(給演演算法愛好者加星標,修煉程式設計內功)
作者:程式設計珠璣/守望 (本文來自作者投稿)
正如它的名字所體現,快速排序是在實踐中最快的已知排序演演算法,平均執行時間為O(NlogN),最壞的執行時間為O(N^2)。演演算法的基本思想很簡單,然而想要寫出一個高效的快速排序演演算法並不是那麼簡單。基準的選擇,元素的分割等都至關重要,如果你不清楚如何最佳化快速排序演演算法,本文你不該錯過。
演演算法思想
快速排序利用了分治的策略。而分治的基本基本思想是:將原問題劃分為若干與原問題類似子問題,解決這些子問題,將子問題的解組成原問題的解。
那麼如何利用分治的思想對資料進行排序呢?假如有一個元素集合A:
-
選擇A中的任意一個元素pivot,該元素作為基準
-
將小於基準的元素移到左邊,大於基準的元素移到右邊(分割槽操作)
-
A被pivot分為兩部分,繼續對剩下的兩部分做同樣的處理
-
直到所有子集元素不再需要進行上述步驟
可以看到演演算法思想比較簡單,然而上述步驟實際又該如何處理呢?
如何選擇基準
實際上無論怎麼選擇基準,都不會影響排序結果,但是不同的選擇卻可能影響整體排序時間,因為基準選擇不同,會導致分割的兩個集合大小不同,如果分割之後,兩個集合大小是幾乎相等的,那麼我們整體分割的次數顯然也會減少,這樣整體耗費的時間也相應降低。我們來看一下有哪些可選擇策略。
選擇第一個或者最後一個
如果待排序數是隨機的,那麼選擇第一個或者最後一個作基準是沒有什麼問題的,這也是我們最常見到的選擇方案。但如果待排序資料已經排好序的,就會產生一個很糟糕的分割。幾乎所有的資料都被分割到一個集合中,而另一個集合沒有資料。這樣的情況下,時間花費了,卻沒有做太多實事。而它的時間複雜度就是最差的情況O(N^2)。因此這種策略是絕對不推薦的。
隨機選擇
隨機選擇基準是一種比較安全的做法。因為它不會總是產生劣質的分割。
C語言實現參考:
ElementType randomPivot(ElementType A[],int start,int end)
{
srand(time(NULL))
int randIndex = rand()%(end -start)+start;
return A[randIndex];
}
選擇三數中值
從前面的描述我們知道,如果能夠選擇到資料的中值,那是最好的,因為它能夠將集合近乎等分為二。但是很多時候很難算出中值,並且會耗費計算時間。因此我們隨機選取三個元素,並用它們的中值作為整個資料中值的估計值。在這裡,我們選擇最左端,最右端和中間位置的三個元素的中值作為基準。
假如有以下陣列:
1 9 10 3 8 7 6 2 4
左端元素為1,位置為0,右端元素為4,位置為8,則中間位置為[0+8]/2=4,中間元素為8。那麼三數中值就為4(1,4,8的中值)。
如何將元素移動到基準兩側
選好基準之後,如何將元素移動到基準兩側呢?通常的做法如下:
-
將基準元素與最後的元素交換,使得基準元素不在被分割的資料範圍
-
i和j分別從第一個元素和倒數第二個元素開始。i在j的左邊時,將i右移,直到發現大於等於基準的元素,然後將j左移,直到發現小於等於基準的元素。i和j停止時,元素互換。這樣就把大於等於基準的移到了右邊,小於等於基準的移到了左邊
-
重覆上面的步驟,直到i和j交錯
-
將基準元素與i所指向的元素交換,使得基準元素將整個元素集合分割為小於基準和大於基準的元素集合
在們採用三數中值得方法選擇基準的情況下,既然基準是中值,實際上只要保證左端,右端,中間值是從小到大即可。還是以前面提到的陣列為例,我們找到三者後,對三者進行排序如下:
排序前

排序後

如果是這樣的情況,那麼實際上不需要把基準元素和最後一個元素交換,而只需要和倒數第二個元素交換即可,因為最後一個元素肯定大於基準,這樣可以減少交換次數。
如果前面的描述還不清楚,我們看一看實際中一趟完整的流程是什麼樣的。
第一步,將左端,右端和中間值排序,中值作為基準:

第二步,將中值與倒數第二個數交換位置:
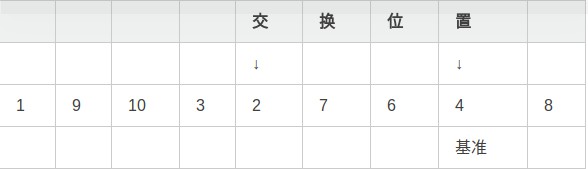
第三步,i向右移動,直到發現大於等於基準的元素9:

第四步,j向左移動,直到發現小於等於基準的元素2:

第五步,交換i和j:
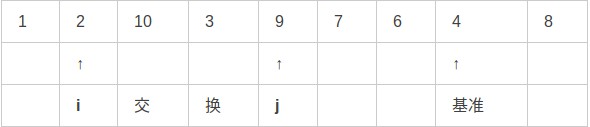
第六步,重覆上述步驟,i右移,j左移: 第七步,交換i和j指向的值: 
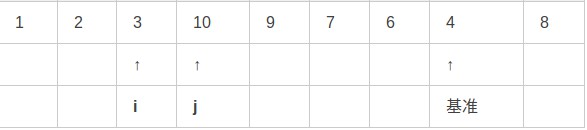
第八步,重覆上述步驟,i右移,j左移,此時i和j已經交錯:

第九步,i和j已經交錯,因此最後將基準元素與i所指元素交換:

如何對子集進行排序到這一步的時候,我們發現i的左邊都是小於i指向的元素,而右邊都是大於i的元素。最後在對子集進行同樣的操作即可。
遞迴法
最常見的便是遞迴法了。遞迴的好處是程式碼簡潔易懂,但是不可忽略的是,當遞迴巢狀過深時,它的效率問題以及棧上限溢位的風險可能會迫使你選擇非遞迴法。在前面對整個集合一分為二之後,對剩下的兩個集合遞迴呼叫,直到完成排序。簡單描述如下(非可執行程式碼):
void Qsort(int A[],int left,int right)
{
/*分割槽操作*/
int i = partition(A,left,right);
/*對子集遞迴呼叫*/
Qsort(A,left,i-1);
Qsort(A,i+1,right);
}
遞迴最需要註意的便是遞迴結束呼叫,否則會產生無限遞迴,從而發生棧上限溢位。
後面我們會看到,遞迴法的程式碼非常簡潔。(相關閱讀《面試官問你斐波那契數列的時候不要高興得太早》)
尾遞迴
在遞迴版本中,Qsort分別遞迴呼叫計算左右兩個子集合,而第二個遞迴其實並非必須,完全可以用迴圈來替代,以下程式碼模擬實現了尾遞迴,(並非是真的尾遞迴):
void Qsort(ElementType A[],int left,int right)
{
int i = 0;
while(left {
/*分割操作*/
i = partition(A,left,right);
/*遞迴呼叫*/
Qsort(A,left,i-1);
/*右半部分透過迴圈實現*/
left = i + 1;
}
}
非遞迴法
那麼有沒有方法可以不用遞迴呢?既然遞迴每次都進行壓棧操作,那麼我們能不能分割槽後僅僅將區間資訊儲存到棧裡,然後從棧中取出區間再繼續分割槽呢?顯然是可以的。實際上我們每次分割槽時,只需要知道區間即可,那麼將這些區間資訊儲存起來,就可以不用遞迴了,按照分好的區間不斷分割槽即可。
例如對於前面提到的陣列,首先對區間[0,8]進行分割槽操作,之後得到兩個新的分割槽,1,2,3和9,7,6,10,8,假設兩個區間仍然可以使用快速排序,那麼需要將區間[0,2]和[5,8]的其中一個壓棧,另一個繼續分割槽操作。
按照這種思路,程式碼簡單描述如下(非可執行程式碼):
void Qsort(A,left,right)
{
while(STACK_IS_NOT_EMPTY)
{
/*分割槽操作*/
POP(lo,hi);
int mid = partition(A,lo,hi);
/*儲存新的邊界*/
PUSH(lo,mid-1);
PUSH(mid+1,hi);
}
}
當然這裡面沒有體現分割槽終止條件。我們需要在資料量小於一定值的時候,就不再繼續進行分割槽操作了,而是選擇插入排序(為什麼?)。
那麼問題來了,如何選擇棧的大小呢?檢視qsort.c的原始碼發現,它選擇瞭如下的值:
#define STACK_SIZE (8* sizeof(unsigned long int));
為什麼會是這個值呢?設想一下,假設待排序陣列長度使用unsigned long int來表示,並且假設每次都將集合分為二等分。那麼即便陣列長度達到最大值,實際上最多隻需要分割8 *(sizeof(unsigned long int))次,也就將它分割完了。然而由於以下幾個原因,需要儲存在棧中的區間資訊很難超出棧空間,因為:
-
陣列長度不會接近unsigned long int,否則記憶體也撐不住了
-
區間足夠小時,不採用快速排序
-
每做一個分割槽,只會增加一個區間PUSH到棧中,增長速度慢
註意事項
至此,快速排序所有的主要步驟已經介紹完畢。但是有以下註意事項:
-
有大量重覆元素時避免產生糟糕分割槽,因此在發現大於等於基準或者小於等於基準時,便停止掃描。
-
通常會將基準一開始移動到最後位置或倒數第二個位置,避免基準在待分割槽區間。
-
對於很小的陣列(N<=20),插入排序要比快速排序更好。因為快速排序有遞迴開銷,並且插入排序是穩定排序。
-
如果函式本身的區域性變數很少,那麼遞迴帶來的開銷也就越小;如果遞迴發生棧上限溢位了,首先需要排除程式碼設計問題。因此如果你設計的非遞迴版本效率低於遞迴版本,也不要驚訝。
註:假定在待排序的記錄序列中,存在多個具有相同的關鍵字的記錄,若經過排序,這些記錄的相對次序保持不變,即在原序列中,r[i]=r[j],且r[i]在r[j]之前,而在排序後的序列中,r[i]仍在r[j]之前,則稱這種排序演演算法是穩定的;否則稱為不穩定的。–來自百科
遞迴版程式碼實現
C語言程式碼實現如下:
#include
#include
#include
/*使用快速排序的區間大小臨界值,可根據實際情況選擇*/
#define MAX_THRESH 4
typedef int ElementType;
/*元素交換*/
void swap(ElementType *a,ElementType *b)
{
ElementType temp = *a;
*a = *b;
*b = temp;
}
/*插入排序*/
void insertSort(ElementType A[],int N)
{
/*最佳化後的插入排序*/
int j = 0;
int p = 0;
int temp = 0;
for(p = 1;p {
temp = A[p];
for(j = p;j>0 && A[j-1] > temp;j--)
{
A[j] = A[j-1];
}
A[j] = temp;
}
}
/*三數中值法選擇基準*/
ElementType medianPivot(ElementType A[],int left,int right)
{
int center = (left + right)/2 ;
/*對三數進行排序*/
if(A[left] > A[center])
swap(&A;[left],&A;[center]);
if(A[left] > A[right])
swap(&A;[left],&A;[right]);
if(A[center] > A[right])
swap(&A;[center],&A;[right]);
/*交換中值和倒數第二個元素*/
swap(&A;[center],&A;[right-1]);
return A[right-1];
}
/*分割槽操作*/
int partition(ElementType A[],int left,int right)
{
int i = left;
int j = right-1;
/*獲取基準值*/
ElementType pivot = medianPivot(A,left,right);
for(;;)
{
/*i j分別向右和向左移動,為什麼不直接先i++?*/
while(A[++i] {}
while(A[--j] > pivot)
{}
if(i {
swap(&A;[i],&A;[j]);
}
/*交錯時停止*/
else
{
break;
}
}
/*交換基準元素和i指向的元素*/
swap(&A;[i],&A;[right-1]);
