作者:SHUBHAM JAIN 翻譯:和中華 校對:丁楠雅
本文約3500字,建議閱讀20分鐘。
本文簡單介紹了什麼是正則化以及在深度學習任務中可以採用哪些正則化技術,並以keras程式碼具體講解了一個案例。
簡介
資料科學家面臨的常見問題之一是如何避免過擬合。你是否碰到過這樣一種情況:你的模型在訓練集上表現異常好,卻無法預測測試資料。或者在一個競賽中你排在public leaderboard的頂端,但是在最終排名中卻落後了幾百名?那麼這篇文章就是為你而準備的!
(譯者註: 在kaggle這樣的資料競賽中, public leaderboard排名是根據一部分測試集來計算的,用於給選手提供及時的反饋和動態展示比賽的進行情況;而private leaderboard是根據測試集的剩餘部分計算而來,用於計算選手的最終得分和排名。 通常我們可以把public LB理解為在驗證集上的得分,private LB為真正未知資料集上的得分,這樣做的目的是提醒參賽者,我們建模的標的是獲取一個泛化能力好的模型)
避免過擬合可以提高我們模型的效能。

目錄
1. 什麼是正則化?
2. 正則化如何減少過擬合?
3. 深度學習中的各種正則化技術:
-
L2和L1正則化
-
Dropout
-
資料增強(Data augmentation)
-
提前停止(Early stopping)
4. 案例:在MNIST資料集上使用Keras的案例研究
1. 什麼是正則化?
在深入該主題之前,先來看看這幾幅圖:

之前見過這幅圖嗎?從左到右看,我們的模型從訓練集的噪音資料中學習了過多的細節,最終導致模型在未知資料上的效能不好。
換句話說,從左向右,模型的複雜度在增加以至於訓練誤差減少,然而測試誤差未必減少。如下圖所示:

Source: Slideplayer
如果你曾經構建過神經網路,你就知道它們有多複雜。這也使得它們更容易過擬合。

正則化技術是對學習演演算法做輕微的修改使得它泛化能力更強。這反過來就改善了模型在未知資料上的效能。
2. 正則化如何減少過擬合?
我們來看一個在訓練資料上過擬合的神經網路,如下圖所示:

如果你曾經學習過機器學習中的正則化,你會有一個概念,即正則化懲罰了繫數。在深度學習中,它實際上懲罰了節點的權重矩陣。
假設我們的正則化繫數很高,以至於某些權重矩陣近乎於0:

這會得到一個簡單的線性網路,而且在訓練資料集上輕微的欠擬合。
如此大的正則化繫數並不是那麼有用。我們需要對其進行最佳化從而得到一個擬合良好的模型,正如下圖所示:
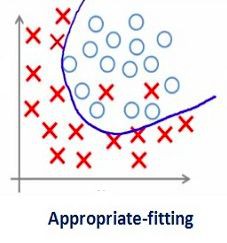
3. 深度學習中的各種正則化技術
我們已經理解了正則化如何幫助減少過擬合,現在我們將學習一些把正則化用於深度學習的技術。
-
L1和L2正則化
L1和L2是最常見的正則化型別。它們透過增加一個被稱為正則項的額外項來更新成本函式:
Cost function = Loss (say, binary cross entropy) + Regularization term
由於增加了這個正則項,權重矩陣的值減小了,因為這裡假定了具有較小權重矩陣的神經網路會導致更簡單的模型。因此,它也會在相當程度上減少過擬合。
然而,該正則項在L1和L2中是不同的。
L2中,我們有:

這裡,lambda是正則引數。它是一個超引數用來最佳化得到更好的結果。L2正則化也叫權重衰減(weight decay),因為它強制權重朝著0衰減(但不會為0)
在L1中,我們有:

這裡,我們懲罰了權重的絕對值。不像L2, 這裡的權重是有可能衰減到0的。因此,當我們想壓縮模型的時候, L1非常有用,否則會偏向使用L2.
在Keras中,我們可以使用regularizers直接在任意層上應用正則化。
下麵是一段樣例代碼,把L2正則化用於一層之上:
from keras import regularizers
model.add(Dense(64, input_dim=64,
kernel_regularizer=regularizers.l2(0.01)
註意:這裡的值0.01是正則化引數的值,即lambda, 它需要被進一步優化。可以使用grid-search的方法來優化它。
同樣的,我們也可以採用L1正則化。後文中的案例研究會看到更多細節。
-
Dropout
這是一種非常有趣的正則化技術。它的效果非常好因此在深度學習領域中最常被使用。
為了理解dropout,假設我們的神經網路結構如下所示:

dropout做什麼呢?每次迭代,隨機選擇一些節點,將它們連同相應的輸入和輸出一起刪掉,如下圖:

所以,每一輪迭代都有不同的節點集合,這也導致了不同的輸出。它也可以被認為是一種機器學習中的整合技術(ensemble technique)。
整合模型(ensemble models)通常比單一模型表現更好,因為捕獲了更多的隨機性。同樣的,比起正常的神經網路模型,dropout也表現的更好。
選擇丟棄多少節點的機率是dropout函式的超引數。如上圖所示,dropout可以被用在隱藏層以及輸入層。

由於這些原因,當我們有較大的神經網路時,為了引入更多的隨機性,通常會優先使用dropout。
在Keras中,可以使用Keras core layer來實現dropout。下麵是對應的Python程式碼:
from keras.layers.core import Dropout
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation=’relu’),
Dropout(0.25),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation=’softmax’),
])
正如你看到的,這裡定義丟棄機率為0.25。我們可以使用grid search方法來微調它以獲得更好的結果。
-
資料增強(Data augmentation)
減少過擬合最簡單的方式其實是增加訓練集的大小。在機器學習中,由於人工標註資料成本過高所以很難增加訓練集的大小。
但是,考慮一下如果我們處理的是影象。在這種情況下,有一些方法可以增加訓練集的大小——旋轉、翻轉、縮放、移動等等。下圖中,對手寫數字資料集進行了一些轉換:

這種技術叫做資料增強。通常會明顯改善模型的準確率。為了提高模型預測能力,這種技術可以被視為一種強制性技巧。
在Keras中,我們使用ImageDataGenerator來執行所有這些轉換。它有一大堆引數,你可以用它們來預處理你的訓練資料。
下麵是示例程式碼:
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(horizontal flip=True)
datagen.fit(train)
-
提前停止(Early stopping)
提前停止是一種交叉驗證的策略,即把一部分訓練集保留作為驗證集。當看到驗證集上的效能變差時,就立即停止模型的訓練。

在上圖中,我們在虛線處停止模型的訓練,因為在此處之後模型會開始在訓練資料上過擬合。
在Keras中,使用callbacks函式來應用提前停止。下麵是程式碼:
from keras.callbacks import EarlyStopping
EarlyStopping(monitor=’val_err’, patience=5)
這裡的monitor是表示需要監視的量,‘val_err’代表驗證集錯誤.
Patience表示在該數量的epochs內沒有進一步的效能改進後,就停止訓練。為了更好地理解,我們再看看上面的圖。在虛線之後,每個epoch都會導致一個更高的驗證集錯誤。因此,在虛線之後的5個epoch(因為我們設定patience等於5),由於沒有進一步的改善,模型將停止訓練。
註意:可能在5個epoch之後(這是一般情況下為patience設定的值)模型再次開始改進,並且驗證集錯誤也開始減少。因此,在調整這個超引數的時候要格外小心。
-
在MNIST資料集上使用Keras的案例研究
至此,你應該對我們提到的各種技術有了一個理論上的理解。現在我們把這些知識用在深度學習實際問題上——識別數字。下載完資料集之後,你就可以開始下麵的程式碼。首先,我們匯入一些基本的庫。
%pylab inline
import numpy as np
import pandas as pd
from scipy.misc import imread
from sklearn.metrics import accuracy_score
from matplotlib import pyplot
import tensorflow as tf
import keras
# To stop potential randomness
seed = 128
rng = np.random.RandomState(seed)
現在,載入資料。
現在拿一些圖片來看看。
img_name = rng.choice(train.filename)
filepath = os.path.join(data_dir, ‘Train’, ‘Images’, ‘train’, img_name)
img = imread(filepath, flatten=True)
pylab.imshow(img, cmap=’gray’)
pylab.axis(‘off’)
pylab.show()
#storing images in numpy arrays
temp = []
for img_name in train.filename:
image_path = os.path.join(data_dir, ‘Train’, ‘Images’, ‘train’, img_name)
img = imread(image_path, flatten=True)
img = img.astype(‘float32’)
temp.append(img)
x_train = np.stack(temp)
x_train /= 255.0
x_train = x_train.reshape(-1, 784).astype(‘float32’)
y_train = keras.utils.np_utils.to_categorical(train.label.values)
建立一個驗證集,以便最佳化我們的模型以獲得更好的分數。我們將採用70:30的訓練集、驗證集比例。
split_size = int(x_train.shape[0]*0.7)
x_train, x_test = x_train[:split_size], x_train[split_size:]
y_train, y_test = y_train[:split_size], y_train[split_size:]
首先,我們先建立一個具有5個隱藏層,每層500個節點的簡單神經網路。
# import keras modules
from keras.models import Sequential
from keras.layers import Dense
# define vars
input_num_units = 784
hidden1_num_units = 500
hidden2_num_units = 500
hidden3_num_units = 500
hidden4_num_units = 500
hidden5_num_units = 500
output_num_units = 10
epochs = 10
batch_size = 128
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation=’relu’),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation=’relu’),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation=’relu’),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation=’relu’),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation=’relu’),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation=’softmax’),
])
註意,我們只執行10個epoch,快速檢查一下模型的效能。
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))

