百度性感美女桌布瞭解一下

看到這個圖片,有沒有一種………emmmmm…….刺激、興奮的感覺。
不管你們有沒有 反正小編我是有一股衝勁的,自從知道了Python爬蟲之後,只要看到有妹子的照片的網站,我就是想要批次下載一下!
不為別的,是為了能更好的學習Python! 我這樣說你們信嗎?

給程式碼 給程式碼 好東西 必須分享 大家一起享受!
# !/usr/bin/env python
# -*- coding:utf-8 -*-
import requests
import json
# 定義一個請求函式,接收頁面引數
def get_page(page):
# 把頁面引數新增在url的字串當中
url = 'https://image.baidu.com/search/acjson?tn=resultjson_com&ipn;=rj&ct;=201326592&is;=&fp;=result&queryWord;=美女&cl;=2&lm;=-1&ie;=utf-8&oe;=utf-8&adpicid;=&st;=-1&z;==0&word;=美女&s;=&se;=&tab;=&width;=&height;=&face;=0&istype;=2&qc;=&nc;=1&fr;=&cg;=girl&pn;={}&rn;=30&gsm;=1e'.format(
page)
# 請求網站,並且得到網站的響應
response = requests.get(url)
# 判斷狀態的狀況
if response.status_code == 200:
# 傳迴文字檔案資訊
return response.text
def json_load(text):
# 把文字檔案處理成字典格式
jsondict = json.loads(text)
# 建立一個空的合集,作用是去重
urlset = set()
# 檢查字典裡面是否包含了data這個值
if 'data' in jsondict.keys():
# 從jsondict中取出data這個字典裡面的東西,依次賦值給items!
for items in jsondict.get('data'):
# 異常處理,不是每一行資料都包含thumbURL這個資料的
try:
urlset.add(items['thumbURL'])
except:
pass
return urlset
def down_cont(url):
response = requests.get(url)
name = url.split(',')[-1].split('&')[0]
if response.status_code == 200:
# 表示,如果檔案名字相同,就刪除當前檔案,然後再建立一個一樣名字的檔案
with open('./images/%s.jpg' % name, 'wb') as f:
print('正在下載當前圖片: ' + url)
# 以二進位制的方法寫入到本地
f.write(response.content)
def main():
for p in range(5):
print('正在下載 %s頁 的圖片' % p)
page = p * 30
text = get_page(page)
urlset = json_load(text)
for url in urlset:
down_cont(url)
if __name__ == '__main__':
main()
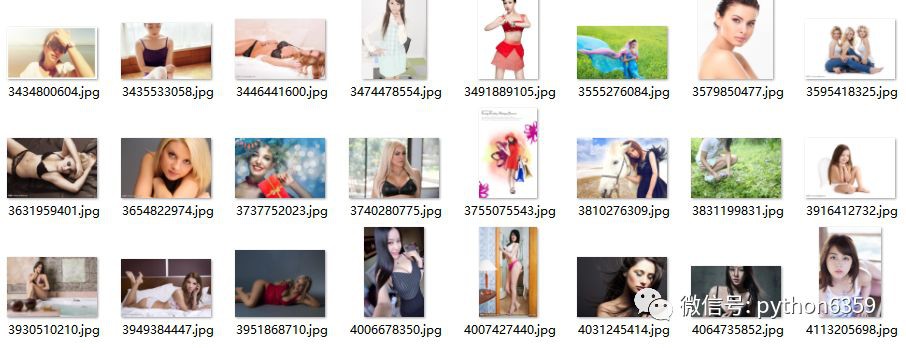
執行效果圖