

公元2016年6月8日,伴隨著眾多粉絲的期待,這部耗資1.6億美元,改編自《魔獸爭霸:人類與獸人》遊戲,擁有眾多英雄人物史詩般的IMAX 3D電影在中國大陸上映。《魔獸》電影展現了兩個各自安詳的世界艾澤拉斯與德拉諾本在黑暗之門的作用下,兩個世界聯絡在了一起,而文明的碰撞和衝擊帶來了新的秩序。
兩天后,儲存界的黑暗之門也正式開啟:當地時間6月9日,NVM Express公司宣佈釋出NVM Express over Fabrics協議。對於眾多的Fabric廠商和儲存廠商來說,這必然是一次嶄新的較量。
計算、儲存、網路是現代企業IT硬體基礎架構的核心。基於Flash和新一代PCM固態儲存的SSD正在極大的改變企業儲存的格局。可以說NVMe就是針對新型的Nonvolatile memory而量身定製的。對於今天的應用來說,基於NVMe協議的SSD可以提供對效能、延遲、IO協議棧開銷的完美最佳化。
而對於計算和網路來說,如何能夠適應這種儲存上的變化,則是在NVMe協議逐漸走向成熟後需要解決的一個核心問題。一個簡單的例子就是今天隨便一個SSD高達幾十萬IOPS的隨機讀寫效能對於今天的單機應用來說簡直是過於浪費了。同時,固態儲存也帶來了客觀上高密儲存的可能性。今天的基於2.5英寸 U.2介面的NVMe SSD可以輕易做到10TB以上的容量。如果一個伺服器接入8個這樣的SSD,可以實現80TB的儲存容量。
解決這樣問題的關鍵,則是透過共享機制,並將儲存容量池化在多個計算節點間共享使用。顯然,這與儲存的虛擬化和雲化以及軟體定義儲存的方向是吻合的。從更廣泛的意義上來說,公有雲和私有雲正式透過了高度的共享和靈活的配置來實現成本節約,可靠性提升和便利管理。
從下麵的Wikibon ServerSAN Research Project報告結果來看,基於DAS和傳統的SAN,NAS的市場正在被超大規模企業雲和企業Server SAN儲存方式逐漸取代。而決定這種替換的速度,則是來源於新技術的可行性以及企業對於採納這些新技術的接受程度。
NVMe over Fabrics把NVMe協議在單系統時代提供的高效能、低延遲和低協議負擔的優勢進一步發揮到了NVMe儲存系統互連結構中。在這種結構裡,基於NVMe over Fabrics的主機可以透過互連結構訪問到任何一個資料中心的儲存節點,而這種訪問是具有同樣高效能、低延遲和低協議負擔的優勢。
更加難能可貴的是,NVMe over Fabrics協議是構造在其他的傳輸層協議基礎之上的,因此可以使用原來的傳輸層協議配合NVMe over Fabrics的協議實現這些優勢,並不需要摒棄資料中心已經建設好的硬體環境。

在NVMe over Fabrics協議誕生之前,基於SCSI的眾多互聯協議已經在考慮如何改善系統效能並降低CPU的負擔了。iSCSI協議提供了基於IP乙太網的SCSI互聯協議,它僅僅依賴傳統的IP網路,提供了可共享的儲存方式。
由於iSCSI依賴於TCP協議,並且TCP協議本身代價較大,因此它的效能在通常的配置下並不好。為了最佳化iSCSI的效能,擴充套件了iSCSI Extensions for RDMA (iSER)。iSER是面向各種RDMA傳輸層協議的儲存協議,由於RDMA效率很高,iSER相比於iSCSI協議來說具有非常好的效能、極低的延遲和CPU使用率。
但是由於iSER仍然是基於SCSI這個儲存協議進行擴充套件的,因此在協議棧的組織上仍然受限於SCSI協議的限制,例如佇列的數量、深度等。在效能達到幾十萬IOPS的時候仍然會有較大的協議開銷。基於上述原因和出於對未來NVM儲存功能要求的需要,NVMe over Fabrics協議應運而生。

NVMe over Fabrics協議定義了使用各種通用的傳輸層協議來實現NVMe功能的方式。在協議中所指的傳輸層包括了RDMA,Fiber Channel,PCIe Fabrics等實現方式。依據具體的傳輸層不同,又有不同的傳輸層系結協議去具體規範每一種網際網路絡所具體需要實現的傳輸轉換層實現。例如,INCITS 540 Fibre Channel – Non-Volatile Memory Express (FC-NVMe)規定了對於FiberChannel這種媒體所支援NVMe over Fabrics所必需實現的介面方式。
由於NVMe over Fabrics協議的這種靈活性,它可以非常方便地生長在各個主流的傳輸層協議中。不過由於不同的互聯協議本身的特點不同,因此基於各種協議的NVMe over Fabrics的具體實現活躍都是不同的。一些協議本身的協議開銷較大,另一些需要專用的硬體網路裝置,客觀上限制了NVMe over Fabrics協議在其中的推廣。下表列出了一些典型的協議的優缺點。

雖然有著眾多可以選擇的互聯方式,這些互聯方式按照介面型別可分成三類:記憶體型介面,訊息型介面和訊息記憶體混合型介面。相應的互聯型別和例子參見下圖。
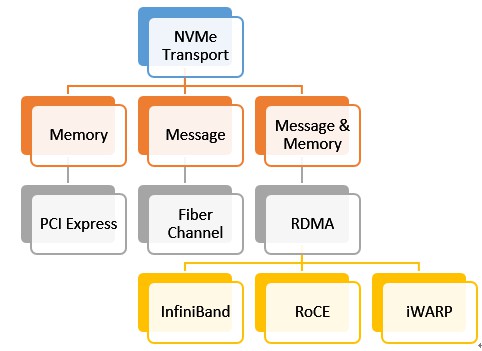
在這些眾多的傳輸層協議中,重點介紹一下RDMA。RDMA是一項古老的技術。它透過網際網路絡把資料直接傳入某臺計算機的一塊儲存區域,不需用到多少計算機的處理功能。
普通網絡卡集成了支援硬體校驗和的功能,並對軟體進行了改進,從而減少了傳送資料的複製量,但無法減少接收資料的複製量,而這部分複製量要佔用處理器的大量計算週期。為充分發揮萬兆位乙太網的效能優勢,必須消除主機CPU中不必要的頻繁資料傳輸,減少系統間的資訊延遲。
從下麵的圖中看出,RDMA透過網路把資料直接傳入計算機的儲存區,降低了CPU的處理工作量。當一個應用執行RDMA讀或寫請求時,不執行任何資料複製。在不需要任何核心記憶體參與的條件下,RDMA請求從執行在使用者空間中的應用中傳送到本地NIC(網絡卡),然後經過網路傳送到遠端NIC。

RDMA對於NVMe over Fabrics協議的便利性體現在下麵幾個方面:
- 提供了低延遲、低抖動和低CPU使用率的傳輸層協議;
- 最大限度利用硬體加速,避免軟體協議棧的開銷;
- 依賴於開放互聯聯盟組織維護的Verbs和程式碼庫,RDMA定義了豐富的可非同步訪問的介面機制,這對於提高IO效能是至關重要的。
RDMA依據底層的不同,可進一步分成InfiniBand,RoCE和iWarp。它們的區別主要是底層實現協議的不同。其中InfiniBand需要依賴於專用的InfiniBand網路,因此可以提供非常好的服務質量,而RoCE和iWarp則可以基於乙太網絡,並使用專用的RDMA NIC和Switch來實現高服務質量。
RoCE的兩個版本中,v2依賴於UDP/IP協議提供了在區域網中靈活的路由和擁塞控制功能;iWarp則是基於TCP協議提供了更加靈活的網路互聯方式。

在各種RDMA中,定義了硬體操作的基本原語。在軟體層面,需要執行RDMA操作的命令按照硬體制定的方式組織成命令請求項,並新增到位於記憶體中的工作佇列中。
硬體再依次從這些佇列中取出命令開始執行;命令的執行結果會記錄到一個完成佇列中,這個完成佇列也是處於記憶體中的,因此可以為軟體層面感知到併進行後續處理。
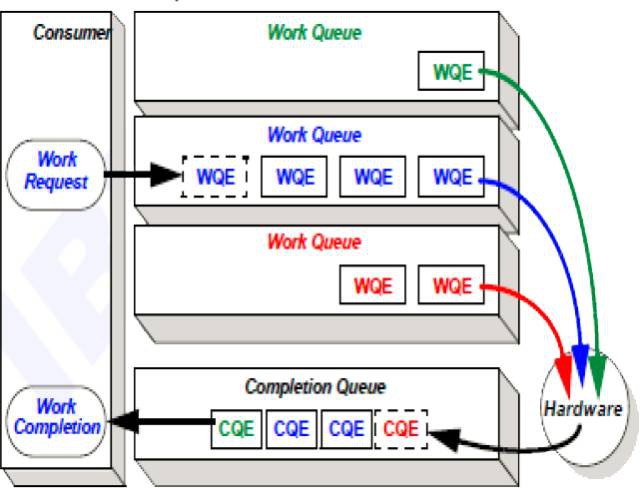
由於RDMA底層實現可以使用任意一中介面方式實現詳盡的功能,在每種協議背後又有眾多的廠商支援,為了統一應用介面,便於軟體開發人員理解和使用RDMA,每種RDMA協議定義了Verbs用於非同步操作實現RDMA的語意。Verbs是一種比API更加底層的程式設計方式,根據使用方式的不同,可分為兩類:
- 控制路徑Verbs,用於管理RDMA的資源,通常需要背景關係切換。例如Create,Destroy,Modify,Query,Work with events;
- 資料路徑Verbs,用於使用Handle來傳送、接收資料的操作,不需要背景關係切換。例如Post Send,Post Receive,Poll CQ,Request for completion event;
- 對於RDMA至關重要的遠端記憶體空間,在RDMA協議中是透過記憶體區域(MR)來進行描述。定義記憶體區域實際上就是把這個虛擬記憶體鎖定到物理記憶體中,並告訴NIC對應的關係。這樣,依據MR的Key,NIC硬體可以不依賴硬體去運算元據在本地記憶體和遠端的MR之間進行傳輸。
從上面關於RDMA的介紹來看,RDMA設計初衷就是為了高效能、低延遲訪問遠端節點的,並且它的語意非常類似本地DMA的過程,因此很自然就可以將RDMA作為NVMe協議的載體,實現基於網路的NVMe協議。
但是,畢竟基於網路的傳輸模型與本地的PCIe傳輸模型還有種種差異,因此將NVMe協議拓展到互聯層面需要解決一系列問題。因此,綜合RDMA,FC等等各種不同傳輸層協議的特點,NVM Express Inc.提出了NVMe over Fabrics協議實現了一個完整的網路高效儲存協議。
需要註意的是,NVMe over Fabrics協議的基礎是NVMe Base specification,目前特指的版本是NVM Express revision 1.2.1。在下篇文章中將對NVMe over Fabrics要解決的問題及協議規範下IO的傳輸過程等話題進行詳細介紹。
