
作者:j_hao104
來源:見文末
爬蟲代理IP池
在公司做分散式深網爬蟲,搭建了一套穩定的代理池服務,為上千個爬蟲提供有效的代理,保證各個爬蟲拿到的都是對應網站有效的代理IP,從而保證爬蟲快速穩定的執行,當然在公司做的東西不能開源出來。不過呢,閑暇時間手癢,所以就想利用一些免費的資源搞一個簡單的代理池服務。
1、問題
代理IP從何而來?
剛自學爬蟲的時候沒有代理IP就去西刺、快代理之類有免費代理的網站去爬,還是有個別代理能用。當然,如果你有更好的代理介面也可以自己接入。
免費代理的採集也很簡單,無非就是:訪問頁面頁面 —> 正則/xpath提取 —> 儲存
如何保證代理質量?
可以肯定免費的代理IP大部分都是不能用的,不然別人為什麼還提供付費的(不過事實是很多代理商的付費IP也不穩定,也有很多是不能用)。所以採集回來的代理IP不能直接使用,可以寫檢測程式不斷的去用這些代理訪問一個穩定的網站,看是否可以正常使用。這個過程可以使用多執行緒或非同步的方式,因為檢測代理是個很慢的過程。
採集回來的代理如何儲存?
這裡不得不推薦一個高效能支援多種資料結構的NoSQL資料庫SSDB,用於代理Redis。支援佇列、hash、set、k-v對,支援T級別資料。是做分散式爬蟲很好中間儲存工具。
如何讓爬蟲更簡單的使用這些代理?
答案肯定是做成服務咯,python有這麼多的web框架,隨便拿一個來寫個api供爬蟲呼叫。這樣有很多好處,比如:當爬蟲發現代理不能使用可以主動透過api去delete代理IP,當爬蟲發現代理池IP不夠用時可以主動去refresh代理池。這樣比檢測程式更加靠譜。
2、代理池設計
代理池由四部分組成:
ProxyGetter:
代理獲取介面,目前有5個免費代理源,每呼叫一次就會抓取這個5個網站的最新代理放入DB,可自行新增額外的代理獲取介面;
DB:
用於存放代理IP,現在暫時只支援SSDB。至於為什麼選擇SSDB,大家可以參考這篇文章,個人覺得SSDB是個不錯的Redis替代方案,如果你沒有用過SSDB,安裝起來也很簡單,可以參考這裡;
Schedule:
計劃任務使用者定時去檢測DB中的代理可用性,刪除不可用的代理。同時也會主動透過ProxyGetter去獲取最新代理放入DB;
ProxyApi:
代理池的外部介面,由於現在這麼代理池功能比較簡單,花兩個小時看了下Flask,愉快的決定用Flask搞定。功能是給爬蟲提供get/delete/refresh等介面,方便爬蟲直接使用。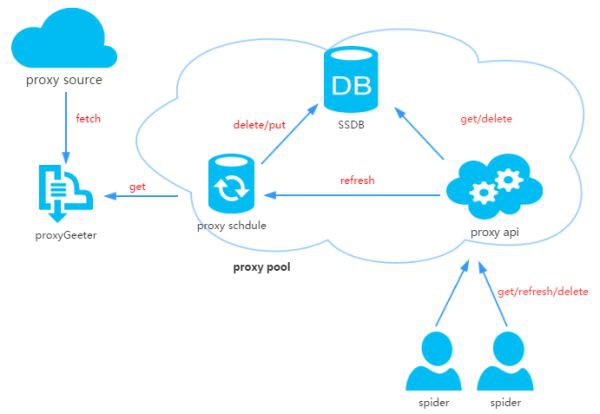
3、程式碼模組
Python中高層次的資料結構,動態型別和動態系結,使得它非常適合於快速應用開發,也適合於作為膠水語言連線已有的軟體部件。用Python來搞這個代理IP池也很簡單,程式碼分為6個模組:
Api:
api介面相關程式碼,目前api是由Flask實現,程式碼也非常簡單。客戶端請求傳給Flask,Flask呼叫ProxyManager中的實現,包括get/delete/refresh/get_all;
DB:
資料庫相關程式碼,目前資料庫是採用SSDB。程式碼用工廠樣式實現,方便日後擴充套件其他型別資料庫;
Manager:
get/delete/refresh/get_all等介面的具體實現類,目前代理池只負責管理proxy,日後可能會有更多功能,比如代理和爬蟲的系結,代理和賬號的系結等等;
ProxyGetter:
代理獲取的相關程式碼,目前抓取了快代理、代理66、有代理、西刺代理、guobanjia這個五個網站的免費代理,經測試這個5個網站每天更新的可用代理只有六七十個,當然也支援自己擴充套件代理介面;
Schedule:
定時任務相關程式碼,現在只是實現定時去掃清程式碼,並驗證可用代理,採用多行程方式;
Util:
存放一些公共的模組方法或函式,包含GetConfig:讀取配置檔案config.ini的類,ConfigParse: 整合重寫ConfigParser的類,使其對大小寫敏感, Singleton:實現單例,LazyProperty:實現類屬性惰性計算。等等;
其他檔案:
配置檔案:Config.ini,資料庫配置和代理獲取介面配置,可以在GetFreeProxy中新增新的代理獲取方法,併在Config.ini中註冊即可使用;
4、安裝
下載程式碼:
git clone git@github.com:jhao104/proxy_pool.git
或者直接到https://github.com/jhao104/proxy_pool 下載zip檔案
安裝依賴:
pip install -r requirements.txt
啟動:
需要分別啟動定時任務和api
到Config.ini中配置你的SSDB
到Schedule目錄下:
>>>python ProxyRefreshSchedule.py
到Api目錄下:
>>>python ProxyApi.py
5、使用
定時任務啟動後,會透過代理獲取方法fetch所有代理放入資料庫並驗證。此後預設每20分鐘會重覆執行一次。定時任務啟動大概一兩分鐘後,便可在SSDB中看到掃清出來的可用的代理:

啟動ProxyApi.py後即可在瀏覽器中使用介面獲取代理,一下是瀏覽器中的截圖:
index頁面:

get頁面:
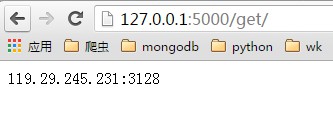
get_all頁面:

爬蟲中使用,如果要在爬蟲程式碼中使用的話, 可以將此api封裝成函式直接使用,例如:
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5000/get/").content
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5000/delete/?proxy={}".format(proxy))
# your spider code
def spider():
# ....
requests.get('https://www.example.com', proxies={"http": "http://{}".format(get_proxy)})
# ....
6、最後
時間倉促,功能和程式碼都比較簡陋,以後有時間再改進。喜歡的在github上給個star。感謝!
github專案地址:https://github.com/jhao104/proxy_pool
個人部落格:http://www.spiderpy.cn/
作者:j_hao104
來源:https://my.oschina.net/jhao104/blog/799883
《Python人工智慧和全棧開發》2018年07月23日即將在北京開課,120天衝擊Python年薪30萬,改變速約~~~~
*宣告:推送內容及圖片來源於網路,部分內容會有所改動,版權歸原作者所有,如來源資訊有誤或侵犯權益,請聯絡我們刪除或授權事宜。
– END –


更多Python好文請點選【閱讀原文】哦
↓↓↓
