓練引數。可以理解 Actnorm 就是對輸入資料做預處理。
Invertible 1×1 Convolution
可逆 1×1 摺積是在 NICE 和 RealNVP 上的改進,NICE 和 RealNVP 是反轉通道的排序,而可逆 1×1 摺積替換該固定置換,其中權重矩陣被初始化為隨機旋轉矩陣。具有相等數量的輸入和輸出通道的 1×1 摺積是置換操作的概括。透過矩陣的簡化計算,可以簡化整體的計算量。
Affine Coupling Layers
仿射耦合層在 RealNVP 中就已有應用,而 Glow 的基礎是預設讀者已經掌握了 NICE 和 RealNVP 所以單單隻讀 Glow 可能不能輕易的理解文章。
仿射耦合層的映入是實現可逆轉換的關鍵,仿射耦合的思想我們上面也有提過,Glow 將其分為三部分講解。
零初始化(Zero initialization):用零初始化每個 NN () 的最後一個摺積,使得每個仿射耦合層最初執行一個同一性函式,這有助於訓練深層網路。
拆分和連線(Split and concatenation):split () 函式將輸入張量沿通道維度分成兩半,而concat () 操作執行相應的反向操作:連線成單個張量。 RealNVP 中採用的是另一種型別的分裂:沿著棋盤圖案的空間維度拆分。Glow 中只沿通道維度執行拆分,簡化了整體架構。
排列(Permutation):上面的每個流程步驟之前都應該對變數進行某種排列,以確保在充分的流程步驟之後,每個維度都可以影響其他每個維度。 NICE 完成的排列型別是在執行加性耦合層之前簡單地反轉通道(特徵)的排序;RealNVP 是執行(固定)隨機排列;Glow 則是採用可逆 1 x 1 摺積。文中也對三種方法做了實驗上的比較。
對於單步流的內部操作,文章也做瞭解釋:

Glow實驗
實驗的開篇是比較 Glow 和 RealNVP,反轉操作上 NICE 採用反轉,RealNVP 採用固定隨機排列,Glow 採用可逆 1 × 1 摺積,並且耦合方式也影響實驗的效果,文章比較了加性耦合層和仿射耦合層的效能差距。透過在 CIFAR-10 資料集的平均負對數似然(每維度的位元)來衡量不同操作的差距,其中所有模型都經過 K = 32 和 L = 3 的訓練,實驗效果如下圖:
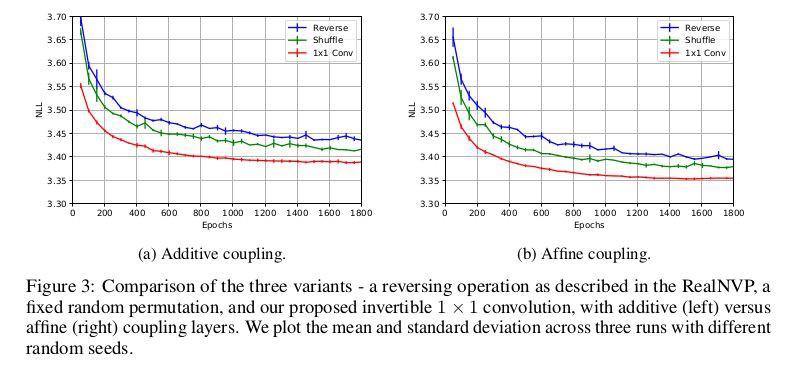
可以從上圖看出,Glow 採用的方法都取得了較小的平均負對數似然,這說明瞭在實驗上是由於其他幾個模型的。
為了驗證 RealNVP 和 Glow 整體的框架下的差距,實驗進一步擴充套件,比較了 CIFAR-10,ImageNet 和 LSUN 資料集上兩者的差距,在相同預處理下得到的結果如下:

正如表 2 中顯示的,模型在所有資料集上實現了顯著的改進。
在高解析度影象的生成上,Glow 使用了 CelebA-HQ 資料集,資料集包含 3 萬張高解析度的圖片。實驗生成 256 x 256 影象,設定 K=32,L=6。我們看到這裡的 L 取了 6,在高解析度下,多尺度的豐富可能會讓得到的潛在變數具有更多的影象細節。試驗中採用了退火演演算法來最佳化實驗,在退火引數 T=0.7 時候,合成的隨機樣本如下圖:

可以看到合成的影象質量和合理性都是很高的,為了對潛在變數插值生成影象,實驗以兩組真實圖片為依據,插值中間的過渡,生成的結果如下:

從上圖能看出整體的過渡還是相當順暢的,感覺很自然,這就是 Glow 在潛在變數精確推斷的優勢所在,這樣的實驗結果讓人很驚訝!
為了生成更多含語意的影象,文章利用了一些標簽來監督訓練,對於不同人臉屬性合成的影象如下:

生成的效果和過渡都是很自然合理。
退火模型對提高生成也是很重要的環節,文章對比了不同退火引數 T 下的實驗效果,合理的 T 的選擇對於實驗效果還是很重要的。

為了說明模型深度(多尺度)的意義,文中對比了 L=4 和 L=6 的效果,可以看出多尺度對於整體模型的意義還是很大的。

總結
Glow 提出了一種新的基於流的生成模型,併在標準影象建模基準上的對數似然性方面展示了改進的定量效能,特別是在高解析度人臉影象合成和插值生成上取得了驚艷的效果。從整體的閱讀上可以看出 Glow可以完成較好的影象合成和變換的工作,具體的工作還要在吃透程式碼再進一步瞭解。寫的過程中有什麼問題,歡迎指正,謝謝。
參考文獻
[1]. NICE: Non-linear independent components estimation” Laurent Dinh, David Krueger, Yoshua Bengio. ArXiv 2014.
[2]. Density estimation using Real NVP. Ding et al, 2016.
[3]. Glow Demo: https://blog.openai.com/glow/
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

點選標題檢視更多論文解讀:
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 下載論文
