來自:戀習Python(ID:sldata2017)

前兩天,在網上看到一個有意思的問題:彩票預測靠譜麼?為什麼還有那麼多的人相信彩票預測?
暫且不說,彩票預測是否靠譜?彩票預測也分人而異,江湖上騙術很多,有些甚至會誤以為彩票預測的準確度可以很高,這些操盤手法,讓不知原理的彩民心甘情願地掏錢買料。
在彩票預測上,也有正兒八經去研究“規律” 的,不外乎三個“派別”:資料派、圖形派、公式派。還有一派不列入:字謎字畫派,可納入蛇精病行列。
究竟哪一派預測的靠譜準確呢?不懂,因為我幾乎不買彩票(買也是玩玩,娛樂娛樂),也不去研究。但不管哪一派總得有資料可研究,今天我只負責幫大家如何獲取3D彩票自創辦以來,所有的資料(中獎號碼、中獎註數、銷售額以及返獎比例等)
在爬取一些簡單的(沒有反爬機制的)靜態網頁時,一般採取的策略是:選中標的(所謂的url連結),觀察結構(連結結構,網頁結構),構思動手(選用什麼HTML下載器,解析器等)。在爬蟲過程中,都會涉及到三種利器:
HTML下載器:下載HTML網頁
HTML解析器:解析出有效資料
資料儲存器:將有效資料透過檔案或者資料庫的形式儲存起來
今天,我們將利用requests庫和BeautifulSoup模組來抓取中彩網頁福彩3D相關的資訊,並將其儲存到Excel表格中。
在開始前,先分析看看標的網頁的結構:
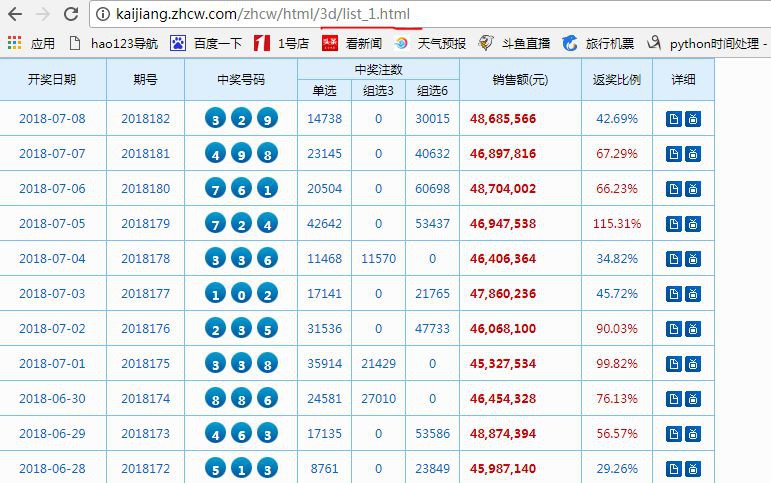

可以發現,標的網頁的URL http://kaijiang.zhcw.com/zhcw/html/3d/list_2.html,每次變化一處:list_x後面的數字,其代表第幾頁。

然後,觀察其網頁結構,也很簡單,可以看到一期的彩票資訊對應的原始碼是一個tr節點,我們可以用BeautifulSoup庫來提取這裡面的一些資訊。
整體思路是:若要獲取福彩3D創辦14年以來所有的資訊(一共246頁),只需要分開請求246次,這樣獲取不同的頁面之後,再利用BeautifulSoup庫提取到相關資訊,利用xlrd庫將資料寫入Excel中,就可以獲取到福彩3D所有的資訊,結果如下圖:
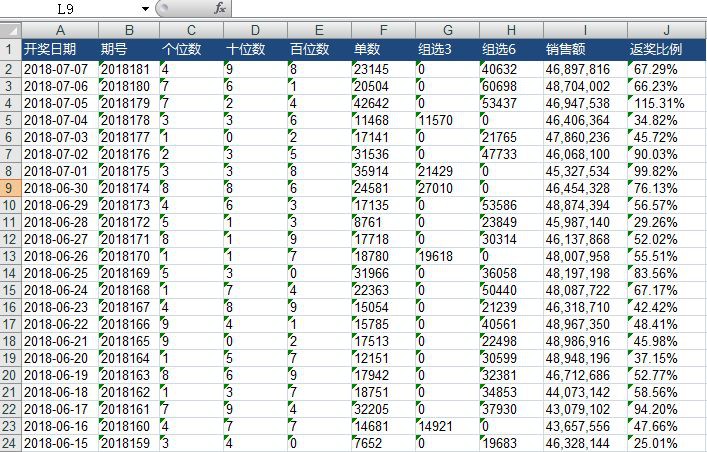

(一共將近5000條資料)
詳情程式碼如下:
import requests
from bs4 import BeautifulSoup
import xlwt
import time
#獲取第一頁的內容
def get_one_page(url):
essay-headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/64.0.3282.140 Safari/537.36'
}
response = requests.get(url,essay-headers=essay-headers)
if response.status_code == 200:
return response.text
return None
#解析第一頁內容,資料結構化
def parse_one_page(html):
soup = BeautifulSoup(html,'lxml')
i = 0
for item in soup.select('tr')[2:-1]:
yield{
'time':item.select('td')[i].text,
'issue':item.select('td')[i+1].text,
'digits':item.select('td em')[0].text,
'ten_digits':item.select('td em')[1].text,
'hundred_digits':item.select('td em')[2].text,
'single_selection':item.select('td')[i+3].text,
'group_selection_3':item.select('td')[i+4].text,
'group_selection_6':item.select('td')[i+5].text,
'sales':item.select('td')[i+6].text,
'return_rates':item.select('td')[i+7].text
}
#將資料寫入Excel表格中
def write_to_excel():
f = xlwt.Workbook()
sheet1 = f.add_sheet('3D',cell_overwrite_ok=True)
row0 = ["開獎日期","期號","個位數","十位數","百位數","單數","組選3","組選6","銷售額","返獎比例"]
#寫入第一行
for j in range(0,len(row0)):
sheet1.write(0,j,row0[j])
#依次爬取每一頁內容的每一期資訊,並將其依次寫入Excel
i=0
for k in range(1,247):
url = 'http://kaijiang.zhcw.com/zhcw/html/3d/list_%s.html' %(str(k))
html = get_one_page(url)
print('正在儲存第%d頁。'%k)
#寫入每一期的資訊
for item in parse_one_page(html):
sheet1.write(i+1,0,item['time'])
sheet1.write(i+1,1,item['issue'])
sheet1.write(i+1,2,item['digits'])
sheet1.write(i+1,3,item['ten_digits'])
sheet1.write(i+1,4,item['hundred_digits'])
sheet1.write(i+1,5,item['single_selection'])
sheet1.write(i+1,6,item['group_selection_3'])
sheet1.write(i+1,7,item['group_selection_6'])
sheet1.write(i+1,8,item['sales'])
sheet1.write(i+1,9,item['return_rates'])
i+=1
f.save('3D.xls')
def main():
write_to_excel()
if __name__ == '__main__':
main()
到此,關於14年的福彩3D資訊都可以爬取下來,至於如何預測?下一期的彩票趨勢如何?不懂也不會,接下來是否中獎,就靠你們了。彩民們,我只能幫你們到這了!
最後結尾,關於彩票預測究竟準不準?我不說太多的理論分析,我只提出兩個問題:
命題1:以雙色球為例,下一期雙色球號碼,1,2,3,4,5,6,7 和 3,4,8,11,22,29,7 這兩組號碼的中獎機率如何?誰高誰低還是都一樣?
命題2:第二個問題更簡單。假設你已經投了9次硬幣,結果都是正面。現在你要投第10次,請問是正面的機率是多少?
如果你還要問我,彩票有規律可循嗎?在我看來,彩票規律就是沒有規律(不信,你去分析分析14年以來的所有資料),以人類的計算水平,即使有的話也計算不出來的。彩票是娛樂,是一個運氣的遊戲,一個人即使在彩票上賺到了錢,運氣好,也不代表使用的方法就可以提高彩票中獎率。任何打著提高中獎率的期號進行的盈利行為,即使出發點是善意的,也會最終走向錯誤。
xx的彩票(尤其是黑彩)的實質,就是虛構一個不勞而獲的人,去忽悠一群想不勞而獲的人,最終養活一批真正不勞而獲的人。猶如幣圈一個bi樣!
●編號455,輸入編號直達本文
●輸入m獲取到文章目錄

Java程式設計
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。