

文章轉自“Lustre檔案系統與DDN”
Lustre架構是一種叢集儲存體系結構,其核心元件就是Lustre檔案系統。該檔案系統可在Linux作業系統上執行,並提供了符合POSIX標準的UNIX檔案系統介面。
Lustre檔案系統是什麼
Lustre架構用於許多不同種類的叢集。眾所周知,它服務於許多全球最大的高效能運算(HPC)叢集,提供了數以萬計的客戶端,PB級儲存和每秒數百GB的吞吐量。許多HPC站點使用Lustre檔案系統作為全站範圍的全域性檔案系統,為數十個群集提供服務。
Lustre檔案系統具有按需擴充套件容量和效能的能力,降低了部署多個獨立檔案系統的必要性(如每個計算群集部署一個檔案系統),從而避免了在計算叢集之間複製資料,簡化了儲存管理。Lustre檔案系統不僅可將許多伺服器的儲存容量進行聚合,也可將其I / O吞吐量進行聚合,並透過添置伺服器進行擴充套件。透過動態地新增伺服器,輕鬆實現整個叢集的吞吐量和容量的提升。
雖然Lustre檔案系統可以在許多工作環境中執行,但也並非就是所有應用程式的最佳選擇。當單個伺服器無法提供所需容量時,使用Lustre檔案系統叢集無疑是最適合的。在某些情況下,由於其強大的鎖定和資料一致性,即使在單個伺服器環境下Lustre檔案系統也比其他檔案系統表現得更好。
目前,Lustre檔案系統並不特別適用於“端對端”的使用者樣式。在這種樣式下,客戶端和伺服器在同一節點上執行,每個節點共享少量儲存。由於Lustre缺少軟體級別的資料副本,如果一個客戶端或伺服器發生故障,儲存在該節點上的資料在該節點重新啟動前將不可訪問。
Lustre檔案系統特性
Lustre檔案系統可執行在各種廠商的核心上。一個Lustre檔案系統在客戶端節點數量、磁碟儲存量、頻寬上進行擴大或縮小。可擴充套件性和效能取決於可用磁碟、網路頻寬以及系統中伺服器的處理能力。
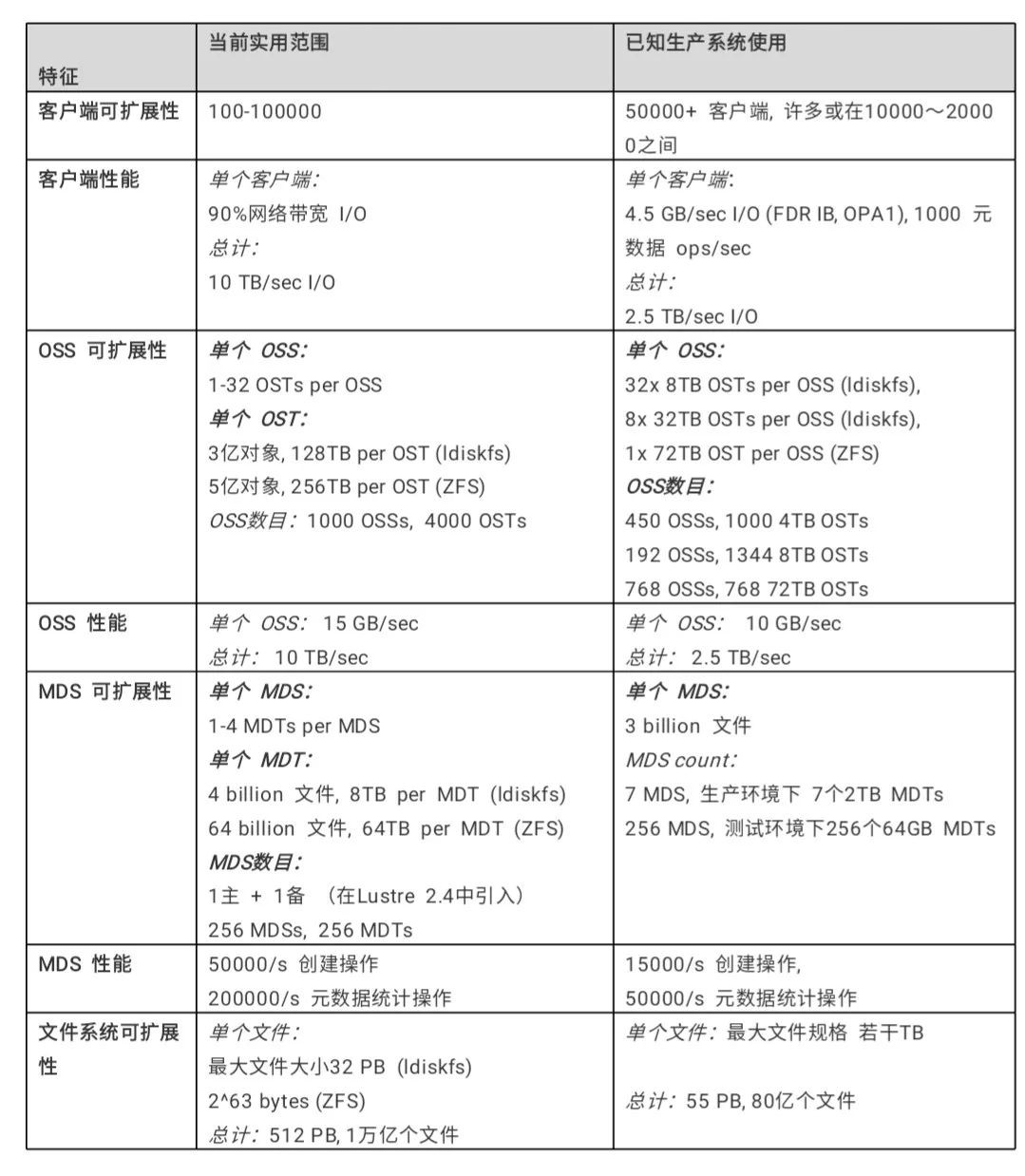
Lustre檔案系統可以以多種配置進行部署,這些配置的可擴充套件性遠遠超出了迄今所觀察到生產系統中的規模和效能。下表中列出了一些Lustre檔案系統的可擴充套件性和效能:
效能增強的ext4檔案系統:Lustre檔案系統使用改進版的ext4日誌檔案系統來儲存資料和元資料。這個版本被命名為ldiskfs,不僅效能有所提升且提供了Lustre檔案系統所需的附加功能。
