
使用者透過瀏覽器瀏覽網站的過程:
使用者瀏覽器(socket客戶端)
客戶端往服務端發訊息
客戶端接收訊息
關閉
網站伺服器(socket服務端)
啟動,監聽
等待客戶端連線
服務端收訊息
服務端回訊息
關閉(一般都不會關閉)
下麵,我們先寫一個服務端程式,來模擬瀏覽器伺服器訪問過程。

你會發現,執行程式之後並且用瀏覽器訪問 127.0.0.1:8001 ,程式會報錯,瀏覽器顯示“該網頁無法正常運作”,如下圖
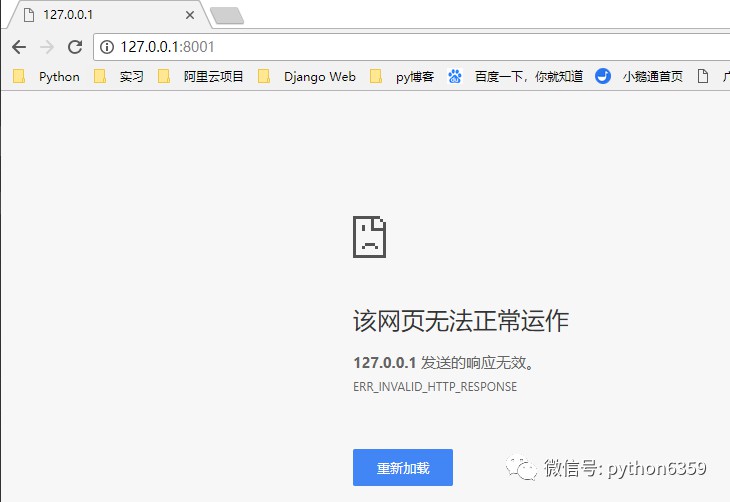
為什麼呢?這時候就要引出 HTTP 協議了。
HTTP協議
HTTP是一個客戶端終端(使用者)和伺服器端(網站)請求和應答的標準(TCP)。
HTTP請求/響應步驟:
1. 客戶端連線到Web伺服器
一個HTTP客戶端,通常是瀏覽器,與Web伺服器的HTTP埠(預設為80)建立一個TCP套接字連線。
2. 傳送HTTP請求
透過TCP套接字,客戶端向Web伺服器傳送一個文字的請求報文,一個請求報文由請求行、請求頭部、空行和請求資料4部分組成。
3. 伺服器接受請求並傳回HTTP響應
Web伺服器解析請求,定位請求資源。伺服器將資源複本寫到TCP套接字,由客戶端讀取。一個響應由狀態行、響應頭部、空行和響應資料4部分組成。
4. 釋放連線TCP連線
若connection 樣式為close,則伺服器主動關閉TCP連線,客戶端被動關閉連線,釋放TCP連線;若connection 樣式為keepalive,則該連線會保持一段時間,在該時間內可以繼續接收請求;
5. 客戶端瀏覽器解析HTML內容
客戶端瀏覽器首先解析狀態行,查看錶明請求是否成功的狀態程式碼。然後解析每一個響應頭,響應頭告知以下為若干位元組的HTML檔案和檔案的字符集。客戶端瀏覽器讀取響應資料HTML,根據HTML的語法對其進行格式化,併在瀏覽器視窗中顯示。
瀏覽器和服務端通訊都要遵循一個HTTP協議(訊息的格式要求)
關於HTTP協議:
1. 瀏覽器往服務端發的叫 請求(request)
請求的訊息格式:
請求方法 路徑 HTTP/1.1\r\n
k1:v1\r\n
k2:v2\r\n
\r\n
請求資料
2. 服務端往瀏覽器發的叫 響應(response)
響應的訊息格式:
HTTP/1.1 狀態碼 狀態描述符\r\n
k1:v1\r\n
k2:v2\r\n
\r\n
響應正文
HTTP請求報文格式:

HTTP響應報文格式:
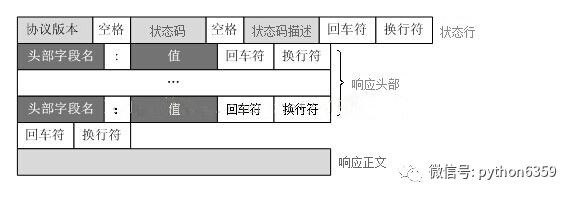
再回到我們剛才的程式,程式報錯的原因是接收到了瀏覽器的訪問報文請求,但是我們的伺服器程式在響應的時候並沒有按照HTTP響應格式(一個響應由狀態行、響應頭部、空行和響應資料4部分組成)進行回應,所以瀏覽器在處理伺服器的響應的時候就會出錯。