現在,我們嘗試用L2正則化,並檢查它是否給出了比簡單神經網路更好的效能。
from keras import regularizers
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation=’relu’,
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation=’relu’,
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation=’relu’,
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation=’relu’,
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation=’relu’,
kernel_regularizer=regularizers.l2(0.0001)),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation=’softmax’),
])
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))
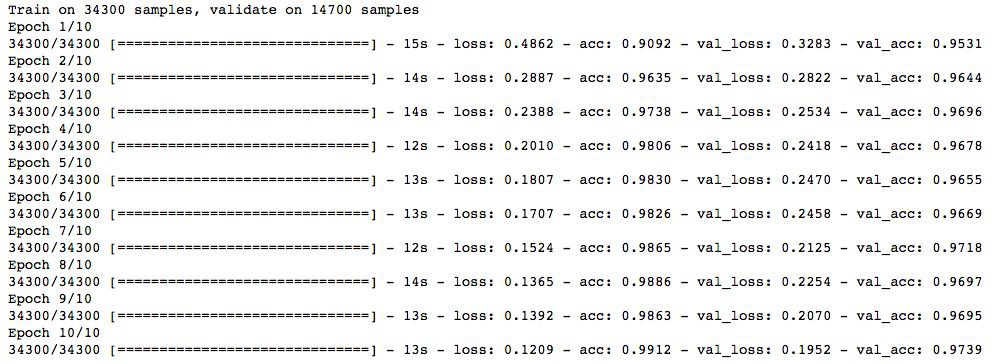
註意這裡lambda的值等於0.0001. 太棒了!我們獲得了一個比之前NN模型更好的準確率。
現在嘗試一下L1正則化。
## l1
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation=’relu’,
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation=’relu’,
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation=’relu’,
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation=’relu’,
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation=’relu’,
kernel_regularizer=regularizers.l1(0.0001)),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation=’softmax’),
])
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))

這次並沒有顯示出任何的改善。我們再來試試dropout技術。
## dropout
from keras.layers.core import Dropout
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation=’relu’),
Dropout(0.25),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation=’relu’),
Dropout(0.25),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation=’relu’),
Dropout(0.25),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation=’relu’),
Dropout(0.25),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation=’relu’),
Dropout(0.25),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation=’softmax’),
])
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))