Lustre 2.4或更高版本中,可使用ZFS作為Lustre的MDT,OST和MGS儲存的後備檔案系統。這使Lustre能夠利用ZFS的可擴充套件性和資料完整性特性來實現單個儲存標的。
符合POSIX標準:透過完整的POSIX測試集,像測試本地檔案系統Ext4一樣,測試Lustre檔案系統客戶端,只有極少量例外。在叢集中,大多數操作都是原子操作,因此客戶端永遠不會看到損壞的資料或元資料。 Lustre軟體支援mmap()檔案I / O操作。
高效能異構網路:Lustre軟體支援各種高效能低延遲的網路,可使用遠端直接記憶體訪問(RDMA)方式,實現在InfiniBand、Intel OmniPath等高階網路上的快速高效網路傳輸。可使用Lustre路由橋接多個RDMA網路以獲得最佳效能。Lustre軟體同時也集成了網路診斷。
高可用性:Lustre檔案系統透過OSTs(OSS targets)的共享儲存分割槽實現主動/主動故障切換。 Lustre 2.3或更早版本透過使用MDT(MDS target)的共享儲存分割槽實現主動/被動故障切換。 Lustre檔案系統可以與各種高可用性(HA)管理器一起工作,以實現自動故障切換並消除了單點故障(NSPF)。這使得應用程式透明恢覆成為可能。多重掛載保護(MMP)提供了對高可用性系統中錯誤的綜合保護,避免導致檔案系統損壞。
Lustre 2.4或更高版本中,可配置多個MDT的主動/主動故障切換。這允許了透過新增MDT儲存裝置和MDS節點來擴充套件Lustre檔案系統的元資料效能。
安全性:預設情況下,TCP連線只允許授權埠透過。 UNIX組成員身份在MDS上進行驗證。
訪問控制串列(ACL)及擴充套件屬性:Lustre安全模型遵循UNIX檔案系統原則,並使用POSIX ACL進行增強。此外還有一些額外功能,如root squash。
互操作性:Lustre檔案系統可執行在各種CPU架構和大小端混合的群集上,連續釋出的Lustre主要軟體版本之間保持互操作性性。
基於物件的體系結構:客戶端與磁碟檔案結構相互隔離,可在不影響客戶端的情況下升級儲存體系結構。
位元組粒度檔案鎖和細粒度元資料鎖:許多客戶端可以同時讀取和修改相同的檔案或目錄。 Lustre分散式鎖管理器(LDLM)確保了檔案系統中所有客戶端和伺服器之間的檔案是一致的。其中,MDT鎖管理器負責管理inode許可權和路徑名。每個OST都有其自己的鎖管理器,用於鎖定儲存在其上的檔案條帶,其效能可隨著檔案系統大小增長而擴充套件。
配額:使用者、組和專案配額(User、Group、Project Quota)可用於Lustre檔案系統。