因此,我們要在傳送給瀏覽器的響應中按照HTTP響應格式加上 狀態行、響應頭部、空行和響應資料 這四部分。

這時候,在瀏覽器上面就可以看到正確的頁面了,並且可以調出Chrome的開發者工具檢視到我們傳過來的HTTP響應格式。
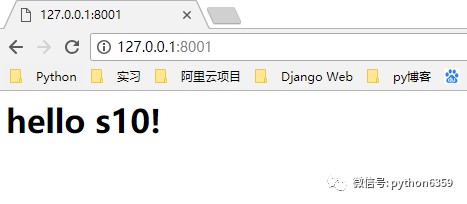
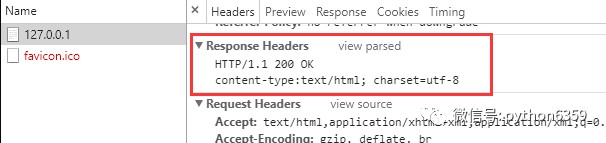
根據不同的路徑傳回不同的內容
細心的你可能會發現,現在無論我們輸出什麼樣的路徑,只要保持 IP 和埠號不變,瀏覽器頁面顯示的都是同樣的內容,這不太符合我們日常的使用場景。
如果我想根據不同的路徑傳回不同的內容,應該怎麼辦呢?
這時候就需要我們把伺服器收到的請求報文進行解析,讀取到其中的訪問路徑。
觀察收到的HTTP請求,會發現,它們的請求行、請求頭部、請求資料是以 \r\n 進行分隔的,所以我們可以根據 \r\n 對收到的請求進行分隔,取出我們想要的訪問路徑。
-
""" -
完善的web服務端示例 -
根據不同的路徑傳回不同的內容 -
""" -
-
import socket -
-
# 生成socket實體物件 -
sk = socket.socket() -
# 系結IP和埠 -
sk.bind(("127.0.0.1", 8001)) -
# 監聽 -
sk.listen() -
-
# 寫一個死迴圈,一直等待客戶端來連線 -
while 1: -
# 獲取與客戶端的連線 -
conn, _ = sk.accept() -
# 接收客戶端發來訊息 -
data = conn.recv(8096) -
# 把收到的資料轉成字串型別 -
data_str = str(data, encoding="utf-8") # bytes("str", enconding="utf-8") -
# print(data_str) -
# 用\r\n去切割上面的字串 -
l1 = data_str.split("\r\n") -
# l1[0]獲得請求行,按照空格切割上面的字串 -
l2 = l1[0].split() -
# 請求行格式為:請求方法 URL 協議版本,因此 URL 是 l2[1] -
url = l2[1] -
# 給客戶端回覆訊息 -
conn.send(b'http/1.1 200 OK\r\ncontent-type:text/html; charset=utf-8\r\n\r\n') -
# 想讓瀏覽器在頁面上顯示出來的內容都是響應正文 -
-
# 根據不同的url傳回不同的內容 -
if url == "/yimi/": -
response = b'hello yimi!
'
-
elif url == "/xiaohei/": -
response = b'hello xiaohei!
'
-
else: -
response = b'404! not found!
