

嘗試登入

如果你們學校教務系統不使用Cookie則會是這樣
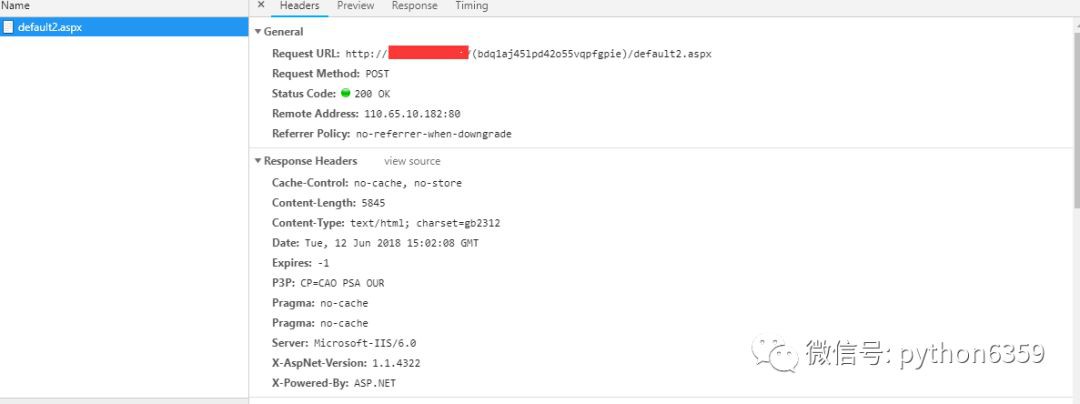
我們可以發現真實的地址是這樣的
http://110.65.10.xxx/(bdq1aj45lpd42o55vqpfgpie)/default2.aspx
如果你們學校教務系統使用Cookie則會是這樣伺服器會傳回一個Cookie值,然後在本地儲存,這與下麵的會不相同。

獲取會話資訊(不使用Cookie)
class Spider:
def __init__(self, url):
self.__uid = ''
self.__real_base_url = ''
self.__base_url = url
self.__essay-headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36',
}
def __set_real_url(self):
request = requests.get(self.__base_url, essay-headers=self.__essay-headers)
real_url = request.url
self.__real_base_url = real_url[:len(real_url) - len('default2.aspx')]
return request
獲取會話資訊(使用Cookie)
def get_cookie():
request = requests.get('http://xxx.xxx.xxx.xxx') #以某教務系統為例子
cookie = requets.cookie
return cookie
def use_cookie(cookie):
request = requests.get('http://xxx.xxx.xxx.xxx',cookie=cookie)
def __init__(self):
self.session = requests.Session()
然後我們首先訪問一次網站即可獲取Cookie並且儲存
def get(self):
r = self.session.get(url,essay-headers=essay-headers)
驗證碼的處理
def __get_code(self):
request = requests.get(self.__real_base_url + 'CheckCode.aspx', essay-headers=self.__essay-headers)
with open('code.jpg', 'wb')as f:
f.write(request.content)
im = Image.open('code.jpg')
im.show()
print('Please input the code:')
code = input()
return code
登入資料的構造



def __get_login_data(self, uid, password):
self.__uid = uid
request = self.__set_real_url()
soup = BeautifulSoup(request.text, 'lxml')
form_tag = soup.find('input')
__VIEWSTATE = form_tag['value']
code = self.__get_code()
data = {
'__VIEWSTATE': __VIEWSTATE,
'txtUserName': self.__uid,
'TextBox2': password,
'txtSecretCode': code,
'RadioButtonList1': '學生'.encode('gb2312'),
'Button1': '',
'lbLanguage': '',
'hidPdrs': '',
'hidsc': '',
}
return data
登入
def login(self,uid,password):
while True:
data = self.__get_login_data(uid, password)
request = requests.post(self.__real_base_url + 'default2.aspx', essay-headers=self.__essay-headers, data=data)
soup = BeautifulSoup(request.text, 'lxml')
try:
name_tag = soup.find(id='xhxm')
self.__name = name_tag.string[:len(name_tag.string) - 2]
print('歡迎'+self.__name)
except:
print('Unknown Error,try to login again.')
time.sleep(0.5)
continue
finally:
return True
獲取選課資訊



