一、概述
IPFS 和區塊鏈有著非常緊密的聯絡, 隨著區塊鏈的不斷發展,對資料的儲存需求也越來越高, 由於效能和成本的限制,現有的區塊鏈設計方案大部分都選擇了把較大的資料儲存在鏈外,透過對資料進行加密, 雜湊運算等手段來防止資料被篡改, 在區塊鏈上只取用所存資料的hash 值, 從而滿足業務對資料的儲存需求。 本文從IPFS 的底層設計出發, 結合原始碼, 分析了IPFS 的一些技術細節。 由於IPFS還在不斷更新中, 文中取用的部分可能和最新程式碼有所出入。
閱讀本文需要讀者
-
瞭解網路程式設計
-
瞭解分散式儲存
-
瞭解基本的區塊鏈知識
二、什麼是IPFS?
維基百科上是這樣解釋的:是一個旨在建立持久且分散式儲存和共享檔案的網路傳輸協議。
上面的解釋稍顯晦澀, 我的理解是:
1. 首先它是一個FS(檔案系統)
2. 其次它支援點對點傳輸
既然是檔案系統, 那它和普通的檔案系統有什麼區別呢? 有以下幾點區別:
-
儲存方式: 它是分散式儲存的, 為了方便傳輸,檔案被切分成多個block, 每個block 透過hash運算得到唯一的ID, 方便在網路中進行識別和去重。 考慮到傳輸效率, 同一個block 可能有多個copy, 分別儲存在不同的網路節點上。
-
內容定址方式: 每個block都有唯一的ID,我們只需要根據節點的ID 就可以獲取到它所對應的block。
那麼問題來了, 既然檔案被切分成了多個block,如何組織這些block 資料,組成邏輯上的檔案呢? 在IFPS中採用的merkledag, 下麵是 merkledag的一個示意圖:

簡單來說, 就是2種資料結構merkle 和DAG(有向無環圖)的結合, 透過這種邏輯結構, 可以滿足:
-
內容定址: 使用hash ID來唯一識別一個資料塊的內容
-
防篡改: 可以方便的檢查雜湊值來確認資料是否被篡改
-
去重: 由於內容相同的資料塊雜湊是相同的,可以很容去掉重覆的資料,節省儲存空間
確定了資料模型後, 接下來要做的事: 如何把資料分發到不同的網路節點上, 達到分散式儲存和共享的目的? 我們先思考一下, 透過網路,比如HTTP, 訪問某個檔案的步驟,首先我們要知道儲存這個檔案的伺服器地址, 然後我們需要知道這個檔案對應的ID, 比如檔案名。前者我們可以抽象成網路節點定址, 後者我們抽象成檔案物件定址; 在IPFS中, 這兩種定址方式使用了相同的演演算法, KAD, 介紹KAD演演算法的文章很多,這裡不贅述, 只簡單說明一下核心思想:
KAD 最精妙之處就是使用XOR 來計算ID 之間的距離,並且統一了節點ID 和 物件ID的定址方式。 採用 XOR(按位元異或操作)演演算法計算 key 之間的“距離”。
這種做法使得它具備了類似於“幾何距離”的某些特性(下麵用 ⊕ 表示 XOR)
-
(A ⊕ B) == (B ⊕ A) XOR 符合“交換律”,具備對稱性。
-
(A ⊕ A) == 0 反身性,自身距離為零
-
(A ⊕ B) > 0 【不同】的兩個 key 之間的距離必大於零
-
(A ⊕ B) + (B ⊕ C) >= (A ⊕ C) 三角不等式
透過KAD演演算法,IPFS 把不同ID的資料塊分發到與之距離較近的網路節點中,達到分散式儲存的目的。
透過IPFS獲取檔案時,只需要根據merkledag, 按圖索驥,根據每個block的ID, 透過KAD演演算法從相應網路節點中下載block資料, 最後驗證是否資料完整, 完成拼接即可。
下麵我們再從技術實現的角度做更深入的介紹。
三、IPFS的系統架構

我們先看一下IPFS的系統架構圖, 分為5層:
-
一層為naming, 基於PKI的一個名稱空間;
-
第二層為merkledag, IPFS 內部的邏輯資料結構;
-
第三層為exchange, 節點之間block data的交換協議;
-
第四層為routing, 主要實現節點定址和物件定址;
-
第五層為network, 封裝了P2P通訊的連線和傳輸部分。
站在資料的角度來看, 又可以分為2個大的模組:
-
IPLD( InterPlanetary Linked Data) 主要用來定義資料, 給資料建模;
-
libp2p解決的是資料如何傳輸的問題。
下麵分別介紹IFPS 中的2個主要部分IPLD 和 libP2P。
IPLD
透過hash 值來實現內容定址的方式在分散式計算領域得到了廣泛的應用, 比如區塊鏈, 再比如git repo。 雖然使用hash 連線資料的方式有相似之處, 但是底層資料結構並不能通用, IPFS 是個極具野心的專案, 為了讓這些不同領域之間的資料可互操作, 它定義了統一的資料模型IPLD, 透過它, 可以方便地訪問來自不同領域的資料。
前面已經介紹資料的邏輯結構是用merkledag表示的, 那麼它是如何實現的呢? 圍繞merkledag作為核心, 它定義了以下幾個概念:
-
merkle link 代表dag 中的邊
-
merkel-dag 有向無環圖
-
merkle-path 訪問dag節點的類似unix path的路徑
-
IPLD data model 基於json 的資料模型
-
IPLD serialized format 序列化格式
-
canonical 格式: 為了保證同樣的logic object 總是序列化為一個同樣的輸出, 而制定的確定性規則
圍繞這些定義它實現了下麵幾個components
-
CID 內容ID
-
data model 資料模型
-
serialization format 序列化格式
-
tools & libraries 工具和庫
-
IPLD selector 類似CSS 選擇器, 方便選取dag中的節點
-
IPLD transformation 對dag 進行轉換計算
我們知道,資料是多樣性的,為了給不同的資料建模, 我們需要一種通用的資料格式, 透過它可以最大程度地相容不同的資料, IPFS 中定義了一個抽象的集合, multiformat, 包含multihash、multiaddr、multibase、multicodec、multistream幾個部分。
multihash
自識別hash, 由3個部分組成,分別是:hash函式編碼、hash值的長度和hash內容, 下麵是個簡單的例子:
這種設計的最大好處是非常方便升級,一旦有一天我們使用的hash 函式不再安全了, 或者發現了更好的hash 函式,我們可以很方便的升級系統。
multiaddr
自描述地址格式,可以描述各種不同的地址

multibase
multibase 代表的是一種編碼格式, 方便把CID 編碼成不同的格式, 比如這裡定義了2進位制、8進位制、10進位制、16進位制、也有我們熟悉的base58btc 和 base64編碼。

multicodec
mulcodec 代表的是自描述的編解碼, 其實是個table, 用1到2個位元組定了資料內容的格式, 比如用字母z表示base58btc編碼, 0x50表示protobuf 等等。

multistream
multistream 首先是個stream, 它利用multicodec,實現了自描述的功能, 下麵是基於一個javascript 的例子; 先new 一個buffer 物件, 裡面是json物件, 然後給它加一個字首protobuf, 這樣這個multistream 就構造好了, 可以透過網路傳輸。在解析時可以先取codec 字首,然後移除字首, 得到具體的資料內容。

結合上面的部分, 我們重點介紹一下CID。
CID 是IPFS分散式檔案系統中標準的檔案定址格式,它集合了內容定址、加密雜湊演演算法和自我描述的格式, 是IPLD 內部核心的識別符。目前有2個版本,CIDv0 和CIDv1。
CIDv0是一個向後相容的版本,其中:
-
multibase 一直為 base58btc
-
multicodec 一直為 protobuf-mdag
-
version 一直為 CIDv0
-
multihash 表示為cidv0 ::=
為了更靈活的表述ID資料, 支援更多的格式, IPLD 定義了CIDv1,CIDv1由4個部分組成:
-
multibase
-
version
-
multicodec
-
multihash
IPLD 是IPFS 的資料描述格式, 解決瞭如何定義資料的問題, 下麵這張圖是結合原始碼整理的一份邏輯圖,我們可以看到上面是一些高階的介面, 比如file, mfs, fuse 等。 下麵是資料結構的持久化部分,節點之間交換的內容是以block 為基礎的, 最下麵就是物理儲存了。比如block 儲存在blocks 目錄, 其他節點之間的資訊儲存在leveldb, 還有keystore, config 等。
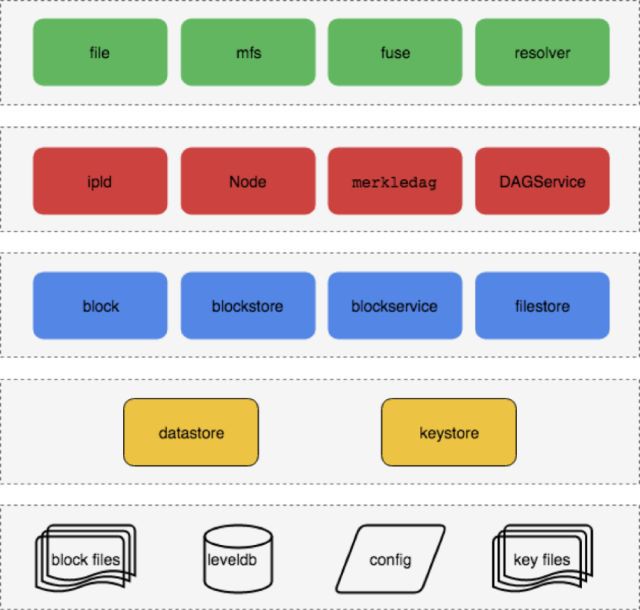
資料如何傳輸呢?
接下來我們介紹libP2P, 看看資料是如何傳輸的。libP2P 是個模組化的網路協議棧。

做過socket程式設計的小夥伴應該都知道, 使用raw socket 程式設計傳輸資料的過程,無非就是以下幾個步驟:
-
獲取標的伺服器地址
-
和標的伺服器建立連線
-
握手協議
-
傳輸資料
-
關閉連線
libP2P 也是這樣,不過區別在於它把各個部分都模組化了, 定義了通用的介面, 可以很方便的進行擴充套件。
架構圖

由以下幾個部分組成,分別是:
-
Peer Routing
-
Swarm (傳輸和連線)
-
Distributed Record Store
-
Discovery
下麵我們對它們做分別介紹, 我們先看關鍵的路由部分。
Peer Routing
libP2P定義了routing 介面,目前有2個實現,分別是KAD routing 和 MDNS routing, 擴充套件很容易, 只要按照介面實現相應的方法即可。
ipfs 中的節點路由表是透過維護多個K-BUCKET來實現的, 每次新增節點, 會計算節點ID 和自身節點ID 之間的common prefix, 根據這個公共字首把節點加到對應的KBUCKET 中, KBUCKET 最大值為20, 當超出時,再進行拆分。

更新路由表的流程如下:

除了KAD routing 之外, IPFS 也實現了MDNS routing, 主要用來在區域網內發現節點, 這個功能相對比較獨立, 由於用到了多播地址, 在一些公有雲部署環境中可能無法工作。
Swarm(傳輸和連線)
swarm 定義了以下介面:
-
transport 網路傳輸層的介面
-
connection 處理網路連線的介面
-
stream multiplex 同一connection 復用多個stream的介面
下麵我們重點看下是如何動態協商stream protocol 的,整個流程如下:

-
預設先透過multistream-select 完成握手
-
發起方嘗試使用某個協議, 接收方如果不接受, 再嘗試其他協議, 直到找到雙方都支援的協議或者協商失敗。
另外為了提高協商效率, 也提供了一個ls 訊息, 用來查詢標的節點支援的全部協議。
Distributed Record Store
record 表示一個記錄, 可以用來儲存一個鍵值對,比如ipns name publish 就是釋出一個objectId 系結指定 node id 的record 到ipfs 網路中, 這樣透過ipns 定址時就會查詢對應的record, 再解析到objectId, 實現定址的功能。
Discovery
目前系統支援3種發現方式, 分別是:
-
bootstrap 透過配置的啟動節點發現其他的節點
-
random walk 透過查詢隨機生成的peerID, 從而發現新的節點
-
mdns 透過multicast 發現區域網內的節點
最後總結一下原始碼中的邏輯模組:

從下到上分為5個層次:
-
最底層為傳輸層, 主要封裝各種協議, 比如TCP,SCTP, BLE, TOR 等網路協議
-
傳輸層上面封裝了連線層,實現連線管理和通知等功能
-
連線層上面是stream 層, 實現了stream的多路復用
-
stream層上面是路由層
-
最上層是discovery, messaging以及record store 等
四、總結
本文從定義資料和傳輸資料的角度分別介紹了IPFS的2個主要模組IPLD 和 libP2P:
-
IPLD 主要用來定義資料, 給資料建模
-
libP2P 解決資料傳輸問題
這兩部分相輔相成, 雖然都源自於IPFS專案,但是也可以獨立使用在其他專案中。
IPFS的遠景標的就是替換現在瀏覽器使用的 HTTP 協議, 目前專案還在迭代開發中, 一些功能也在不斷完善。為瞭解決資料的持久化問題, 引入了filecoin 激勵機制, 透過token激勵,讓更多的節點加入到網路中來,從而提供更穩定的服務。
活動預告:
6 月 1 ~ 2 日,GIAC 全球網際網路架構大會將於深圳舉行。GIAC 是高可用架構技術社群推出的面向架構師、技術負責人及高階技術從業人員的技術架構大會。今年的 GIAC 已經有騰訊、阿裡巴巴、百度、今日頭條、科大訊飛、新浪微博、小米、美圖、Oracle、鏈家、唯品會、京東、餓了麼、美團點評、羅輯思維、ofo、迅雷、曠視、LinkedIn、Pivotal 等公司專家出席。
本期 GIAC 大會上,區塊鏈部分精彩的議題如下:



參加 GIAC,盤點2018最新技術。點選“閱讀原文”瞭解大會更多詳情。