'
-
conn.send(response) -
# 關閉 -
conn.close() -
sk.close()
這時候,我們訪問不同的路徑,例如 http://127.0.0.1:8001/yimi/ http://127.0.0.1:8001/xiaohei/ 會在瀏覽器上顯示不一樣的內容
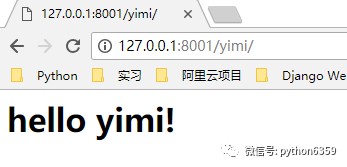

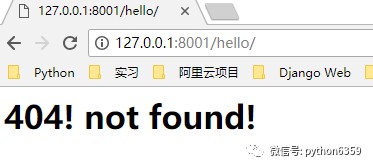
可以看到,我們現在的程式邏輯不是很清晰,我們可以改一下,url 用一個串列存起來,url 對應的響應分別寫成一個個函式,透過函式呼叫進行 url 訪問,你會發現,這跟某個框架的處理方式很像很像(偷笑罒ω罒~~~)
-
""" -
完善的web服務端示例 -
函式版根據不同的路徑傳回不同的內容 -
進階函式版 不寫if判斷了,用url名字去找對應的函式名 -
""" -
-
import socket -
-
# 生成socket實體物件 -
sk = socket.socket() -
# 系結IP和埠 -
sk.bind(("127.0.0.1", 8001)) -
# 監聽 -
sk.listen() -
-
# 定義一個處理/yimi/的函式 -
def yimi(url): -
ret = 'hello {}
'.format(url)
-
# 因為HTTP傳的是位元組,所以要把上面的字串轉成位元組 -
return bytes(ret, encoding="utf-8") -
-
-
# 定義一個處理/xiaohei/的函式 -
def xiaohei(url): -
ret = 'hello {}
'.format(url)
-
return bytes(ret, encoding="utf-8") -
-
-
# 定義一個專門用來處理404的函式 -
def f404(url): -
ret = "你訪問的這個{} 找不到
".format(url)
-
return bytes(ret, encoding="utf-8") -
-
-
url_func = [ -
("/yimi/", yimi), -
("/xiaohei/", xiaohei), -
] -
-
-
# 寫一個死迴圈,一直等待客戶端來連我 -
while 1: -
# 獲取與客戶端的連線 -
conn, _ = sk.accept() -
# 接收客戶端發來訊息 -
data = conn.recv(8096) -
# 把收到的資料轉成字串型別 -
data_str = str(data, encoding="utf-8") # bytes("str", enconding="utf-8") -
# print(data_str) -
# 用\r\n去切割上面的字串 -
l1 = data_str.split("\r\n") -
# print(l1[0]) -
# 按照空格切割上面的字串 -
l2 = l1[0].split() -
url = l2[1] -
# 給客戶端回覆訊息 -
conn.send(b'http/1.1 200 OK\r\ncontent-type:text/html; charset=utf-8\r\n\r\n') -
# 想讓瀏覽器在頁面上顯示出來的內容都是響應正文 -
-
# 根據不同的url傳回不同的內容 -
# 去url_func裡面找對應關係 -
for i in url_func: -
if i[0] == url: -
func = i[1] -
break -
# 找不到對應關係就預設執行f404函式 -
else: -
func = f404 -
-
# 拿到函式的執行結果 -
response = func(url) -
# 將函式傳回的結果傳送給瀏覽器 -
conn.send(response) -
# 關閉連線 -
conn.close()
傳回具體的 HTML 頁面
現在,你可能會在想,目前我們想要傳回的內容是透過函式進行傳回的,傳回的都是一些簡單地位元組,如果我想要傳回一個已經寫好的精美的 HTML 頁面應該怎麼辦呢?
我們可以把寫好的 HTML 頁面以二進位制的形式讀取進來,傳回給瀏覽器,瀏覽器再進行解析,這就可以啦!
-
""" -
完善的web服務端示例 -
函式版根據不同的路徑傳回不同的內容 -
進階函式版 不寫if判斷了,用url名字去找對應的函式名 -
傳回html頁面 -
""" -
-
import socket -
-
# 生成socket實體物件 -
sk = socket.socket() -
# 系結IP和埠 -
sk.bind(("127.0.0.1", 8001)) -
# 監聽 -
sk.listen() -
-
-
# 定義一個處理/yimi/的函式 -
def yimi(url): -
# 以二進位制的形式讀取 -
with open("yimi.html", "rb") as f: -
ret = f.read() -
return ret -
-
-
# 定義一個處理/xiaohei/的函式 -
def xiaohei(url): -
with open("xiaohei.html", "rb") as f: -
ret = f.read() -
return ret -
-
-
# 定義一個專門用來處理404的函式 -
def f404(url): -
ret = "你訪問的這個{} 找不到
".format(url)
-
return bytes(ret, encoding="utf-8") -
-
-
# 使用者訪問的路徑和後端要執行的函式的對應關係 -
url_func = [ -
("/yimi/", yimi), -
("/xiaohei/", xiaohei), -
] -
-
-
# 寫一個死迴圈,一直等待客戶端來連我 -
while 1: -
# 獲取與客戶端的連線 -
conn, _ = sk.accept() -
# 接收客戶端發來訊息 -
data = conn.recv(8096) -
# 把收到的資料轉成字串型別 -
data_str = str(data, encoding="utf-8") # bytes("str", enconding="utf-8") -
# print(data_str) -
# 用\r\n去切割上面的字串 -
l1 = data_str.split("\r\n") -
# print(l1[0]) -
# 按照空格切割上面的字串 -
l2 = l1[0].split() -
url = l2[1] -
# 給客戶端回覆訊息 -
conn.send(b'http/1.1 200 OK\r\ncontent-type:text/html; charset=utf-8\r\n\r\n') -
# 想讓瀏覽器在頁面上顯示出來的內容都是響應正文 -
-
# 根據不同的url傳回不同的內容 -
# 去url_func裡面找對應關係 -
for i in url_func: -
if i[0] == url: -
func = i[1] -
break -
# 找不到對應關係就預設執行f404函式 -
else: -
func = f404 -
# 拿到函式的執行結果 -
response = func(url) -
# 將函式傳回的結果傳送給瀏覽器 -
conn.send(response) -
# 關閉連線 -
conn.close()


傳回動態 HTML 頁面
這時候,你可能又會納悶,現在傳回的都是些靜態的、固定的 HTML 頁面,如果我想傳回一個動態的 HTML 頁面,應該怎麼辦?
動態的網頁,本質上都是字串的替換,字串替換髮生服務端,替換完再傳回給瀏覽器。
這裡,我們透過傳回一個當前時間,來模擬動態 HTML 頁面的傳回過程。
-
""" -
完善的web服務端示例 -
函式版根據不同的路徑傳回不同的內容 -
進階函式版 不寫if判斷了,用url名字去找對應的函式名 -
傳回html頁面 -
傳回動態的html頁面 -
""" -
-
import socket -
import time -
-
# 生成socket實體物件 -
sk = socket.socket() -
# 系結IP和埠 -
sk.bind(("127.0.0.1", 8001)) -
# 監聽 -
sk.listen() -
-
# 定義一個處理/yimi/的函式 -
def yimi(url): -
with open("yimi.html", "r", encoding="utf-8") as f: -
ret = f.read() -
# 得到替換後的字串 -
ret2 = ret.replace("@@xx@@", str(time.ctime())) -
return bytes(ret2, encoding="utf-8") -
-
-
# 定義一個處理/xiaohei/的函式 -
def xiaohei(url): -
with open("xiaohei.html", "rb") as f: -
ret = f.read() -
return ret -
-
-
# 定義一個專門用來處理404的函式 -
def f404(url): -
ret = "你訪問的這個{} 找不到".format(url) -
return bytes(ret, encoding="utf-8") -
-
-
url_func = [ -
("/yimi/", yimi), -
("/xiaohei/", xiaohei), -
] -
-
-
# 寫一個死迴圈,一直等待客戶端來連我 -
while 1: -
# 獲取與客戶端的連線 -
conn, _ = sk.accept() -
# 接收客戶端發來訊息 -
data = conn.recv(8096) -
# 把收到的資料轉成字串型別 -
data_str = str(data, encoding="utf-8") # bytes("str", enconding="utf-8") -
# print(data_str) -
# 用\r\n去切割上面的字串 -
l1 = data_str.split("\r\n") -
# print(l1[0]) -
# 按照空格切割上面的字串 -
l2 = l1[0].split() -
url = l2[1] -
# 給客戶端回覆訊息 -
conn.send(b'http/1.1 200 OK\r\ncontent-type:text/html; charset=utf-8\r\n\r\n') -
# 想讓瀏覽器在頁面上顯示出來的內容都是響應正文 -
-
# 根據不同的url傳回不同的內容 -
# 去url_func裡面找對應關係 -
for i in url_func: -
if i[0] == url: -
func = i[1] -
break -
# 找不到對應關係就預設執行f404函式 -
else: -
func = f404 -
# 拿到函式的執行結果 -
response = func(url) -
# 將函式傳回的結果傳送給瀏覽器 -
conn.send(response) -
# 關閉連線 -
conn.close() -
-
lang="en"> -
-
charset="UTF-8"> -
yimi
style="background-color: pink">這是yimi的小站!