def __enter_lessons_first(self):
data = {
'xh': self.__uid,
'xm': self.__name.encode('gb2312'),
'gnmkdm': 'N121103',
}
self.__essay-headers['Referer'] = self.__real_base_url + 'xs_main.aspx?xh=' + self.__uid
request = requests.get(self.__real_base_url + 'xf_xsqxxxk.aspx', params=data, essay-headers=self.__essay-headers)
self.__essay-headers['Referer'] = request.url
soup = BeautifulSoup(request.text, 'lxml')
self.__set__VIEWSTATE(soup)
模擬選課



def __set__VIEWSTATE(self, soup):
__VIEWSTATE_tag = soup.find('input', attrs={'name': '__VIEWSTATE'})
self.__base_data['__VIEWSTATE'] = __VIEWSTATE_tag['value']
self.__base_data = {
'__EVENTTARGET': '',
'__EVENTARGUMENT': '',
'__VIEWSTATE': '',
'ddl_kcxz': '',
'ddl_ywyl': '',
'ddl_kcgs': '',
'ddl_xqbs': '2',
'ddl_sksj': '',
'TextBox1': '',
'dpkcmcGrid:txtChoosePage': '1',
'dpkcmcGrid:txtPageSize': '200',
}

kcmcGrid:_ctl2:xk:'on'
搜尋課程
class Lesson:
def __init__(self, name, code, teacher_name, Time, number):
self.name = name
self.code = code
self.teacher_name = teacher_name
self.time = Time
self.number = number
def show(self):
print('name:' + self.name + 'code:' + self.code + 'teacher_name:' + self.teacher_name + 'time:' + self.time)
有了這個類,我們就可以進行搜尋課程了,具體程式碼看下麵程式碼,解析網頁內容就不細講了。
def __search_lessons(self, lesson_name=''):
self.__base_data['TextBox1'] = lesson_name.encode('gb2312')
request = requests.post(self.__essay-headers['Referer'], data=self.__base_data, essay-headers=self.__essay-headers)
soup = BeautifulSoup(request.text, 'lxml')
self.__set__VIEWSTATE(soup)
return self.__get_lessons(soup)
def __get_lessons(self, soup):
lesson_list = []
lessons_tag = soup.find('table', id='kcmcGrid')
lesson_tag_list = lessons_tag.find_all('tr')[1:]
for lesson_tag in lesson_tag_list:
td_list = lesson_tag.find_all('td')
code = td_list[0].input['name']
name = td_list[1].string
teacher_name = td_list[3].string
Time = td_list[4]['title']
number = td_list[10].string
lesson = self.Lesson(name, code, teacher_name, Time, number)
lesson_list.append(lesson)
return lesson_list
進行選課
def __select_lesson(self, lesson_list):
data = copy.deepcopy(self.__base_data)
data['Button1'] = ' 提交 '.encode('gb2312')
for lesson in lesson_list:
code = lesson.code
data[code] = 'on'
request = requests.post(self.__essay-headers['Referer'], data=data, essay-headers=self.__essay-headers)
soup = BeautifulSoup(request.text, 'lxml')
self.__set__VIEWSTATE(soup)
error_tag = soup.html.head.script
if not error_tag is None:
error_tag_text = error_tag.string
r = "alert\('(.+?)'\);"
for s in re.findall(r, error_tag_text):
print(s)
print('已選課程:')
selected_lessons_pre_tag = soup.find('legend', text='已選課程')
selected_lessons_tag = selected_lessons_pre_tag.next_sibling
tr_list = selected_lessons_tag.find_all('tr')[1:]
for tr in tr_list:
td = tr.find('td')
print(td.string)
總結
完整程式碼
import requests
from PIL import Image
from bs4 import BeautifulSoup
import copy
import time
import re
import os
class Spider:
class Lesson:
def __init__(self, name, code, teacher_name, Time, number):
self.name = name
self.code = code
self.teacher_name = teacher_name
self.time = Time
self.number = number
def show(self):