容量增長:透過向群集新增新的OST和MDT,可以在不中斷服務的情況下增加Lustre檔案系統的大小和叢集總頻寬。
受控檔案佈局:可以在每個檔案,每個目錄或每個檔案系統基礎上配置跨OST的檔案佈局。這允許了在單個檔案系統中調整檔案I/O以適應特定的應用程式要求。 Lustre檔案系統使用RAID-0進行條帶化並可在OST之間調節空間使用大小。
網路資料完整性保護:從客戶端傳送到OSS的所有資料的校驗和可防止資料在傳輸期間被損壞。
MPI I/O:Lustre架構具有專用的MPI ADIO層,優化了並行I/O以匹配基礎檔案系統架構。
NFS和CIFS匯出:可以使用NFS(透過Linux knfsd)或CIFS(透過Samba)將Lustre檔案重新匯出,使其可以與非Linux客戶端(如Microsoft Windows和Apple Mac OS X)共享。
災難恢復工具:Lustre檔案系統提供線上分散式檔案系統檢查(LFSCK),當發生主要檔案系統錯誤的情況下恢復儲存元件之間的一致性。 Lustre檔案系統在存在檔案系統不一致的情況下也可以執行,而LFSCK可以在檔案系統正在使用時執行,因此LFSCK不需要在檔案系統恢復生產之前完成。
效能監視:Lustre檔案系統提供了多種機制來檢查效能和進行調整。
開放原始碼:為在Linux作業系統上執行,Lustre軟體使用GPL 2.0許可證。
Lustre元件介紹
一個Lustre安裝實體包括管理伺服器(MGS)和一個或多個與Lustre網路(LNet)互連的Lustre檔案系統。Lustre檔案系統元件的基本配置如下圖所示:
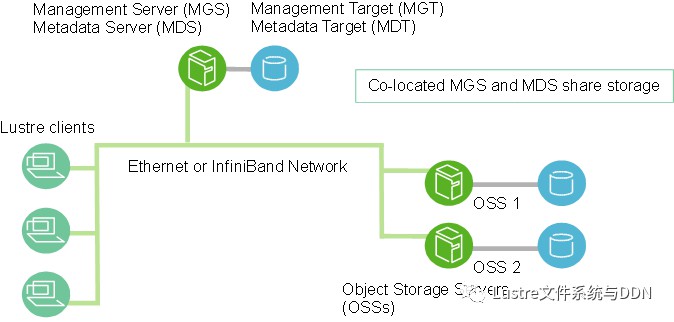
管理伺服器(MGS)
MGS儲存叢集中所有Lustre檔案系統的配置資訊,並將此資訊提供給其他Lustre元件。每個Lustre標的(target)透過聯絡MGS提供資訊,而Lustre客戶透過聯絡MGS獲取資訊。MGS最好有自己的儲存空間,以便可以獨立管理。但同時,MGS可以與MDS放在一起,並共享儲存空間,如上圖中所示。
Lustre檔案系統元件
-
元資料伺服器(MDS): MDS使儲存在一個或多個MDT中的元資料可供Lustre客戶端使用。每個MDS管理Lustre檔案系統中的名稱和目錄,併為一個或多個本地MDT提供網路請求處理。
-
