Byte Tech 2019由中國人工智慧學會、位元組跳動、清華大學聯合主辦,清華大學資料科學研究院協辦。
微信公眾號後臺對話方塊回覆個性化推薦,可獲取張教授演講完整版PPT。
作者:張敏
來源:資料派THU(ID:DatapiTHU)
01 可解釋性
大家好,今天和大家分享一下個性化推薦研究進展。主要探討三個關鍵詞:可解釋性、魯棒性和公平性。我們大概2013年左右就開始做可解釋的推薦,此後也開始逐漸研究魯棒性和公平性。為什麼這三個詞很重要呢?

▲可解釋性、魯棒性和公平性是人工智慧目前面對的三個重要挑戰
可能大家對人工智慧的發展非常耳熟能詳。的確,在這次人工智慧熱潮開始之後,人們認為人工智慧越來越強大。但對很多從事人工智慧研究的學者來說,現在更多想的是人工智慧在哪些地方遇到了最大的瓶頸。
目前大家基本達成了共識:當前人工智慧領域的兩個核心的挑戰是可解釋性和魯棒性。
除了可解釋性和魯棒性之外,從兩三年前開始,國外的研究越來越關註第三個問題:公平性。我們在研究過程中發現,可解釋性、魯棒性和公平性這三點並不是完全割裂的。
所以今天的報告既會分別討論這三點,但也試圖呈現它們之間的關聯。因為這三個話題很大,所以我們用一個具體的領域來討論,也就是我們課題組這些年一直在研究的個性化推薦。
首先是可解釋性。什麼叫可解釋性?其實很簡單。我們除了知道怎麼做一件事,怎麼完成一個任務之外,還想知道“為什麼”。這個“為什麼”其實有兩個不同角度。
首先從使用者的角度來說,我們不僅希望給使用者看到推薦的結果,例如線上購物網站呈現的推薦商品,還能告訴使用者為什麼推薦這個商品。另一個例子是新聞推薦。
為什麼系統從今天的幾百條新聞中給使用者推了這些內容。我們需要理由,並且要把這個理由解釋給使用者。這就是結果的可解釋性。第二個方面是系統角度的可解釋性,也就是系統開發人員需要的解釋。
在我們實驗室的研究過程中,有時候學生對我說這個結果很好或很不好,他們可能很怕我問一個問題:為什麼結果會這樣?為什麼我們方法的效果比別人的好?如果不好,問題出在哪裡?特別的,到底是哪些因素/特徵/資料帶來了問題,有沒有可能改進?這是關於系統的可解釋性。
在現在的人工智慧(特別是深度學習)研究中,大家對解釋性機器學習探討得比較多。很多人說深度學習的缺點是不知道結果是怎麼給出來的,就是指缺少系統的可解釋性。
我們現在先討論一下麵向用戶的可解釋性。之後在討論魯棒性問題時會提到系統的可解釋性。
目前推薦系統已經有了非常廣泛的應用。大家一定用過推薦系統,無論是新聞閱讀資訊流還是線上購物等。現在推薦系統給出的理由非常簡單,最常見的理由之一是買了某件商品的使用者也買了其他什麼東西,然後說“你可能也感興趣…”。
事實上,現在推薦系統沒有給出更有說服力的推薦理由的原因,並不是不想給,而是給不出來。為什麼呢?我們從推薦演演算法說起。這裡我簡單介紹一下基本概念,儘量讓沒有推薦系統背景的朋友也能理解。
02 推薦系統簡明原理
在推薦系統技術中,協同過濾是一個很常用也很有效的辦法。在協同過濾技術中,我們經常會看到類似下圖所示的矩陣。這個矩陣中記錄了某個使用者是否買了什麼商品,這時系統根據買了同一個商品的人,還買過什麼其他商品,來產生推薦的商品候選。
但系統並不是直接查矩陣就把結果推出來了。人們會把這個矩陣分解成兩部分:一部分是使用者,另一部分是商品。這兩個部分的隱變數會共享相同的維度,對接使用者和商品,把它們對映到同一個空間上。這就是常用的隱變數分解機模型。
事實上,給你推薦這個商品的真正理由可能是,在你的第三個、第十個、第十二個維度代表的向量上,你的喜好和被推薦商品的這三個維度代表的向量非常匹配。
但如果系統告訴使用者說,“我把這個商品推薦給你,是因為你在第十二維上的特徵和商品的第十二維很匹配”,使用者可能會覺得莫名其妙。

▲分解機模型可以用來協助基於協同過濾方法的推薦系統的實現
所以我們想知道,到底有沒有一種方法,既可以給出精準的推薦,同時還能給出可靠的解釋。於是人們開始在這個方向做一些嘗試。我們在2014年左右提出了Explainable Recommendation這個概念。
後來也有不少人在這個方向做了相關研究,我們提出的EFM模型也成為了大家做可解釋推薦時經常用來比較的baseline方法。當時的思路就是,雖然中間的隱變數是不可解釋的,但如果找到中間橋梁——這個橋梁就是具體的特徵,比如商品的特性——那麼推薦的結果就能被解釋。
例如,系統在推薦一個手機的時候,會解釋說這款手機拍照效能好,外觀漂亮。這樣可能會比較適合一個時尚的女孩。
如果系統發現其他使用者感興趣的是另外的特徵,就能找到別的合適的手機來推薦,例如把一款螢幕大、字型大、操作簡單、待機時間長的手機推薦給你,而你正在給父母買一款智慧老人機,你就很可能會被說服。
我們用了這種方法後,可以把使用者點選率從3%到4%,這是非常大的提升。
人們可能會問:“也許我們不需要理由呢?”所以我們用線上購物網站真實的資料做了實驗來分析這樣的解釋到底有沒有效果。
-
第一組實驗直接給推薦結果,沒有解釋;
-
第二組給同樣的推薦結果,只是同時給出了“看過這個商品的這個使用者還看了什麼”的簡單解釋,這樣就可以把點選率從3.20%到3.22%;
-
第三,我們給了新的解釋,提供了例如螢幕較大,待機時間較長這樣更具體的資訊,發現點選率又進一步提升到4.34%。
所以真實的使用者實驗告訴我們,只要給出了合理的解釋,推薦精準度會有非常大的提升——有時候人做事情需要別人給我們一個理由。

▲可解釋的推薦演演算法EFM的原理解釋
但是,上述方法也有問題。
首先,並不是所有東西都很容易找出特徵。比如對新聞來說,我們很難描述這個新聞帶有什麼樣的屬性,讓我們可以做類似的處理。
此外,因為人的語言表達很自由,所以自然語言處理表達有非常大的多樣性。比如說有人可能在評論中說“這個東西也沒有明顯的缺點,但是感覺不太好用”。
這種情況很難快速找出完整、精準的特徵描述。所以我們認為也許可以嘗試把粒度提升一點,不在那麼細的粒度上做特徵級別的可解釋性。於是這就給了我們更多的思路。
下圖是亞馬遜購上的評論。大家可能會發現其實除了使用者對商品的評論和打分之外,其他使用者還會對某個使用者的評論打分:分數代表了其他使用者覺得這個評論到底有沒有用。
如果我們對所有商品都找到這樣的有用的評論資訊,當使用者瀏覽購買的時候,我們可以把最有用的評論呈現給使用者,那麼推薦系統影響的不單是購買的結果,還會幫助使用者挑選商品時的早期和中間的選擇決策過程。

▲使用者的評論也可以被其他使用者評論
因此,我們從這個角度做了一些工作。我們首先研究是否可以自動發現評論的有用性。因為網際網路上有一個重要的原則叫“lazy user”,也就是不要指望使用者主動做太多事情。所以願意給出別人的評論是否有用的使用者非常少,資料就很稀疏。
那麼我們系統能不能自己學習出來呢?其次我們在研究有用性的過程中有沒有可能把它與最終的推薦演演算法結合在一起?而不是僅僅判斷某些評論是否有用卻沒有讓推薦系統利用到這一點。
所以我們設計了下圖中的模型,這是一個基於註意力機制網路(Attention network)的深度學習模型。我們在這個模型中,試圖在最終給出評論推薦的同時,透過中間註意力的機制的選擇,挑出更有用更可靠的評論。
這個工作我們發表在2018年的WWW會議上。模型的效果非常好,與經典的推薦演演算法以及基於深度學習的演演算法等state of art方法相比,我們的模型都會有統計意義上顯著的提升。此外,模型是否考慮Attention,效果會有非常大的差異和變化。如下圖所示。