print(' name:' + self.name + ' code:' + self.code + ' teacher_name:' + self.teacher_name + ' time:' + self.time)
def __init__(self, url):
self.__uid = ''
self.__real_base_url = ''
self.__base_url = url
self.__name = ''
self.__base_data = {
'__EVENTTARGET': '',
'__EVENTARGUMENT': '',
'__VIEWSTATE': '',
'ddl_kcxz': '',
'ddl_ywyl': '',
'ddl_kcgs': '',
'ddl_xqbs': '',
'ddl_sksj': '',
'TextBox1': '',
'dpkcmcGrid:txtChoosePage': '1',
'dpkcmcGrid:txtPageSize': '200',
}
self.__essay-headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/67.0.3396.62 Safari/537.36',
}
self.session = requests.Session()
self.__now_lessons_number = 0
def __set_real_url(self):
request = self.session.get(self.__base_url, essay-headers=self.__essay-headers)
real_url = request.url
if real_url != 'http://218.75.197.123:83/' and real_url != 'http://218.75.197.123:83/index.apsx': # 湖南工業大學
self.__real_base_url = real_url[:len(real_url) - len('default2.aspx')]
else:
if real_url.find('index') > 0:
self.__real_base_url = real_url[:len(real_url) - len('index.aspx')]
else:
self.__real_base_url = real_url
return request
def __get_code(self):
if self.__real_base_url != 'http://218.75.197.123:83/':
request = self.session.get(self.__real_base_url + 'CheckCode.aspx', essay-headers=self.__essay-headers)
else:
request = self.session.get(self.__real_base_url + 'CheckCode.aspx?', essay-headers=self.__essay-headers)
with open('code.jpg', 'wb')as f:
f.write(request.content)
im = Image.open('code.jpg')
im.show()
print('Please input the code:')
code = input()
return code
def __get_login_data(self, uid, password):
self.__uid = uid
request = self.__set_real_url()
soup = BeautifulSoup(request.text, 'lxml')
form_tag = soup.find('input')
__VIEWSTATE = form_tag['value']
code = self.__get_code()
data = {
'__VIEWSTATE': __VIEWSTATE,
'txtUserName': self.__uid,
'TextBox2': password,
'txtSecretCode': code,
'RadioButtonList1': '學生'.encode('gb2312'),
'Button1': '',
'lbLanguage': '',
'hidPdrs': '',
'hidsc': '',
}
return data
def login(self, uid, password):
while True:
data = self.__get_login_data(uid, password)
if self.__real_base_url != 'http://218.75.197.123:83/':
request = self.session.post(self.__real_base_url + 'default2.aspx', essay-headers=self.__essay-headers, data=data)
else:
request = self.session.post(self.__real_base_url + 'index.aspx', essay-headers=self.__essay-headers, data=data)
soup = BeautifulSoup(request.text, 'lxml')
if request.status_code != requests.codes.ok:
print('4XX or 5XX Error,try to login again')
time.sleep(0.5)
continue
if request.text.find('驗證碼不正確') > -1:
print('Code error,please input again')
continue
if request.text.find('密碼錯誤') > -1:
print('Password may be error')
return False
if request.text.find('使用者名稱不存在') > -1:
print('Uid may be error')
return False
try:
name_tag = soup.find(id='xhxm')
self.__name = name_tag.string[:len(name_tag.string) - 2]
print('歡迎' + self.__name)
self.__enter_lessons_first()
return True
except:
print('Unknown Error,try to login again.')
time.sleep(0.5)
continue
def __enter_lessons_first(self):
data = {
'xh': self.__uid,
'xm': self.__name.encode('gb2312'),
'gnmkdm': 'N121103',
}
self.__essay-headers['Referer'] = self.__real_base_url + 'xs_main.aspx?xh=' + self.__uid
request = self.session.get(self.__real_base_url + 'xf_xsqxxxk.aspx', params=data, essay-headers=self.__essay-headers)
self.__essay-headers['Referer'] = request.url
soup = BeautifulSoup(request.text, 'lxml')
self.__set__VIEWSTATE(soup)
selected_lessons_pre_tag = soup.find('legend', text='已選課程')
selected_lessons_tag = selected_lessons_pre_tag.next_sibling
tr_list = selected_lessons_tag.find_all('tr')[1:]
self.__now_lessons_number = len(tr_list)
try:
xq_tag = soup.find('select', id='ddl_xqbs')
self.__base_data['ddl_xqbs'] = xq_tag.find('option')['value']
except:
pass
def __set__VIEWSTATE(self, soup):
__VIEWSTATE_tag = soup.find('input', attrs={'name': '__VIEWSTATE'})
self.__base_data['__VIEWSTATE'] = __VIEWSTATE_tag['value']
def __get_lessons(self, soup):
lesson_list = []
lessons_tag = soup.find('table', id='kcmcGrid')
lesson_tag_list = lessons_tag.find_all('tr')[1:]
for lesson_tag in lesson_tag_list:
td_list = lesson_tag.find_all('td')
code = td_list[0].input['name']
name = td_list[1].string
teacher_name = td_list[3].string
Time = td_list[4]['title']
number = td_list[10].string
lesson = self.Lesson(name, code, teacher_name, Time, number)
lesson_list.append(lesson)
return lesson_list
def __search_lessons(self, lesson_name=''):
self.__base_data['TextBox1'] = lesson_name.encode('gb2312')
request = self.session.post(self.__essay-headers['Referer'], data=self.__base_data, essay-headers=self.__essay-headers)
soup = BeautifulSoup(request.text, 'lxml')
self.__set__VIEWSTATE(soup)
return self.__get_lessons(soup)
def __select_lesson(self, lesson_list):
data = copy.deepcopy(self.__base_data)
data['Button1'] = ' 提交 '.encode('gb2312')
for lesson in lesson_list:
code = lesson.code
data[code] = 'on'
request = self.session.post(self.__essay-headers['Referer'], data=data, essay-headers=self.__essay-headers)
soup = BeautifulSoup(request.text, 'lxml')
self.__set__VIEWSTATE(soup)
error_tag = soup.html.head.script
if not error_tag is None:
error_tag_text = error_tag.string
r = "alert\('(.+?)'\);"
for s in re.findall(r, error_tag_text):
print(s)
print('已選課程:')
selected_lessons_pre_tag = soup.find('legend', text='已選課程')
selected_lessons_tag = selected_lessons_pre_tag.next_sibling
tr_list = selected_lessons_tag.find_all('tr')[1:]
self.__now_lessons_number = len(tr_list)
for tr in tr_list:
td = tr.find('td')
print(td.string)
def run(self):
print('請輸入搜尋課程名字')
lesson_name = input()
lesson_list = self.__search_lessons(lesson_name)
print('請輸入想選的課的id,id為每門課程開頭的數字,如果沒有課程顯示,代表公選課暫無')
for i in range(len(lesson_list)):
print(i, end='')
lesson_list[i].show()
select_id = int(input())
lesson_list = lesson_list[select_id:select_id + 1]
while True:
try:
number = self.__now_lessons_number
self.__select_lesson(lesson_list)
if self.__now_lessons_number > number:
break
except:
print("搶課失敗,休息0.5秒後繼續")
time.sleep(0.5)
if __name__ == '__main__':
print('請輸入你們學校教務系統的地址,不用加上前面的http://')
url = input()
url = 'http://' + url
spider = Spider(url)
print('請輸入學號')
uid = input() #學號
print('請輸入密碼')
password = input() #密碼
if (spider.login(uid, password)):
spider.run()
os.system("pause")

