
作者:舞鶴
來源:見文末
序
本文主要內容:以最短的時間寫一個最簡單的爬蟲,可以抓取論壇的帖子標題和帖子內容。
本文受眾:沒寫過爬蟲的萌新。
入門
0.準備工作
需要準備的東西: Python、scrapy、一個IDE或者隨便什麼文字編輯工具。
1.技術部已經研究決定了,你來寫爬蟲。
隨便建一個工作目錄,然後用命令列建立一個工程,工程名為miao,可以替換為你喜歡的名字。
scrapy startproject miao隨後你會得到如下的一個由scrapy建立的目錄結構

在spiders檔案夾中建立一個python檔案,比如miao.py,來作為爬蟲的指令碼。
內容如下:
import scrapy
class NgaSpider(scrapy.Spider):
name = "NgaSpider"
host = "http://bbs.ngacn.cc/"
# start_urls是我們準備爬的初始頁
start_urls = [
"http://bbs.ngacn.cc/thread.php?fid=406",
]
# 這個是解析函式,如果不特別指明的話,scrapy抓回來的頁面會由這個函式進行解析。
# 對頁面的處理和分析工作都在此進行,這個示例裡我們只是簡單地把頁面內容打印出來。
def parse(self, response):
print response.body2.跑一個試試?
如果用命令列的話就這樣:
cd miao
scrapy crawl NgaSpider你可以看到爬蟲君已經把你壇星際區第一頁打印出來了,當然由於沒有任何處理,所以混雜著html標簽和js指令碼都一併打印出來了。
解析
接下來我們要把剛剛抓下來的頁面進行分析,從這坨html和js堆裡把這一頁的帖子標題提煉出來。
其實解析頁面是個體力活,方法多的是,這裡只介紹xpath。
0.為什麼不試試神奇的xpath呢
看一下剛才抓下來的那坨東西,或者用chrome瀏覽器手動開啟那個頁面然後按F12可以看到頁面結構。
每個標題其實都是由這麼一個html標簽包裹著的。舉個例子:
<a id="t_tt1_33" class="topic" href="/read.php?tid=10803874">[合作樣式] 合作樣式修改設想a>可以看到href就是這個帖子的地址(當然前面要拼上論壇地址),而這個標簽包裹的內容就是帖子的標題了。
於是我們用xpath的絕對定位方法,把class=’topic’的部分摘出來。
1.看看xpath的效果
在最上面加上取用:
from scrapy import Selector把parse函式改成:
def parse(self, response):
selector = Selector(response)
# 在此,xpath會將所有class=topic的標簽提取出來,當然這是個list
# 這個list裡的每一個元素都是我們要找的html標簽
content_list = selector.xpath("//*[@class='topic']")
# 遍歷這個list,處理每一個標簽
for content in content_list:
# 此處解析標簽,提取出我們需要的帖子標題。
topic = content.xpath('string(.)').extract_first()
print topic
# 此處提取出帖子的url地址。
url = self.host + content.xpath('@href').extract_first()
print url再次執行就可以看到輸出你壇星際區第一頁所有帖子的標題和url了。
遞迴
接下來我們要抓取每一個帖子的內容。
這裡需要用到python的yield。
yield Request(url=url, callback=self.parse_topic)此處會告訴scrapy去抓取這個url,然後把抓回來的頁面用指定的parse_topic函式進行解析。
至此我們需要定義一個新的函式來分析一個帖子裡的內容。
完整的程式碼如下:
import scrapy
from scrapy import Selector
from scrapy import Request
class NgaSpider(scrapy.Spider):
name = "NgaSpider"
host = "http://bbs.ngacn.cc/"
# 這個例子中只指定了一個頁面作為爬取的起始url
# 當然從資料庫或者檔案或者什麼其他地方讀取起始url也是可以的
start_urls = [
"http://bbs.ngacn.cc/thread.php?fid=406",
]
# 爬蟲的入口,可以在此進行一些初始化工作,比如從某個檔案或者資料庫讀入起始url
def start_requests(self):
for url in self.start_urls:
# 此處將起始url加入scrapy的待爬取佇列,並指定解析函式
# scrapy會自行排程,並訪問該url然後把內容拿回來
yield Request(url=url, callback=self.parse_page)
# 版面解析函式,解析一個版面上的帖子的標題和地址
def parse_page(self, response):
selector = Selector(response)
content_list = selector.xpath("//*[@class='topic']")
for content in content_list:
topic = content.xpath('string(.)').extract_first()
print topic
url = self.host + content.xpath('@href').extract_first()
print url
# 此處,將解析出的帖子地址加入待爬取佇列,並指定解析函式
yield Request(url=url, callback=self.parse_topic)
# 可以在此處解析翻頁資訊,從而實現爬取版區的多個頁面
# 帖子的解析函式,解析一個帖子的每一樓的內容
def parse_topic(self, response):
selector = Selector(response)
content_list = selector.xpath("//*[@class='postcontent ubbcode']")
for content in content_list:
content = content.xpath('string(.)').extract_first()
print content
# 可以在此處解析翻頁資訊,從而實現爬取帖子的多個頁面到此為止,這個爬蟲可以爬取你壇第一頁所有的帖子的標題,並爬取每個帖子裡第一頁的每一層樓的內容。
爬取多個頁面的原理相同,註意解析翻頁的url地址、設定終止條件、指定好對應的頁面解析函式即可。
Pipelines——管道
此處是對已抓取、解析後的內容的處理,可以透過管道寫入本地檔案、資料庫。
0.定義一個Item
在miao檔案夾中建立一個items.py檔案。
from scrapy import Item, Field
class TopicItem(Item):
url = Field()
title = Field()
author = Field()
class ContentItem(Item):
url = Field()
content = Field()
author = Field()此處我們定義了兩個簡單的class來描述我們爬取的結果。
1. 寫一個處理方法
在miao檔案夾下麵找到那個pipelines.py檔案,scrapy之前應該已經自動生成好了。
我們可以在此建一個處理方法。
from scrapy import Item, Field
class TopicItem(Item):
url = Field()
title = Field()
author = Field()
class ContentItem(Item):
url = Field()
content = Field()
author = Field()2.在爬蟲中呼叫這個處理方法。
要呼叫這個方法我們只需在爬蟲中呼叫即可,例如原先的內容處理函式可改為:
def parse_topic(self, response):
selector = Selector(response)
content_list = selector.xpath("//*[@class='postcontent ubbcode']")
for content in content_list:
content = content.xpath('string(.)').extract_first()
## 以上是原內容
## 建立個ContentItem物件把我們爬取的東西放進去
item = ContentItem()
item["url"] = response.url
item["content"] = content
item["author"] = "" ## 略
## 這樣呼叫就可以了
## scrapy會把這個item交給我們剛剛寫的FilePipeline來處理
yield item3.在配置檔案裡指定這個pipeline
找到settings.py檔案,在裡面加入
ITEM_PIPELINES = {
'miao.pipelines.FilePipeline': 400,
}這樣在爬蟲裡呼叫
yield item的時候都會由經這個FilePipeline來處理。後面的數字400表示的是優先順序。
可以在此配置多個Pipeline,scrapy會根據優先順序,把item依次交給各個item來處理,每個處理完的結果會傳遞給下一個pipeline來處理。
可以這樣配置多個pipeline:
ITEM_PIPELINES = {
'miao.pipelines.Pipeline00': 400,
'miao.pipelines.Pipeline01': 401,
'miao.pipelines.Pipeline02': 402,
'miao.pipelines.Pipeline03': 403,
## ...
}Middleware——中介軟體
透過Middleware我們可以對請求資訊作出一些修改,比如常用的設定UA、代理、登入資訊等等都可以透過Middleware來配置。
0.Middleware的配置
與pipeline的配置類似,在setting.py中加入Middleware的名字,例如
DOWNLOADER_MIDDLEWARES = {
"miao.middleware.UserAgentMiddleware": 401,
"miao.middleware.ProxyMiddleware": 402,
}1.破網站查UA, 我要換UA
某些網站不帶UA是不讓訪問的。
在miao檔案夾下麵建立一個middleware.py
import random
agents = [
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/532.5 (KHTML, like Gecko) Chrome/4.0.249.0 Safari/532.5",
"Mozilla/5.0 (Windows; U; Windows NT 5.2; en-US) AppleWebKit/532.9 (KHTML, like Gecko) Chrome/5.0.310.0 Safari/532.9",
"Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US) AppleWebKit/534.7 (KHTML, like Gecko) Chrome/7.0.514.0 Safari/534.7",
"Mozilla/5.0 (Windows; U; Windows NT 6.0; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/9.0.601.0 Safari/534.14",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.14 (KHTML, like Gecko) Chrome/10.0.601.0 Safari/534.14",
"Mozilla/5.0 (Windows; U; Windows NT 6.1; en-US) AppleWebKit/534.20 (KHTML, like Gecko) Chrome/11.0.672.2 Safari/534.20",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/534.27 (KHTML, like Gecko) Chrome/12.0.712.0 Safari/534.27",
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/535.1 (KHTML, like Gecko) Chrome/13.0.782.24 Safari/535.1",
]
class UserAgentMiddleware(object):
def process_request(self, request, spider):
agent = random.choice(agents)
request.essay-headers["User-Agent"] = agent這裡就是一個簡單的隨機更換UA的中介軟體,agents的內容可以自行擴充。
2.破網站封IP,我要用代理
比如本地127.0.0.1開啟了一個8123埠的代理,同樣可以透過中介軟體配置讓爬蟲透過這個代理來對標的網站進行爬取。
同樣在middleware.py中加入:
class ProxyMiddleware(object):
def process_request(self, request, spider):
# 此處填寫你自己的代理
# 如果是買的代理的話可以去用API獲取代理串列然後隨機選擇一個
proxy = "http://127.0.0.1:8123"
request.meta["proxy"] = proxy很多網站會對訪問次數進行限制,如果訪問頻率過高的話會臨時禁封IP。
如果需要的話可以從網上購買IP,一般服務商會提供一個API來獲取當前可用的IP池,選一個填到這裡就好。
一些常用配置
在settings.py中的一些常用配置
# 間隔時間,單位秒。指明scrapy每兩個請求之間的間隔。
DOWNLOAD_DELAY = 5
# 當訪問異常時是否進行重試
RETRY_ENABLED = True
# 當遇到以下http狀態碼時進行重試
RETRY_HTTP_CODES = [500, 502, 503, 504, 400, 403, 404, 408]
# 重試次數
RETRY_TIMES = 5
# Pipeline的併發數。同時最多可以有多少個Pipeline來處理item
CONCURRENT_ITEMS = 200
# 併發請求的最大數
CONCURRENT_REQUESTS = 100
# 對一個網站的最大併發數
CONCURRENT_REQUESTS_PER_DOMAIN = 50
# 對一個IP的最大併發數
CONCURRENT_REQUESTS_PER_IP = 50我就是要用Pycharm
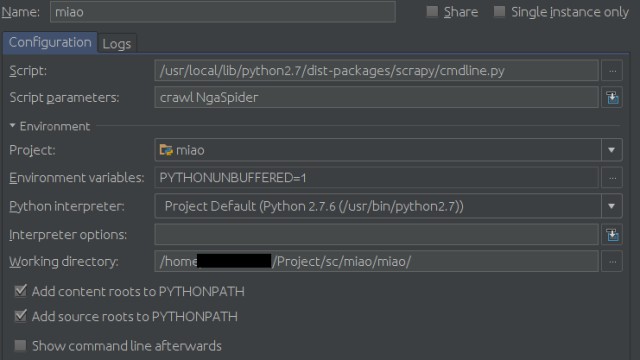
如果非要用Pycharm作為開發除錯工具的話可以在執行配置裡進行如下配置:
Configuration頁面:
Script填你的scrapy的cmdline.py路徑,比如我的是
/usr/local/lib/python2.7/dist-packages/scrapy/cmdline.py然後在Scrpit parameters中填爬蟲的名字,本例中即為:
crawl NgaSpider最後是Working diretory,找到你的settings.py檔案,填這個檔案所在的目錄。
示例:
按小綠箭頭就可以愉快地除錯了。
參考
這裡提供了對scrapy非常詳細的介紹。
http://scrapy-chs.readthedocs.io/zh_CN/0.24/
以下是幾個比較重要的地方:
scrapy的架構:
http://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/architecture.html
xpath語法:
http://www.w3school.com.cn/xpath/xpath_syntax.asp
Pipeline管道配置:
http://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/item-pipeline.html
Middleware中介軟體的配置:
http://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/downloader-middleware.html
settings.py的配置:
http://scrapy-chs.readthedocs.io/zh_CN/0.24/topics/settings.html
作者:舞鶴
來源:見文末https://segmentfault.com/a/1190000008135000
轉載自:Python那些事
《Python人工智慧和全棧開發》2018年07月23日即將在北京開課,120天衝擊Python年薪30萬,改變速約~~~~
*宣告:推送內容及圖片來源於網路,部分內容會有所改動,版權歸原作者所有,如來源資訊有誤或侵犯權益,請聯絡我們刪除或授權事宜。
– END –


更多Python好文請點選【閱讀原文】哦
↓↓↓