效果不錯!dropout也在簡單NN模型上給出了一些改善。
現在,我們試試資料增強。
from keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(zca_whitening=True)
# loading data
train = pd.read_csv(os.path.join(data_dir, ‘Train’, ‘train.csv’))
temp = []
for img_name in train.filename:
image_path = os.path.join(data_dir, ‘Train’, ‘Images’, ‘train’, img_name)
img = imread(image_path, flatten=True)
img = img.astype(‘float32’)
temp.append(img)
x_train = np.stack(temp)
X_train = x_train.reshape(x_train.shape[0], 1, 28, 28)
X_train = X_train.astype(‘float32’)
現在,擬合訓練資料以便增強。
# fit parameters from data
datagen.fit(X_train)
這裡,我使用了zca_whitening作為引數,它突出了每個數字的輪廓,如下圖所示:
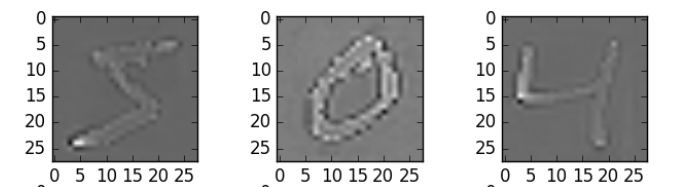
## splitting
y_train = keras.utils.np_utils.to_categorical(train.label.values)
split_size = int(x_train.shape[0]*0.7)
x_train, x_test = X_train[:split_size], X_train[split_size:]
y_train, y_test = y_train[:split_size], y_train[split_size:]
## reshaping
x_train=np.reshape(x_train,(x_train.shape[0],-1))/255
x_test=np.reshape(x_test,(x_test.shape[0],-1))/255
## structure using dropout
from keras.layers.core import Dropout
model = Sequential([
Dense(output_dim=hidden1_num_units, input_dim=input_num_units, activation=’relu’),
Dropout(0.25),
Dense(output_dim=hidden2_num_units, input_dim=hidden1_num_units, activation=’relu’),
Dropout(0.25),
Dense(output_dim=hidden3_num_units, input_dim=hidden2_num_units, activation=’relu’),
Dropout(0.25),
Dense(output_dim=hidden4_num_units, input_dim=hidden3_num_units, activation=’relu’),
Dropout(0.25),
Dense(output_dim=hidden5_num_units, input_dim=hidden4_num_units, activation=’relu’),
Dropout(0.25),
Dense(output_dim=output_num_units, input_dim=hidden5_num_units, activation=’softmax’),
])
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test))

哇!我們在準確率得分上有了一個飛躍。並且好訊息是它每次都奏效。我們只需要根據資料集中的影象來選擇一個合適的引數。
現在,試一下最後一種技術——提前停止。
from keras.callbacks import EarlyStopping
model.compile(loss=’categorical_crossentropy’, optimizer=’adam’, metrics=[‘accuracy’])
trained_model_5d = model.fit(x_train, y_train, nb_epoch=epochs, batch_size=batch_size, validation_data=(x_test, y_test)
, callbacks = [EarlyStopping(monitor=’val_acc’, patience=2)])
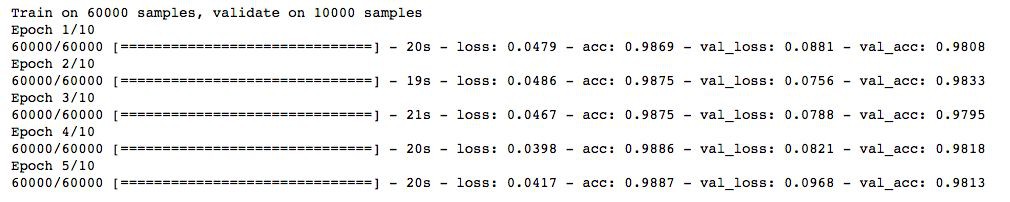
可以看到我們的模型在僅僅5輪迭代後就停止了,因為驗證集準確率不再提高了。當我們使用更大值的epochs來執行它時,它會給出好的結果。你可以說它是一種最佳化epoch值的技術。
結語
我希望現在你已經理解了正則化以及在深度學習模型中實現正則化的不同技術。 無論你處理任何深度學習任務,我都強烈建議你使用正則化。它將幫助你開闊視野並更好的理解這個主題。
原文連結:
https://www.analyticsvidhya.com/blog/2018/04/fundamentals-deep-learning-regularization-techniques/
譯者簡介:和中華,留德軟體工程碩士。由於對機器學習感興趣,碩士論文選擇了利用遺傳演演算法思想改進傳統kmeans。目前在杭州進行大資料相關實踐。加入資料派THU希望為IT同行們盡自己一份綿薄之力,也希望結交許多志趣相投的小夥伴。
END
版權宣告:本號內容部分來自網際網路,轉載請註明原文連結和作者,如有侵權或出處有誤請和我們聯絡。
關聯閱讀:
原創系列文章:
資料運營 關聯文章閱讀:
資料分析、資料產品 關聯文章閱讀:
