
隨著當今計算能力的大幅度提升和大資料時代的到來,深度學習在幫助挖掘海量資料中蘊含的資訊和完成一些人工智慧任務中,展現出了非凡的能力。然而目前深度學習領域還有許多問題亟待解決,其中演演算法引數和結構的最佳化尤為困難。而進化最佳化作為一種通用的最佳化方法,逐漸受到學術界的一些關註和應用,以期能解決以上難題。
基於遺傳規劃的自動機器學習

自動機器學習(Automated/Automatic Machine Learning, AutoML)作為近年來逐漸興起的熱門研究領域,旨在降低機器學習的門檻,使其更加易用。
一般而言,一個完整的機器學習(特別是監督式機器學習)工作流通常包含以下部分,資料清洗,特徵工程,模型選擇,訓練測試以及超引數調優。每一道工序都有相當多的實現選項,且工序之間相互影響,共同決定最終的模型效能。
對於機器學習使用者而言,針對具體任務設計實現合適的工作流並不容易,在很多情況下可能會耗費大量的時間進行迭代。AutoML 的標的便是盡可能地使以上的過程自動化,從而降低使用者的負擔。
本次我們要同大家分享的是近年來在 AutoML 領域內比較有影響力的一個工作,基於樹表示的工作流最佳化(Tree-based Pipeline Optimization Tool, TPOT)。
TPOT 的作者為 Randal S. Olson 等人,相關文獻為 [1] (2016 EvoStar Best Paper) 和 [2] (2016 GECCO Best Paper),我們在這裡將兩篇文獻的內容統一為大家作介紹。

▲ 圖1:機器學習工作流中被TPOT最佳化的部分
如圖 1 所示,TPOT 希望從整體上自動最佳化機器學習的工作流 。在 TPOT 中,一個工作流被定義為一棵樹,樹上每一個非葉子節點為操作(Operator)節點,葉子節點則為資料節點。資料集從葉子節點流入,經過操作節點進行變換,最終在根節點處進行分類/回歸,圖 2 給出了一個例子。
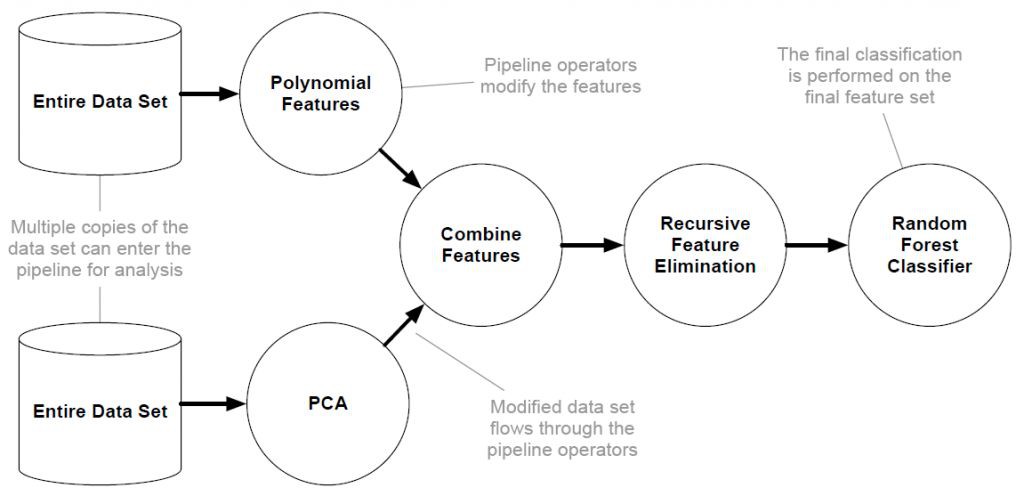
▲ 圖2:基於樹表示的工作流的一個例子
TPOT 一共定義了 4 種操作節點型別(見圖 3),分別是預處理、分解/降維、特徵選擇以及學習模型。這些操作的底層實現均是基於 Python 的機器學習庫 scikit-learn。

▲ 圖3:TPOT操作節點型別
有了以上基於樹的表示,TPOT 直接利用遺傳規劃(具體來說,是 Python 庫 DEAP 中的 GP 實現)對工作流進行最佳化。在搜尋過程中,任一工作流首先在訓練集上訓練,然後在獨立的驗證集上評估(另一種更為耗時的選項是交叉驗證)。在搜尋結束後,TPOT 將傳回最好的工作流所對應的程式碼。
TPOT 的一個潛在問題在於可能會產生過於複雜的工作流,從而導致過擬合。針對這個問題,論文 [2] 對 TPOT 作出了拓展,將工作流複雜度(即包含的操作節點個數)作為第二個最佳化標的,提出了 TPOT-Pareto,其使用了類似於 NSGA 中所採用的選擇運算元。

▲ 圖4:部分實驗結果
論文 [1] 和 [2] 在很多工上對 TPOT 和 TPOT-Pareto 進行了評估,實驗結果(圖 4 給出了在 UCI 資料集上的部分實驗結果,其中 Random Forest 包含了 500 棵決策樹,TPOT-Random 採用了隨機搜尋而不是 GP)表明瞭 TPOT 系的方法在很多工上都能取得不錯的效果。

▲ 圖5:工作流複雜度對比
圖 5 給出了不同方法得到的模型的複雜度,可以看出 TPOT-Pareto 確實能得到更為精簡的工作流。一個比較有趣的問題是採用隨機搜尋的 TPOT-random 在很多工上(以更高的工作流複雜度)也能夠達到 TPOT 以及 TPOT-Pareto 相當的效果。
TPOT 專案已經開源,且仍在開發迭代中,目前整個社群相當活躍,已經有了 4000+ 的 star 和 680+ 的 fork。
TPOT專案地址:
https://github.com/EpistasisLab/tpot
參考文獻
[1] Olson, Randal S., et al. “Automating biomedical data science through tree-based pipeline optimization.” European Conference on the Applications of Evolutionary Computation. Springer, Cham, 2016.
[2] Olson, Randal S., et al. “Evaluation of a tree-based pipeline optimization tool for automating data science.” Proceedings of the Genetic and Evolutionary Computation Conference 2016. ACM, 2016.
多標的演化最佳化深度神經網路

本文主要側重於分享近期基於多標的演化最佳化深度神經網路的工作。由於筆者能力有限,如果分享過程中存在疏忽,還請大家不吝賜教與指正。
第一個工作發表於 IEEE Transaction on Neural Networks and Learning Systems 2016,來自 Chong Zhang,Pin Lim,K. Qin 和 Kay Chen Tan 的文章 Multiobjective Deep Belief Networks Ensemble for Remaining Useful Life Estimation in Prognostics,本文為預估系統剩餘使用週期設計了多標的深度網路整合演演算法(Multiobjective Deep Belief Networks Ensemble,MODBNE)。
MODBNE 是一個整合學習模型,其以單個 DBN(Deep Belief Networks)模型的準確性和多樣性作為最佳化標的,使用 MOEA/D 演演算法對 DBN 模型進行最佳化,將最終獲得的一系列佔優的 DBN 模型用於整合學習模型。
其中,演化種群中的每一個個體代表一個 DBN 模型,其決策空間由 DBN 模型的隱藏神經元數量、神經網路中的權重以及推理過程中需要的學習率構成,這意味著每一個個體都代表著不同結構的 DBN 模型。
最後,透過以平均學習錯誤率為標的的單標的 DE 演演算法最佳化整合學習模型中各個模型的比重。
MODBNE 在 NASA 的 C-MAPSS 資料集上進行實驗,結果表明該演演算法明顯優於其他現有的演演算法。
第二個工作發表於 IEEE Transaction on Neural Networks and Learning Systems 2017,來自 Jia Liu,Maoguo Gong,Qiguang Miao,Xiaogang Wang 和 Hao Li 的文章 Structure Learning for Deep Neural Networks Based on Multiobjective Optimization,論文提出一種使用多標的最佳化演演算法最佳化深度神經網路的連線結構的方法。
首先,將多層神經網路看成多個單層的神經網路,逐層最佳化。在最佳化每一層的時候,以神經網路的表達能力(Representation Ability)和神經網路連線的稀疏性作為最佳化標的,使用 MOEA/D 演演算法進行最佳化。
其中,演化種群中的每一個個體代表單層神經網路的一種配置,神經網路的表達能力用觀測資料的 PoE(Products of Experts)評估,稀疏性由神經節點之間連線的個數表示。
透過用該演演算法最佳化單層神經網路、多層神經網路以及一些應用層面的神經網路進行測試,實驗驗證該方法可以大幅提升深度神經網路的效率。
演化深度神經網路
演化演演算法和人工神經網路都可以看作是對某些自然過程的抽象。早在上世紀 90 年代早期,就有研究試圖將二者結合起來,並最終形成了演化人工神經網路(Evolutionary Artificial Neural Networks,EANN)這一分支。
EANN 旨在利用演化演演算法強大的搜尋能力在神經網路的多個層面上(全域性引數如學習率,網路拓撲結構,區域性引數如連線權值)尋優。
在實際中,這種利用工具來自動設計演演算法的思路可以在很大程度上減輕演演算法設計者的負擔。同時,在計算資源充足的條件下,針對給定的任務,演化演演算法往往能成功地發現有效的神經網路結構。
近年來,計算能力的大幅提升和大資料時代的到來助推了深度學習的興起,在此期間各種深度神經網路(Deep Neural Networks,DNN)被相繼提出。然而即使在今天,針對特定問題設計有效的深度神經網路仍然是一項非常困難的任務。
以此為背景,利用自動化工具(比如演化演演算法)來設計深度神經網路逐漸受到了學術界的一些關註。本文將同大家分享演化深度神經網路的一項近期工作。由於筆者能力有限,如果分享過程中存在疏忽,還請大家不吝賜教與指正。
由於 DNN 連線數巨大,利用演化演演算法直接最佳化 DNN 權值的計算代價太高。因此一般採用兩層(bilevel)策略對 DNN 進行最佳化,其頂層由演化演演算法最佳化 DNN 的結構和全域性引數,其底層依然採用隨機梯度下降的方法訓練連線權值。
發表在 ICML 2017,來自 Google Brain 的 Esteban Real,Sherry Moore,Andrew Selle,Saurabh Saxena,Yutaka Leon Suematsu,Quoc Le,Alex Kurakin 的文章 Large-Scale Evolution of Image Classifiers,提出了一種針對影象分類的 DNN 的分散式演化演演算法。

▲ 圖1:文章提出的分散式演化演演算法
演演算法的流程如圖 1 所示,該演演算法維護了一個 DNN 種群,種群中每一個個體都是一個已經訓練好的 DNN 模型,其適應度即為該模型在驗證集上的準確率。
大量的計算節點(worker)被用來對 DNN 種群進行演化。具體而言,所有的 worker 處在分散式環境下,共享儲存 DNN 種群的檔案系統,並以非同步的方式工作。
每一個當前空閑的 worker 都會從 DNN 種群中隨機選取兩個 DNN 模型,然後將較差的 DNN 直接從種群中刪除,並基於較好的 DNN 變異生成一個子代個體加入 DNN 種群。
整個過程中個體的編碼是圖,圖上每一個頂點表示一個三階張量(比如摺積層)或者一個啟用函式,每一條邊則表示恆等連線(identity connection)或者摺積。變異操作則包括重置權值,插入刪除神經層,插入刪除神經層之間的連線等等。
實驗中,種群規模被設定為 1000,並有 250 個 worker 參與,在 CIFAR-10 和 CIFAR-100 資料集上的實驗結果如圖 2 所示,相比於手工設計的 DNN,用此分散式演化演演算法得到的 DNN 能夠取得有競爭力的結果。
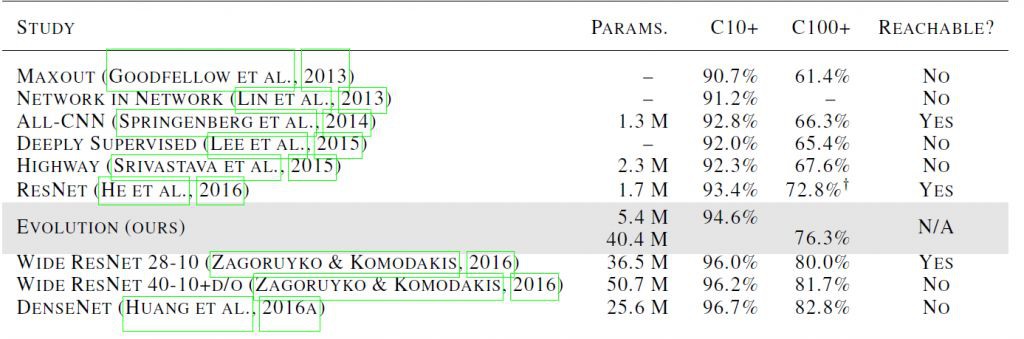 ▲ 圖2:在CIFAR-10和CIFAR-100上的測試結果
▲ 圖2:在CIFAR-10和CIFAR-100上的測試結果
更多論文推薦
最後,再附上 Github 上幾篇進化計算在 AutoML 上的應用論文。

■ 論文 | Evolving Neural Networks through Augmenting Topologies
■ 連結 | https://www.paperweekly.site/papers/1979
■ 作者 | Kenneth O. Stanley / Risto Miikkulainen
Abstract
An important question in neuroevolution is how to gain an advantage from evolving neural network topologies along with weights. We present a method, NeuroEvolution of Augmenting Topologies (NEAT), which outperforms the best fixed-topology method on a challenging benchmark reinforcement learning task. We claim that the increased efficiency is due to (1) employing a principled method of crossover of different topologies, (2) protecting structural innovation using speciation, and (3) incrementally growing from minimal structure. We test this claim through a series of ablation studies that demonstrate that each component is necessary to the system as a whole and to each other. What results is significantly faster learning. NEAT is also an important contribution to GAs because it shows how it is possible for evolution to both optimize and complexify solutions simultaneously, offering the possibility of evolving increasingly complex solutions over generations, and strengthening the analogy with biological evolution.