▲基於Neural Attention Network來給出評論級別的可解釋的推薦演演算法

▲加入了基於attention 機制的可解釋推薦方法,模型的效能得到顯著提升
怎麼看這個模型對使用者是否有效?我們對比了幾種常見的方式。比如現在大多數購物網站主要有以下幾種方式對評論排序:
-
時間排序,最近的評論在前面;
-
隨機排序;
-
排除垃圾評論後按照內容長度排序(因為一般認為越長的評論越有用)。
然而,基於時間和長度的排序往往效果比隨機還要差,而我們提出的方法表現更好。這裡有一點值得註意的是,事實上,我們這個拿來做標準答案的大規模使用者標註的有效性資料,是有偏的(bias)。
因為曾經被人評過有用的東西,會因為馬太效應,更容易被其他人認為有用。而那些事實上有用,但卻沒有機會立刻呈現的評論會永遠沉寂下去。
而這個bias也是我們所說的“不公平性”的情況之一。所以我們做了第三方更客觀的評價,發現這種bias的確存在,而透過演演算法分析找到的方法,比靠使用者在系統中的投票,是更可靠更有效的方法。
在可解釋性方面還有更多要討論的問題,比如應該用產生式的方法還是判別式的方法,我們的觀點是都可以。還有怎麼評價這個解釋的有效性呢?我們覺得一個可行的思路是要和使用者的行為結合在一起。
另外,推薦演演算法可能帶來的偏差怎麼處理?尤其是解釋本身是否帶來不公平性?這也是非常容易存在的一個問題,有可能變成哲學問題。
03 魯棒性問題
第二個要討論的問題,是魯棒性。這個問題涉及到很多方面。在個性化推薦領域,魯棒性問題的具體表現之一是很嚴重的資料缺失的挑戰。我們都知道可以根據使用者的歷史做推薦,但如果一個新使用者什麼歷史都沒有,你要怎麼做推薦呢?這稱作冷啟動(cold-start)問題。
在推薦系統中有一類方法基於協同過濾,還有一類方法是基於內容匹配,前者雖然一般來說效果更好但是無法處理冷啟動情況,而後者即使冷啟動時還能夠工作。我們可以把他們融合起來,用歷史資料學到給這兩種方法分配的權值:例如0.8和0.2。
冷啟動的時候,協同過濾那部分是0,但還至少有0.2權重的基於內容(content-based)的方法能夠使用。但很顯然對不同使用者、不同的商品,這種融合的權值應該是不一樣的。
所以我們提出一個思路(如下圖):我們不要固定選好一個對所有人一樣的權值,而是提出一個統一的框架(unified framework),自動用註意力網路學習出在不同的情況下不一樣的權值。
如果大家感興趣的話,可以看一下我們發表在CIKM 2018上的論文:Attention-based Adaptive Model to Unify Warm and Cold Starts Recommendation。效果確實非常好,能非常有效地解決冷啟動問題,並且對總體效果非常有幫助。

▲統一的框架可以解決冷啟動推薦問題
更有趣的是,當學生把下圖拿給我的時候,我覺得這可以算是個很漂亮的工作了,因為這項工作同時也體現了系統的可解釋性。為什麼剛才提到的模型結果很好呢?這是因為透過學習到的不同Attention,會發現左上角是新的item(例如新商品或新的訊息),右下角是新的使用者。
對於資訊充足的情況和資訊嚴重不足的情況(新的商品+新的使用者),這幅圖都給瞭解釋。所以你會發現,當我們解決魯棒性的同時,對於系統級別的可解釋性也有非常大的改善。

▲提升推薦系統的魯棒性同時也可能提升系統的可解釋性
04 公平性問題
最後我們用很短的時間再探討一下公平性問題。公平性問題很值得註意。
比如2018年的一個研究發現,在兩個公開資料集MovieLens和LastFM上,對男性的推薦效果比對女性推薦效果好,對老人和18歲以下年輕人的推薦效果,比18歲到50歲之間的人群的推薦效果更好,這不是系統有意識地產生偏見,可能和資料量以及使用者習慣有關,但是不公平性的確存在。
另一方面對被推薦物及相關資訊也存在不公平性,例如我們前面討論過的對評論的不公平性,以及更多推薦流行的東西,也會帶來對不熱門的東西的不公平性。
有時候對使用者和對物品的公平性,是有衝突的。例如我們希望增加推薦的多樣性,但是有研究表明,增加多樣性的時候提升了對被推薦物的公平性,但是卻降低了對使用者的公平性。

▲推薦系統對不同人群的效果不同,降低了對使用者和對推薦物的公平性
最後一分鐘時間分享一下我們在使用者行為的不公平性上發現的有趣現象。人們常在看新聞的資訊流時經常說這個文章質量太差了,怎麼給我推薦這些呢?
事實上我們來看看點選率,會吃驚地發現:低質量的新聞總體點選率(下麵左圖中的藍線)始終比高質量新聞點選率(圖中的紅線)高,甚至我們會發現有一些使用者在點選之前其實是知道這條新聞的質量肯定不怎麼樣的,但人們還是有獵奇心理,“我知道它不太好可我就是要點”,點完以後發現這條新聞質量果然是不怎麼樣。
但反過來,對推薦系統來說就感到很奇怪了——使用者們你們明明喜歡點的呀,怎麼還覺得不好呢。所以這種大量存在的點選的偏置也是不公平的,是對高質量新聞的不公平。
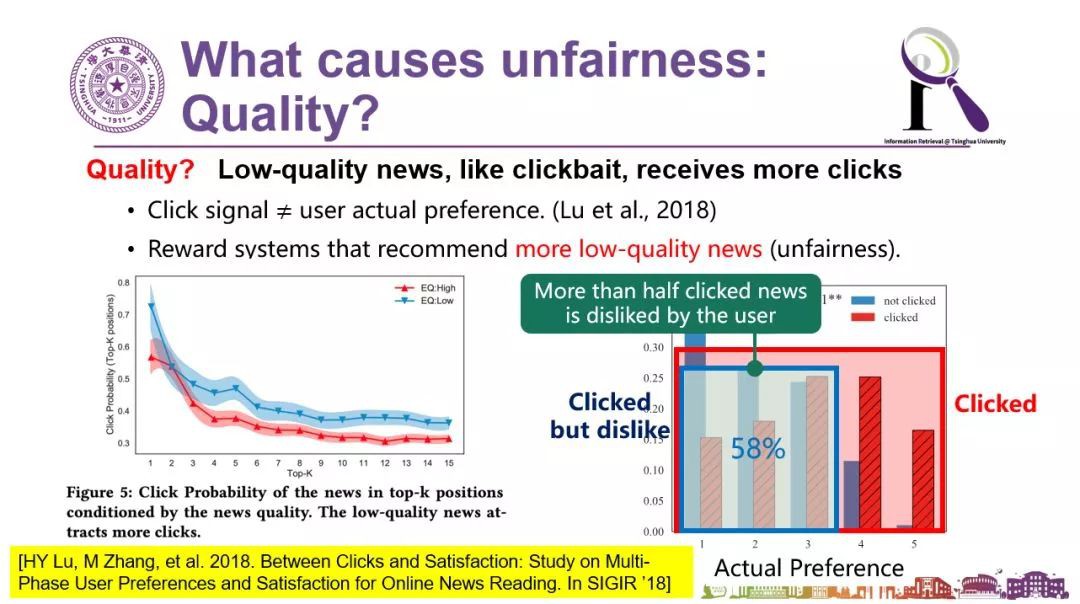
▲低質量新聞的點選率始終比高質量新聞的點選率高
怎麼解決呢?從演演算法思路可以一定程度上來解決。我們的思路是不要光看點選,不能只拿點選率來做評價指標,而要看使用者的滿意度。這個滿意度雖然沒有被使用者顯式地給出來,但是可以從使用者的行為找到蛛絲馬跡來進行自動分析。相關的工作我們發表到了2018年的SIGIR上(文章和主要方法可見下圖)。

▲低質量新聞的點選率始終比高質量新聞的點選率高
以上是我今天跟大家簡短分享的內容,主要是希望大家關註到可解釋性、魯棒性、公平性這三個非常重要的因素,而且這三個因素並非獨立存在,而是在相互作用的。
如果我們希望有一個更好的人工智慧系統,一定要在這三個方面做進一步的工作。真正智慧化的人工智慧技術依然前路漫漫,還有非常多的挑戰和非常多的機會等待我們去發現和麵對。
微信公眾號後臺對話方塊回覆個性化推薦,可獲取張教授演講完整版PPT。