元資料標的(MDT): 在Lustre 2.3或更早版本中,每個檔案系統只有一個MDT。 MDT在MDS的附加儲存上儲存元資料(例如檔案名,目錄,許可權和檔案佈局)。雖然共享儲存標的上的MDT可用於多個MDS,但一次只能有一個MDS可以訪問。如果當前MDS發生故障,則備用MDS可以為MDT提供服務,並將其提供給客戶端。這被稱為MDS故障切換。
在Lustre 2.4中,分散式名稱空間環境(DNE)中可支援多個MDT。除儲存檔案系統根目錄的主MDT之外,還可以新增其他MDS節點,每個MDS節點都有自己的MDT,以儲存檔案系統的子目錄樹。
在Lustre 2.8中,DNE還允許檔案系統將單個目錄的檔案分佈到多個MDT節點。分佈在多個MDT上的目錄稱為條帶化目錄。
-
物件儲存伺服器(OSS):OSS為一個或多個本地OST提供檔案I / O服務和網路請求處理。通常,OSS服務於兩個到八個OST,每個最多16TB;在專用節點上配置一個MDT;在每個OSS節點上配置兩個或更多OST;而在大量計算節點上配置客戶端。
-
物件儲存標的(OST):使用者檔案資料儲存在一個或多個物件中,每個物件位於Lustre檔案系統的單獨OST中。每個檔案的物件數由使用者配置,並可根據工作負載情況除錯到最優效能。
-
Lustre客戶端:Lustre客戶端是執行Lustre客戶端軟體的計算、視覺化或桌面節點,可掛載Lustre檔案系統。
Lustre客戶端軟體為Linux虛擬檔案系統和Lustre伺服器之間提供了介面。客戶端軟體包括一個管理客戶端(MGC),一個元資料客戶端(MDC)和多個物件儲存客戶端(OSC)。每個OSC對應於檔案系統中的一個OST。
邏輯物件捲(LOV)透過聚合OSC以提供對所有OST的透明訪問。因此,掛載了Lustre檔案系統的客戶端會看到一個連貫的同步名字空間。多個客戶端可以同時寫入同一檔案的不同部分,而其他客戶端可以同時讀取檔案。
與LOV檔案訪問方式類似,邏輯元資料捲(LMV)透過聚合MDC提供一種對所有MDT透明的訪問。這使得了客戶端可將多個MDT上的目錄樹視為一個單一的連貫名字空間,並將條帶化目錄合併到客戶端形成一個單一目錄以便使用者和應用程式檢視。

Lustre網路 (LNet)
Lustre Networking(LNet)是一種定製網路API,提供處理Lustre檔案系統伺服器和客戶端的元資料和檔案I/O資料的通訊基礎設施。
Lustr檔案系統 叢集
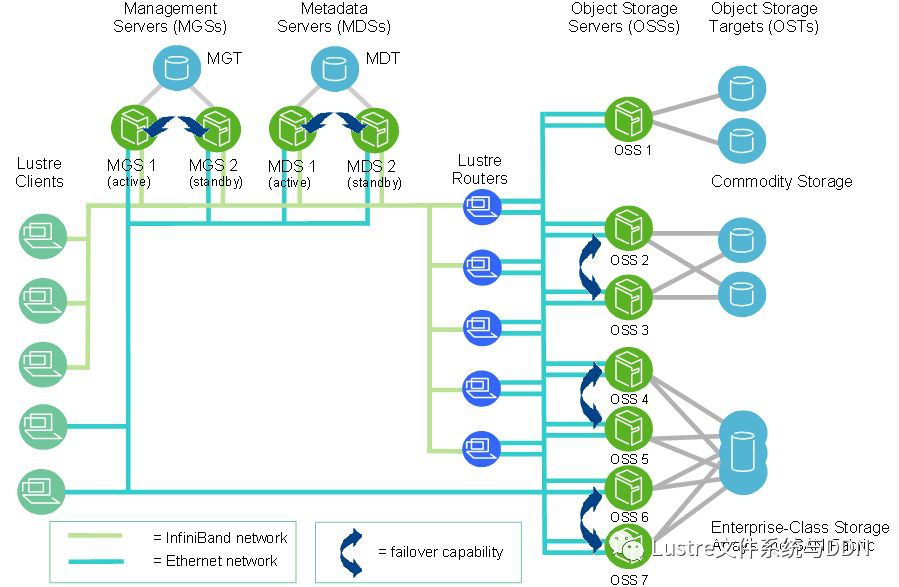
在規模上,一個Lustre檔案系統叢集可以包含數百個OSS和數千個客戶端(如下圖所示)。 Lustre叢集中可以使用多種型別的網路,OSS之間的共享儲存啟用故障切換功能。
Lustre檔案系統儲存與I/O
在 Lustre 2.0 中引入了Lustre檔案識別符號(FID)來替換用於識別檔案或物件的UNIX inode編號。 FID是一個128位的識別符號,其中,64位用於儲存唯一的序列號,32位用於儲存物件識別符號(OID),另外32位用於儲存版本號。序列號在檔案系統(OST和MDT)中的所有Lustre標的中都是唯一的。這一改變使未來支援多種 MDT 和ZFS(均在Lustre 2.4中引入)成為了可能。
同時,在此版本中也引入了一個名為FID-in-dirent(也稱為Dirdata)的ldiskfs功能,FID作為檔案名稱的一部分儲存在父目錄中。該功能透過減少磁碟I/O顯著提高了ls命令執行的效能。 FID-in-dirent是在建立檔案時生成的。
在 Lustre 2.4 中,LFSCK檔案系統一致性檢查工具提供了對現有檔案啟用FID-in-dirent的功能。具體如下:
-
為1.8版本檔案系統上現有檔案生成IGIF樣式的FID。
-
驗證每個檔案的FID-in-dirent,如其無效或丟失,則重新生成FID-in-dirent。
-
驗證每個linkEA條目,如其無效或丟失,則重新生成。 linkEA由檔案名和父類FID組成,它作為擴充套件屬性儲存在檔案本身中。因此,linkEA可以用來重建檔案的完整路徑名。
有關檔案資料在OST上的位置資訊將作為擴充套件屬性佈局EA,儲存在由FID標識的MDT物件中(具體如下圖所示)。若該檔案是普通檔案(即不是目錄或符號連結),則MDT物件1對N地指向包含檔案資料的OST物件。若該MDT檔案指向一個物件,則所有檔案資料都儲存在該物件中。若該MDT檔案指向多個物件,則使用RAID 0將檔案資料劃分為多個物件,將每個物件儲存在不同的OST上。
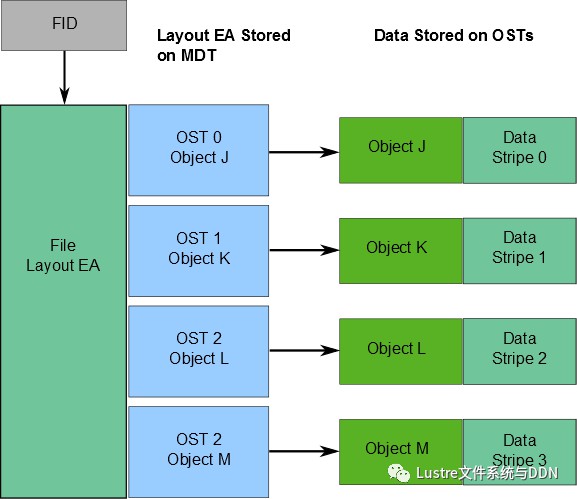
當客戶端讀寫檔案時,首先從檔案的MDT物件中獲取佈局EA,然後使用這個資訊在檔案上執行I / O,直接與儲存物件的OSS節點進行互動。具體過程如下圖所示。

Lustre檔案系統的可用頻寬如下:
-
網路頻寬等於OSS到標的的總頻寬。
-
磁碟頻寬等於儲存標的(OST)的磁碟頻寬總和,受網路頻寬限制。
-
總頻寬等於磁碟頻寬和網路頻寬的最小值。
-
可用的檔案系統空間等於所有OST的可用空間總和。
Lustre檔案系統條帶化
Lustre檔案系統高效能的主要原因之一是能夠以輪詢方式跨多個OST將資料條帶化。使用者可根據需要為每個檔案配置條帶數量,條帶大小和OST。當單個檔案的總頻寬超過單個OST的頻寬時,可以使用條帶化來提高效能。同時,當單個OST沒有足夠的可用空間來容納整個檔案時,條帶化也能發揮它的作用。
如圖下圖所示,條帶化允許將檔案中的資料段或“塊”儲存在不同的OST中。在Lustre檔案系統中,透過RAID 0樣式將資料在一定數量的物件上進行條帶化。一個檔案中處理的物件數稱為stripe_count。每個物件包含檔案中的一個資料塊,當寫入特定物件的資料塊超過stripe_size時,檔案中的下一個資料塊將儲存在下一個物件上。stripe_count和stripe_size的預設值由為檔案系統設定的,其中,stripe_count為1,stripe_size為1MB。使用者可以在每個目錄或每個檔案上更改這些值。
下圖中,檔案C的stripe_size大於檔案A的stripe_size,表明更多的資料被允許儲存在檔案C的單個條帶中。檔案A的stripe_count為3,則資料在三個物件上條帶化。檔案B和檔案C的stripe_count是1。OST上沒有為未寫入的資料預留空間。
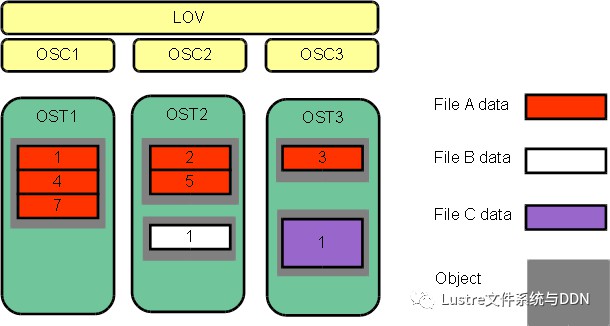
最大檔案大小不受單個標的大小的限制。在Lustre檔案系統中,檔案可以跨越多個物件(最多2000個)進行分割,每個物件可使用多達16 TB的ldiskfs,多達256PB的ZFS。也就是說,ldiskfs的最大檔案大小為31.25 PB,ZFS的最大檔案大小為8EB。Lustre檔案系統上的檔案大小受且僅受OST上可用空間的限制,Lustre最大可支援2 ^ 63位元組(8EB)的檔案。
註意: Lustre 2.2之前,單個檔案的最大條帶數為160個OST。儘管一個檔案只能被分割成2000個以上的物件,但是Lustre檔案系統可以有數千個。
關於HPC技術和方案,前期詳細分享過<從高效能運算(HPC)技術演變解析方案、生態和行業發展趨勢>分析,並整理成電子書,請點選“閱讀原文”連結查閱。
熱文閱讀
溫馨提示:
請搜尋“ICT_Architect”或“掃一掃”二維碼關註公眾號,點選原文連結獲取更多技術資料。

Stay hungry, Stay foolish

