
作者:黃嘉鋒
來源:見文末
往往不少童鞋寫論文苦於資料獲取艱難,輾轉走上爬蟲之路;
許多分析師做輿情監控或者競品分析的時候,也常常使用到爬蟲。
今天,本文將帶領小夥伴們透過12行簡單的Python程式碼,初窺爬蟲的秘境。
爬蟲標的
本文采用requests + Xpath,爬取豆瓣電影《黑豹》部分短評內容。話不多說,程式碼先上:
import requests; from lxml import etree; import pandas as pd; import time; import random; from tqdm import tqdm
name, score, comment = [], [], []
def danye_crawl(page):
url = 'https://movie.douban.com/subject/6390825/comments?start=%s&limit;=20&sort;=new_score&status;=P&percent;_type='%(page*20)
response = etree.HTML(requests.get(url).content.decode('utf-8'))
print('\n', '第%s頁評論爬取成功'%(page)) if requests.get(url).status_code == 200 else print('\n', '第%s頁爬取失敗'(page))
for i in range(1,21):
name.append(response.xpath('//*[@id="comments"]/div[%s]/div[2]/h3/span[2]/a'%(i))[0].text)
score.append(response.xpath('//*[@id="comments"]/div[%s]/div[2]/h3/span[2]/span[2]'%(i))[0].attrib['class'][7])
comment.append(response.xpath('//*[@id="comments"]/div[%s]/div[2]/p'%(i))[0].text)
for i in tqdm(range(11)): danye_crawl(i); time.sleep(random.uniform(6, 9))
res = pd.DataFrame({'name':name, 'score':score, 'comment':comment},columns = ['name','score','comment']); res.to_csv("豆瓣.csv")執行以上的爬蟲指令碼,我們得以見證奇跡

爬蟲結果與原網頁內容的對比,完全一致

透過tqdm模組實現了良好的互動
工具準備
-
chrome瀏覽器(分析HTTP請求、抓包)
-
安裝Python 3及相關模組(requests、lxml、pandas、time、random、tqdm)
requests:用來簡單請求資料
lxml:比Beautiful Soup更快更強的解析庫
pandas:資料處理神器
time:設定爬蟲訪問間隔防止被抓
random:隨機數生成工具,配合time使用
tqdm:互動好工具,顯示程式執行進度
基本步驟
-
網路請求分析
-
網頁內容解析
-
資料讀取儲存
涉及知識點
-
爬蟲協議
-
http請求分析
-
requests請求
-
Xpath語法
-
Python基礎語法
-
Pandas資料處理
爬蟲協議
爬蟲協議即網站根目錄之下的robots.txt檔案,用來告知爬蟲者哪些可以拿哪些不能偷,其中Crawl-delay告知了網站期望的被訪問的間隔。(為了對方伺服器端同學的飯碗,文明拿資料,本文將爬蟲訪問間隔設定為6-9秒的隨機數)
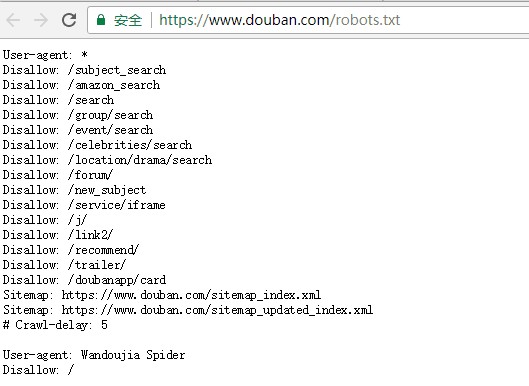
豆瓣網站的爬蟲協議
HTTP請求分析
使用chrome瀏覽器訪問《黑豹》短評頁面https://movie.douban.com/subject/6390825/comments?sort=new_score&status;=P,按下F12,進入network面板進行網路請求的分析,透過掃清網頁重新獲得請求,藉助chrome瀏覽器對請求進行篩選、分析,找到那個Ta

豆瓣短評頁面請求分析
透過請求分析,我們找到了標的url為
‘https://movie.douban.com/subject/6390825/comments?start=0&limit;=20&sort;=new_score&status;=P&percent;_type=’,並且每次翻頁,引數start將往上增加20
(透過多次翻頁嘗試,我們發現第11頁以後需要登入才能檢視,且登入狀態也僅展示前500條短評。作為簡單demo,本文僅對前11頁內容進行爬取)
requests請求
透過requests模組傳送一個get請求,用content方法獲取byte型資料,並以utf-8重新編碼;然後新增一個互動,判斷是否成功獲取到資源(狀態碼為200),輸出獲取狀態

請求詳情分析
(除了content,還有text方法,其傳回unicode字符集,直接使用text方法遇到中文的話容易出現亂碼)
Xpath語法解析
獲取到資料之後,需要對網頁內容進行解析,常用的工具有正則運算式、Beautiful Soup、Xpath等等;其中Xpath又快又方便。此處我們透過Xpath解析資源獲取到了前220條短評的使用者名稱、短評分數、短評內容等資料。
(可藉助chrome的強大功能直接複製Xpath,Xpath語法學習http://www.runoob.com/xpath/xpath-tutorial.html)
資料處理
獲取到資料之後,我們透過list構造dictionary,然後透過dictionary構造dataframe,並透過pandas模組將資料輸出為csv檔案
結語與彩蛋
本例透過requests+Xpath的方案,成功爬取了電影《黑豹》的部分豆瓣短評資料,為文字分析或其他資料挖掘工作打好了資料地基。
本文作為demo,僅展示了簡單的爬蟲流程,更多彩蛋如請求頭、請求體資訊獲取、cookie、模擬登入、分散式爬蟲等請關註後期文章更新喲。
最後,送上白話文版的程式碼:
import requests
from lxml import etree
import pandas as pd
import time
import random
from tqdm import tqdm
name, score, comment = [], [], []
def danye_crawl(page):
url = 'https://movie.douban.com/subject/6390825/comments?start=%s&limit;=20&sort;=new_score&status;=P&percent;_type='%(page*20)
response = requests.get(url)
response = etree.HTML(response.content.decode('utf-8'))
if requests.get(url).status_code == 200:
print('\n', '第%s頁評論爬取成功'%(page))
else:
print('\n', '第%s頁爬取失敗'(page))
for i in range(1,21):
name_list = response.xpath('//*[@id="comments"]/div[%s]/div[2]/h3/span[2]/a'%(i))
score_list = response.xpath('//*[@id="comments"]/div[%s]/div[2]/h3/span[2]/span[2]'%(i))
comment_list = response.xpath('//*[@id="comments"]/div[%s]/div[2]/p'%(i))
name_element = name_list[0].text
score_element = score_list[0].attrib['class'][7]
comment_element = comment_list[0].text
name.append(name_element)
score.append(score_element)
comment.append(comment_element)
for i in tqdm(range(11)):
danye_crawl(i)
time.sleep(random.uniform(6, 9))
res = {'name':name, 'score':score, 'comment':comment}
res = pd.DataFrame(res, columns = ['name','score','comment'])
res.to_csv("豆瓣.csv")
作者:黃嘉鋒
來源:https://www.jianshu.com/p/ea0b56e3bd86
本文轉載自:Python那些事
《Python人工智慧和全棧開發》2018年07月23日即將在北京開課,120天衝擊Python年薪30萬,改變速約~~~~
*宣告:推送內容及圖片來源於網路,部分內容會有所改動,版權歸原作者所有,如來源資訊有誤或侵犯權益,請聯絡我們刪除或授權事宜。
– END –

更多Python好文請點選【閱讀原文】哦
↓↓↓
