
筆者邀請您,先思考:
1 信用評分卡如何開發?
評分卡開發描述瞭如何將資料轉化為評分卡模型,假設資料準備和初始變數選擇過程(過濾)已完成,並且已過濾的訓練資料集可用於模型構建過程。 開發過程包含四個主要部分:變數轉換,使用邏輯回歸的模型訓練,模型驗證和縮放。
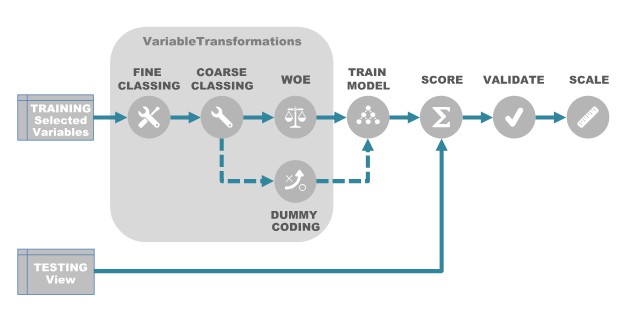
圖1.標準評分卡開發過程
變數轉換
“如果你長時間折磨資料,它會承認任何事情。” (羅納德科斯,經濟學家) – 基於邏輯回歸的標準計分卡模型是一個可加模型; 因此,需要特殊的變數轉換。 通常採用的轉換 – 精細分類,粗分類,以及虛擬編碼或證據權重(WOE)轉換 – 形成了一個順序過程,提供了一個易於實施並向企業解釋的模型結果。 此外,這些轉換有助於將獨立變數和因變數之間的非線性關係轉化為線性關係 – 業務往往要求的客戶行為。
精細的分類
適用於所有連續變數和具有高基數的離散變數。這是通常在20到50個細顆粒箱子中初始裝箱的過程。
粗分類
如果將分箱過程應用於細粒倉,以合併具有類似風險的箱子並建立較少的箱子,通常最多為10個箱子。其目的是透過建立更少的箱子來實現簡單化,每個箱子都具有明顯不同的風險因素,同時最大限度地減少資訊損失。然而,為了建立一個可適應過度擬合的穩健模型,每個箱子應包含來自總賬戶觀察值的足夠數量(5%是大多數從業人員推薦的最小值)。這些標的可以透過最優分箱形式的最佳化來實現,該分類在粗分類過程中最大化變數的預測能力。最優分箱使用與變數選擇相同的統計量度,例如資訊價值,基尼和卡方統計。儘管兩種或更多種措施的結合通常是有益的,但最普遍的措施也是資訊價值。如果缺失值包含預測資訊,則應該是單獨的類別或合併到類似風險因素的分類中。
虛擬編碼
為參考類以外的所有粗糙類建立二進位制(虛擬)變數的過程。這種方法可能存在問題,因為額外的變數需要更多的記憶體和處理資源,並且偶爾會由於自由度降低而出現過度擬合。
證據權重(WOE)轉換
替代的,更受青睞的虛擬編碼方法,用每個粗糙類代替風險值,然後將風險值摺疊成單個數值變數。數字變數描述了獨立變數和因變數之間的關係。 WOE框架非常適合邏輯回歸建模,因為它們都基於對數可能性計算。此外,WOE轉換將所有獨立變數標準化,因此可以直接比較後續邏輯回歸中的引數。這種方法的主要缺點是隻考慮每個箱子的相對風險,而不考慮每個箱子的賬戶比例。資訊值可以用來評估每個箱子的相對貢獻。
虛擬編碼和WOE轉換都給出了類似的結果。 選擇哪一個主要取決於資料科學家的偏好。
但需要註意的是,當手動執行時,最佳化分箱,虛擬編碼和WOE轉換是耗時的過程。 用於裝箱,最佳化和WOE轉換的軟體包因此非常有用並且強烈推薦。

圖2.自動最優分箱和WOE轉換
模型訓練和縮放
Logistic回歸是用於解決二元分類問題的信用評分中常用的技術。在模型擬合之前,變數選擇的另一次迭代對於檢查新的WOE變換變數是否仍然是好的模型候選是有價值的。首選候選變數是資訊價值較高(通常在0.1到0.5之間)的變數與因變數具有線性關係,在所有類別中具有良好的改寫率,具有正態分佈,包含顯著的總體貢獻,並且與業務相關。
許多分析供應商在其軟體產品中包含邏輯回歸模型,通常具有廣泛的統計和圖形功能。例如,WPS中SAS語言PROC LOGISTIC的實現為自動化變數選擇,模型引數限制,加權變數,獲得不同分段的單獨分析,在不同資料集上評分,生成自動化部署程式碼,僅舉幾例。
一旦模型一致,下一步就是將模型調整到業務所需的規模。這被稱為縮放。縮放是一種衡量工具,可提供不同評分卡上分數的一致性和標準化。最低和最高分數值和分數範圍有助於風險解釋和應該報告給企業。通常,業務要求是對多個評分卡使用相同的分數範圍,因此它們都具有相同的風險解釋。
一種流行的得分方法以對數形式建立離散得分,其中可能性在預定數量的點處加倍。這需要指定三個引數:基點,例如600點,基本賠率,例如50:1,指向雙倍賠率,例如20.得分點對應於模型變數的每個單元,而模型截距是翻譯成基點。帶有串列分配點的縮放輸出代表實際的評分卡模型。