return i;
}
void Qsort(ElementType A[],int left,int right)
{
int i = 0;
register ElementType *arr = A;
if(right-left >= MAX_THRESH)
{
/*分割操作*/
i = partition(arr,left,right);
/*遞迴*/
Qsort(arr,left,i-1);
Qsort(arr,i+1,right);
}
else
{
/*資料量較小時,使用插入排序*/
insertSort(arr+left,right-left+1);
}
}
/*列印陣列內容*/
void printArray(ElementType A[],int n)
{
if(n > 100)
{
printf("too much,will not print\n");
return;
}
int i = 0;
while(i {
printf("%d ",A[i]);
i++;
}
printf("\n");
}
int main(int argc,char *argv[])
{
if(argc 2)
{
printf("usage:qsort num\n");
return -1;
}
int len = atoi(argv[1]);
printf("sort for %d numbers\n",len);
/*隨機產生輸入數量的資料*/
int *A = malloc(sizeof(int)*len);
int i = 0;
srand(time(NULL));
while(i {
A[i] = rand();
i++;
}
printf("before sort:");
printArray(A,len);
/*對資料進行排序*/
Qsort(A,0,len-1);
printf("after sort:");
printArray(A,len);
return 0;
}
尾遞迴版程式碼實現
略。
非遞迴版程式碼實現
非遞迴版與遞迴版大部分程式碼相同,Qsort函式有所不同,並且增加棧相關內容定義:
/*儲存區間資訊*/
typedef struct stack_node_t
{
int lo;
int hi;
}struct_node;
/*最大棧長度*/
#define STACK_SIZE 8 * sizeof(unsigned int)
/*入棧,出棧*/
#define STACK_PUSH( low, hig ) ( (top->lo = low), (top->hi = hig), top++)
#define STACK_POP( low, hig ) (top--, (low = top->lo), (hig = top->hi) )
/*快速排序*/
void Qsort( ElementType A[], int left, int right )
{
if(NULL == A)
return;
/*使用暫存器指標*/
register ElementType *arr = A;
if ( right - left >= MAX_THRESH )
{
struct_node stack[STACK_SIZE] = { { 0 } };
register struct_node *top = stack;
/*最大區間壓棧*/
int lo = left;
int hi = right;
STACK_PUSH( 0, 0);
int mid = 0;
while ( stack {
/*出棧,取出一個區間進行分割槽操作*/
mid = partition( arr, lo, hi );
/*分情況處理,左邊小於閾值*/
if ( (mid - 1 - lo) <= MAX_THRESH)
{
/* 左右兩個資料段的元素都小於閾值,取出棧中資料段進行劃分*/
if ( (hi - (mid+1)) <= MAX_THRESH)
/* 都小於閾值,從棧中取出資料段 */
STACK_POP (lo, hi);
else
/* 只有右邊大於閾值,右邊繼續分割槽*/
lo = mid -1 ;
}
/*右邊小於閾值,繼續計算左邊*/
else if ((hi - (mid+1)) <= MAX_THRESH)
hi = mid - 1;
/*左右兩邊都大於閾值,且左邊大於右邊,左邊入棧,右邊繼續分割槽*/
else if ((mid -1 - lo) > (hi - (mid + 1)))
{
STACK_PUSH (lo, mid - 1);
lo = mid + 1;
}
/*左右兩邊都大於閾值,且右邊大於左邊,右邊入棧,左邊繼續分割槽*/
else
{
STACK_PUSH (mid + 1, hi);
hi = mid -1;
}
}
}
/*最後再使用插入排序,對於接近有序狀態的資料,插入排序速度很快*/
insertSort(arr,right-left+1);
}
執行結果
我們隨機產生1億個整數,並對其進行排序:
$ gcc -o qsort qsort.c
$ time ./qsort 100000000
遞迴版執行結果:
sort for 100000000 numbers
before sort:too much,will not print
after sort:too much,will not print
real 0m16.753s
user 0m16.623s
sys 0m0.132s
非遞迴版結果:
sort for 100000000 numbers
before sort:too much,will not print
after sort:too much,will not print
real 0m16.556s
user 0m16.421s
sys 0m0.137s
可以看到,實際上兩種方法的效率差距並不是很大。至於原因,前面我們已經說過了。
總結
本文所寫的示例實現與glibc的實現相比,還有很多可最佳化的地方,例如,本文實現僅對int型別實現了排序或交換值,如果待排序內容是其他型別,就顯得力不從心,讀者可參考《高階指標話題函式指標》思考如何實現對任意資料型別進行排序,。但快速排序的最佳化主要從以下幾個方面考慮:
-
最佳化基準選擇
-
最佳化小陣列排序效率
-
最佳化交換次數
-
最佳化遞迴
-
最佳化最差情況,避免糟糕分割槽
-
元素聚合
有興趣地也可以進一步閱讀qsort原始碼,瞭解更多最佳化細節。
思考
-
為什麼要在遇到相同元素時就進行掃描?
-
插入排序最好的情況時間複雜度是多少,在什麼情況下出現?
-
文中實現的程式碼還有哪些可以最佳化的地方?
練習
-
採用第一種基準選擇策略實現快速排序,並測試對有序陣列的排序效能
參考
-
《資料結構與演演算法分析》
-
《演演算法導論》
-
glibc qsort.c原始碼
【本文作者】
守望:一名好文學,好技術的開發者。在個人公眾號「程式設計珠璣」分享原創技術文章,期待一起交流學習