■ 論文 | Autostacker: A Compositional Evolutionary Learning System
■ 連結 | https://www.paperweekly.site/papers/1980
■ 作者 | Boyuan Chen / Harvey Wu / Warren Mo / Ishanu Chattopadhyay / Hod Lipson
Abstract
We introduce an automatic machine learning (AutoML) modeling architecture called Autostacker, which combines an innovative hierarchical stacking architecture and an Evolutionary Algorithm (EA) to perform efficient parameter search. Neither prior domain knowledge about the data nor feature preprocessing is needed. Using EA, Autostacker quickly evolves candidate pipelines with high predictive accuracy. These pipelines can be used as is or as a starting point for human experts to build on. Autostacker finds innovative combinations and structures of machine learning models, rather than selecting a single model and optimizing its hyperparameters. Compared with other AutoML systems on fifteen datasets, Autostacker achieves state-of-art or competitive performance both in terms of test accuracy and time cost.

■ 論文 | Deep Neuroevolution: Genetic Algorithms Are a Competitive Alternative for Training Deep Neural Networks for Reinforcement Learning
■ 連結 | https://www.paperweekly.site/papers/1981
■ 原始碼 | https://github.com/uber-common/deep-neuroevolution
Abstract
Deep artificial neural networks (DNNs) are typically trained via gradient-based learning algorithms, namely backpropagation. Evolution strategies (ES) can rival backprop-based algorithms such as Q-learning and policy gradients on challenging deep reinforcement learning (RL) problems. However, ES can be considered a gradient-based algorithm because it performs stochastic gradient descent via an operation similar to a finite-difference approximation of the gradient. That raises the question of whether non-gradient-based evolutionary algorithms can work at DNN scales. Here we demonstrate they can: we evolve the weights of a DNN with a simple, gradient-free, population-based genetic algorithm (GA) and it performs well on hard deep RL problems, including Atari and humanoid locomotion. The Deep GA successfully evolves networks with over four million free parameters, the largest neural networks ever evolved with a traditional evolutionary algorithm. These results (1) expand our sense of the scale at which GAs can operate, (2) suggest intriguingly that in some cases following the gradient is not the best choice for optimizing performance, and (3) make immediately available the multitude of neuroevolution techniques that improve performance. We demonstrate the latter by showing that combining DNNs with novelty search, which encourages exploration on tasks with deceptive or sparse reward functions, can solve a high-dimensional problem on which reward-maximizing algorithms (e.g.\ DQN, A3C, ES, and the GA) fail. Additionally, the Deep GA is faster than ES, A3C, and DQN (it can train Atari in ∼4 hours on one desktop or ∼1 hour distributed on 720 cores), and enables a state-of-the-art, up to 10,000-fold compact encoding technique.

■ 論文 | Improving Exploration in Evolution Strategies for Deep Reinforcement Learning via a Population of Novelty-Seeking Agents
■ 連結 | https://www.paperweekly.site/papers/1982
■ 原始碼 | https://github.com/uber-common/deep-neuroevolution
Abstract
Evolution strategies (ES) are a family of black-box optimization algorithms able to train deep neural networks roughly as well as Q-learning and policy gradient methods on challenging deep reinforcement learning (RL) problems, but are much faster (e.g. hours vs. days) because they parallelize better. However, many RL problems require directed exploration because they have reward functions that are sparse or deceptive (i.e. contain local optima), and it is not known how to encourage such exploration with ES. Here we show that algorithms that have been invented to promote directed exploration in small-scale evolved neural networks via populations of exploring agents, specifically novelty search (NS) and quality diversity (QD) algorithms, can be hybridized with ES to improve its performance on sparse or deceptive deep RL tasks, while retaining scalability. Our experiments confirm that the resultant new algorithms, NS-ES and a version of QD we call NSR-ES, avoid local optima encountered by ES to achieve higher performance on tasks ranging from playing Atari to simulated robots learning to walk around a deceptive trap. This paper thus introduces a family of fast, scalable algorithms for reinforcement learning that are capable of directed exploration. It also adds this new family of exploration algorithms to the RL toolbox and raises the interesting possibility that analogous algorithms with multiple simultaneous paths of exploration might also combine well with existing RL algorithms outside ES.

點選以下標題檢視更多精彩文章:

▲ 戳我檢視招募詳情
 #作 者 招 募#
#作 者 招 募#
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 加入社群刷論文