圖3.評分卡縮放
模型效能
模型評估是模型構建過程的最後一步。 它由三個不同的階段組成:評估,驗證和接受。
評估準確性 – 我是否建立了正確的模型? – 是為了測試模型而問的第一個問題。 評估的關鍵指標是統計指標,包括模型準確性,複雜性,錯誤率,模型擬合統計,變數統計,顯著性值和勝算比。
驗證穩健性 – 我建立了正確的模型嗎? – 當從分類準確性和統計評估轉向排序能力和業務評估時,是下一個問題。
驗證度量標準的選擇取決於模型分類器的型別。二元分類問題最常見的指標是收益圖,提升圖,ROC曲線和Kolmogorov-Smirnov圖。 ROC曲線是視覺化模型效能的最常用工具。它是一種多用途工具,用於:
-
冠軍挑戰者方法論來選擇最佳表現模型;
-
測試不可見資料的模型效能並將其與訓練資料進行比較;
-
選擇最佳閾值,使真陽率最大化,同時最小化假陽率。
ROC曲線是透過將靈敏度與不同閾值下的錯誤警報機率(誤報率)作圖而建立的。評估不同閾值下的效能指標是ROC曲線的理想特徵。基於業務戰略,不同型別的業務問題將具有不同的閾值。
ROC曲線下麵積(AUC)是指示分類器預測能力的有用指標。在信用風險中,0.75或更高的AUC是行業公認的標準和模型驗收的先決條件。
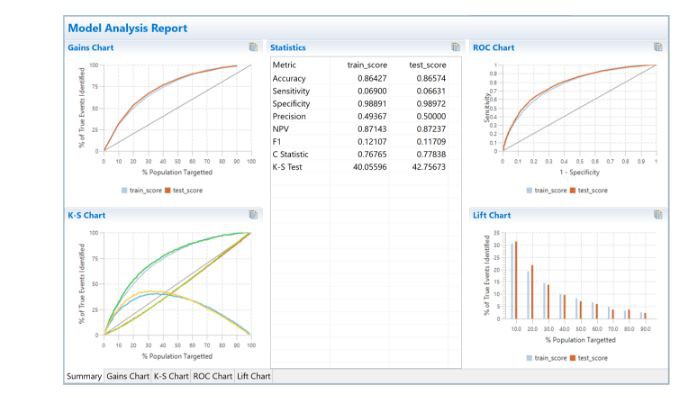
圖4.模型效能度量
接受有用性 – 模型是否會被接受? – 為了測試該模型是否有利於業務發展,這是要問的最後一個問題。 這是資料科學家必須將模型結果回放到業務並“維護”其模型的關鍵階段。 關鍵的評估標準是模型的商業利益,因此,利益分析是介紹結果的核心部分。** 資料科學家應盡一切努力以簡明的方式呈現結果,因此結果和發現很容易理解和理解。 如果未能實現此標的,可能會導致模型拒收,從而導致專案失敗。**
系列之前:信用評分:第4部分 – 變數選擇
系列之前:信用評分:第6部分 – 分割和拒絕推斷
作者:
Natasha Mashanovich,
Senior Data Scientist at World Programming,
UK
原文連結:https://www.worldprogramming.com/blog/credit_scoring_pt5
版權宣告:作者保留權利,嚴禁修改,轉載請註明原文連結。
資料人網是資料人學習、交流和分享的平臺http://shujuren.org 。專註於從資料中學習到有用知識。
平臺的理念:人人投稿,知識共享;人人分析,洞見驅動;智慧聚合,普惠人人。
您在資料人網平臺,可以1)學習資料知識;2)建立資料部落格;3)認識資料朋友;4)尋找資料工作;5)找到其它與資料相關的乾貨。
我們努力堅持做原創,聚合和分享優質的省時的資料知識!
我們都是資料人,資料是有價值的,堅定不移地實現從資料到商業價值的轉換!
加入資料人圈子或者商務合作,請新增筆者微信。

點選閱讀原文,進入資料人網,獲取資料知識。
公眾號推薦:
鏈達君,專註於分享區塊鏈內容。

腳印英語,專註於分享英語口語內容。