可以看到,現在我們每一次訪問 yimi 頁面,都會傳回一個當前時間。


小結一下
1. web 框架的本質:
socket 服務端 與 瀏覽器的通訊
2. socket 服務端功能劃分:
a. 負責與瀏覽器收發訊息( socket 通訊) --> wsgiref/uWsgi/gunicorn...
b. 根據使用者訪問不同的路徑執行不同的函式
c. 從 HTML 讀取出內容,並且完成字串的替換 --> jinja2 (模板語言)
3. Python 中 Web 框架的分類:
1. 按上面三個功能劃分:
1. 框架自帶 a,b,c --> Tornado
2. 框架自帶 b 和 c,使用第三方的 a --> Django
3. 框架自帶 b,使用第三方的 a 和 c --> Flask
2. 按另一個維度來劃分:
1. Django --> 大而全(你做一個網站能用到的它都有)
2. 其他 --> Flask 輕量級
引入 wsgiref 模組實現 socket 通訊
不知道你會不會覺得之前的程式中,socket 通訊特別麻煩,而且還都是一樣的套路,完完全全可以獨立出來做成一個模組,要用的時候再直接引進來用就可以了。
沒錯,有你這種想法的人還不在少數(吃鯨......),特別是一些大牛們,就 socket 通訊這一塊,做出了一些特別好用的模組,例如我們下麵要用的 wsgiref 模組。
-
""" -
根據URL中不同的路徑傳回不同的內容--函式進階版 -
傳回HTML頁面 -
讓網頁動態起來 -
wsgiref模組負責與瀏覽器收發訊息(socket通訊) -
""" -
-
import time -
from wsgiref.simple_server import make_server -
-
-
# 將傳回不同的內容部分封裝成函式 -
def yimi(url): -
with open("yimi.html", "r", encoding="utf8") as f: -
s = f.read() -
now = str(time.ctime()) -
s = s.replace("@@xx@@", now) -
return bytes(s, encoding="utf8") -
-
-
def xiaohei(url): -
with open("xiaohei.html", "r", encoding="utf8") as f: -
s = f.read() -
return bytes(s, encoding="utf8") -
-
-
# 定義一個url和實際要執行的函式的對應關係 -
list1 = [ -
("/yimi/", yimi), -
("/xiaohei/", xiaohei), -
] -
-
-
def run_server(environ, start_response): -
start_response('200 OK', [('Content-Type', 'text/html;charset=utf8'), ]) # 設定HTTP響應的狀態碼和頭資訊 -
url = environ['PATH_INFO'] # 取到使用者輸入的url -
func = None -
for i in list1: -
if i[0] == url: -
func = i[1] -
break -
if func: -
response = func(url) -
else: -
response = b"404 not found!
"
-
return [response, ] -
-
-
if __name__ == '__main__': -
httpd = make_server('127.0.0.1', 8090, run_server) -
print("我在8090等你哦...") -
httpd.serve_forever()
你會發現,使用了 wsgiref 模組之後,程式封裝更好了,程式碼邏輯也更加清晰了。


WSGI 協議
經過上面的 wsgiref 模組的示例,在使用通訊模組的方便之餘,你可能已經意識到一個問題,類似於 wsgiref 這樣的模組肯定不止一個,我們自己寫的 url 處理函式需要和這些模組進行通訊,那麼,我怎麼知道這些模組傳過來的資訊是什麼格式?如果各個模組傳過來的資訊結構都不一樣的話,那豈不是說我得根據每一個模組去定製它專門的 url 處理函式?這不科學,這中間肯定需要一個協議進行約束,這個協議,就叫 WSGI 協議。

作者:守護窗明守護愛
源自:
http://www.cnblogs.com/chuangming/p/9072251.html
