我是一名SRE工程師,我們負責管理與維護360商業廣告平臺,說起SRE工程師大家可能會想到谷歌公司,因為SRE畢竟是谷歌提出的概念。
作為SRE工程師我想說一下我們的自我修養。我們的主要工作是減少瑣事,不斷的擴大服務規模,同時我們還要保證整個系統的高可靠性和可維護性,不能隨著業務規模的不斷增大,招攬越來越多的人來維護業務是不合理的。
我們廣告透過360搜尋或者360手機端的應用進行展示,比如在360搜尋輸入“鮮花”會有廣告展示,每天有數百億次的投放與展示,手機端主要透過360的手機安全衛士,手機助手等等的一些應用進行廣告的投放與展示。

說一下為什麼要使用容器解決我們的問題,還有演講的主題為什麼不寫Why Docker?
說到容器大家第一時間會想到Docker,它實現了一個容器引擎(Docker engine)。除了Docker,在容器生態圈還有一些公司他們實現了自己的容器引擎,比如CoreOS的RKT,比如我們使用的Mesos的容器引擎(Mesos containerizer),這些引擎不依賴於Docker本身,可以解決穩定性和擴充套件性的問題。
我先不說我們為什麼用容器解決這些問題,說一下業務上我們有哪些痛點,並且這些問題可能大家都會碰到。
-
資料中心遷移,這個問題大家多數都會遇到,在遷移過程中要把之前的業務熟悉一遍,需要重新部署,測試還會遇到一些環境配置不一致的問題。
-
故障恢復,伺服器宕機之後,傳統業務都部署在物理伺服器上,這樣也需要重新部署,這樣會帶來很多麻煩。
-
作業系統不一致,現在我們很多不同的作業系統,比如CentOS 5、6、7都在用,遷移的時候很麻煩,還有一些系統內核的Bug需要去解決。
-
生產環境配置不一致,生產環境有一些伺服器工程師都可以登入,如果改了一些配置導致線上出現問題的情況也是可能發生的。
-
測試環境不一致,可能每個人申請一臺虛擬機器專門做測試,導致測試結果也不一致。
-
服務的擴充套件性較低,傳統業務擴容一般需要一臺中控機或者有一套部署環境,每一次都需要重新新增一批伺服器進行擴容。
-
伺服器資源利用率問題,使用物理機部署服務,每一天都有服務的高峰低谷,由於採用靜態資源劃分的方式,資源利用率非常低會給公司造成很多資源上的浪費。
下麵我來說一下我們為什麼要用Docker來解決我們的問題。
Docker有一個隱喻叫“集裝箱”。其實Docker的英文翻譯是“碼頭工人”,這個隱喻給使用者很多暗示,告訴大家快來使用Docker吧,使用Docker就像使用集裝箱一樣,能夠隨時隨地的,無拘無束的啟動你的應用。像Docker官方的口號一樣“build、ship、and Run Any APP Anywhere”,Docker為什麼可以解決我們遇到的這些業務痛點呢?因為集裝箱是有固定的標準,它的大小一致,這樣貨物在公路、鐵路、海洋運輸就不用考慮貨物的尺寸等問題了,並且依賴大型機械化進行轉運,等於是實現了一套標準的運輸體系,可以給整個世界帶來很大的商業潛力。
正如我上面說到的,Docker的實質化就是標準,Docker的標準化是怎麼實現的呢?
首先,Docker有自己標準化的檔案管理方式,它的標準化檔案方式就是有自己的Dockerfile,可以定義一系列的軟體系統版本。
第二點,Docker有對應用的統一操作方法,在物理環境不同的應用有不同的啟動方法,如果你用Docker啟動程式,可以透過docker run的方式來啟動。在服務遷移過程中只要使用docker run命令來啟動你的程式就可以了。
第三點,為了維護生產環境的一致性和配置變更的冪等性,Docker創造性的使用了類似Git管理程式碼的方式對環境映象進行管理。每次都需要docker pull下載映象,Docker container本身只有container layer這一層可寫,你每次重新部署的時候這一層是會被刪掉的,這樣可以保證Docker實際環境每次都是冪等的。
在服務容器化過程當中,我們可能會遇到哪些問題?當大家使用物理機的時候,為了SSH登陸伺服器,每臺伺服器都會開通SSH服務並且新增對應的賬號。如果你使用Docker服務還要開通SSH服務的22埠,你需要考慮一下你的服務是否真的需要登入到容器中,或者你容器化的方式是否正確或者它是否適合你的業務。還有一些人這樣使用Docker:在容器中開放rsync服務埠,甚至還有在Docker container裡面部署puppet agent同步工具,這樣做我覺得是完全沒有必要的。我們都是不支援SSH或者類似的服務連線到Docker內部的。
如果你不讓我登入到物理機上,不讓我連到Docker內部,我怎麼看我的日誌呢?
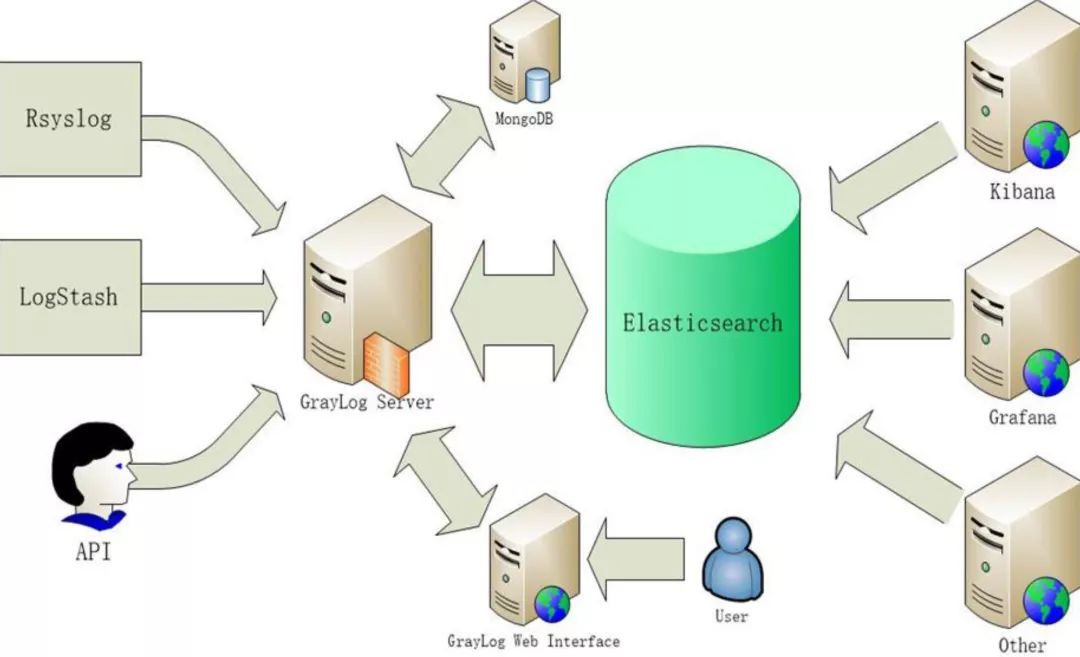
我們有一套日誌系統,後端對接的服務是Elasticsearch,會使用Docker的syslog模組透過UDP的方式寫入Graylog裡,Graylog或者Grafana都可以進行展示、查詢,這樣我們就可以及時的發現線上的問題。
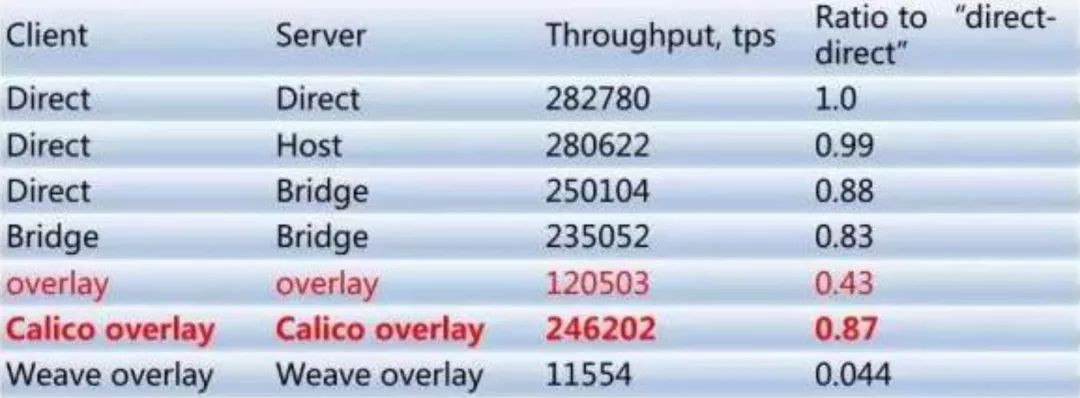
使用了Docker,大家可能會考慮,它的網路效能會怎麼樣,我們其實也做過一些調研。我們主要用的是Hostonly和Bridge這兩種樣式,如果用Hostonly基本和直接在物理伺服器上執行程式的效能是差不多的,現在我們也有團隊專門做Calico服務方面的研究,比如你有一些爬蟲服務,可能希望有一些獨立的外網IP,可以考慮使用Calico為一個container單獨分配外網IP。
或者有網路隔離的需求的話,也可以使用Calico服務。由於我們主要針對是私有雲,直接用hostonly樣式多一些。
關於Docker倉庫,大家可能會問服務容器化之後,主要用什麼倉庫儲存映象呢?哪種映象倉庫比較好?之前我們搭建過Docker官方的倉庫,只有單節點不是高可用的,資料可靠性也不是非常好,我們是用的無認證樣式。
現在我們使用了Harbor,用這個系統做了二次開發,後端儲存用的S3儲存系統,資料可靠性是非常高的,多機房之間可以進行資料同步,支援使用者認證,大家根據自己的使用者密碼進行登入上傳映象等操作。之後我們還會做一個Docker倉庫的CDN化,多機房直接訪問CDN服務下載映象。
大家使用Docker可能會考慮資料怎麼寫到本地,我們使用Mesos+Docker之後,是不是所有服務都要需要無狀態的呢?我們推薦無狀態服務執行在Mesos+Docker之上。但是如果你有把日誌落到本地的需求,我們現在也是可以支援的。
我列出的這些產品,比如CephFS、MySQL、Kafka、HDFS、Aerospike、Redis都是資料持久化的一種方式,比如流式資料一般用Kafka多一些,資料直接透過Kafka消費出來,透過一些計算模型後再重新寫入Kafka,或者如果想資料落到本地的需求直接在Container中掛載CephFS也是可以的。
關於服務的註冊和發現,大家可能會有一些問題。比如我用了Mesos+Docker之後,我們的一些服務是在mesos-slave節點之間飄逸的,有可能因為一臺物理機宕機了,你的服務會在另外一臺mesos-slave節點上啟動,我怎麼知道我的服務啟動到具體哪臺IP或者具體哪臺機器上呢?
我們服務發現主要用的是Mesos-DNS還有Marathon,底層資料依賴於ZooKeeper。還有一些公司可能用etcd或者Consul,我們也有在用不過比較少。
關於使用了Docker,服務如何進行排程?還有Docker服務如果對於本地資料有依賴的話需要如何載入?希望大家可以帶著問題思考一下,一會兒我會詳細說明。
當前遇到的一個背景就是在當前網際網路環境下,越來越多的分散式計算系統產生。
如果說維護一個大型業務團隊需要部署的框架或者分散式系統非常多,但是市面上又沒有一種系統能夠把所有的應用框架都部署到一個集群裡,這樣就會導致我之前說的比如資源利用率會很低,可維護性很低。因為不同的叢集有不同的配置,所以我們就想把這些多個應用布到一個大型的資源池裡,這樣可以更好的共享硬體資源。因為我們的服務都是支援動態擴縮容的,這樣也可以簡化一些部署上的邏輯,並且最大化的利用資源,最終實現服務可排程,資料可以共享。
因為之前大家用物理伺服器的時候,是靜態資源劃分的方式,這種方式資源浪費得比較多。因為服務每天都有高峰和低谷時段,如果你用Mesos的話,使用了動態服務擴縮容,比如白天廣告展示的量會非常大,最高的時候每秒已經超過一百萬,但是在晚上訪問量非常低,你就可以把這批機器資源釋放出來,供一些離線業務執行,比如Hadoop。可以達到最大化的資源利用率。
Mesos本身支援對所有資源打標簽,大家可以打固定的標簽。這樣在提交資源的時候,可以根據你想要的資源提出申請。比如你想要一個GPU的資源,比如你要1核的我就會分配給你一核的,像乘坐飛機一樣,你想坐頭等艙只要有資源就可以分配給你,Mesos也是這樣,我們支援埠、CPU、記憶體、硬碟等等的劃分。
因為它本身的設計原理是兩極排程框架,這樣帶來的好處是它非常的簡單。因為Mesos本身只負責資源排程,把任務排程交給了執行在它之上的具體框架進行排程。所以如果你要橫向擴充套件Mesos的話,非常方便。
因為Mesos支援在Mesos API之上定義各種各樣的framework,大家可以自由新增framework,我們主要用的Marathon、Flink等官方與自定義framework,具體使用哪種框架,大家可以根據需要去設計。
Mesos的標的,其實主要就是給我們帶來資源的高利用率,支援多種多樣的自定義框架,包括當前支援的還有以後新產生的分散式計算框架等,都可以建立在Mesos之上。
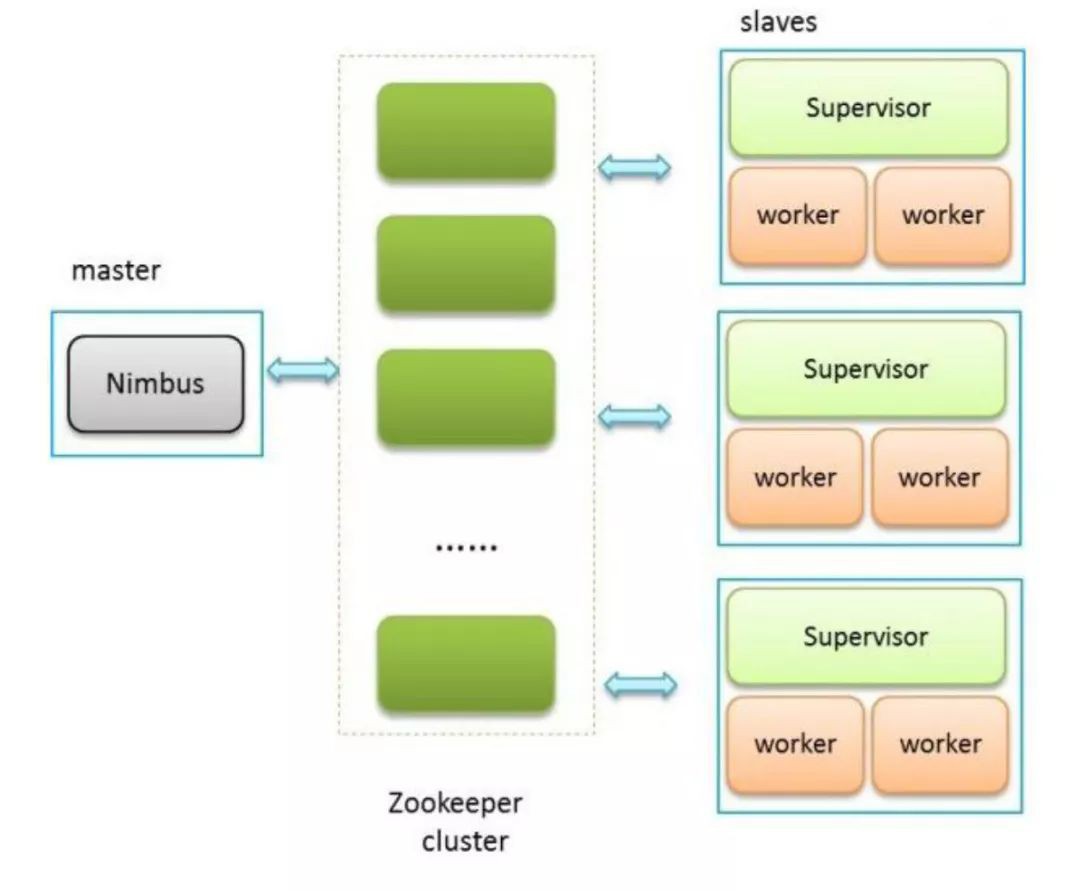
Mesos的主要組成是由ZooKeeper實現master的高可用,還可以保證資料的一致性,儲存所有的Mesos sleve節點和資訊。Mesos master主要用於接收agent上報給Mesos master的資源,Mesos master會分配offer給具體給它之上執行的framework。
Framework是基於Mesos API定義的排程器,會根據排程需求分配具體的offer。
最底層是Mesos agent,用來接受和執行Mesos master發給它的命令,透過Mesos agent之上的executor啟動task。
Mesos是用的兩萬行的C++程式碼編寫而成,故障恢復使用的是ZooKeeper,框架都是可拓展的、可以自定義的,並且是模組化的。是Apache頂級的孵化專案,同時還是開源的,專案成立於2009年。
Mesos給我們帶來的是更高的資源利用率與可靠性。
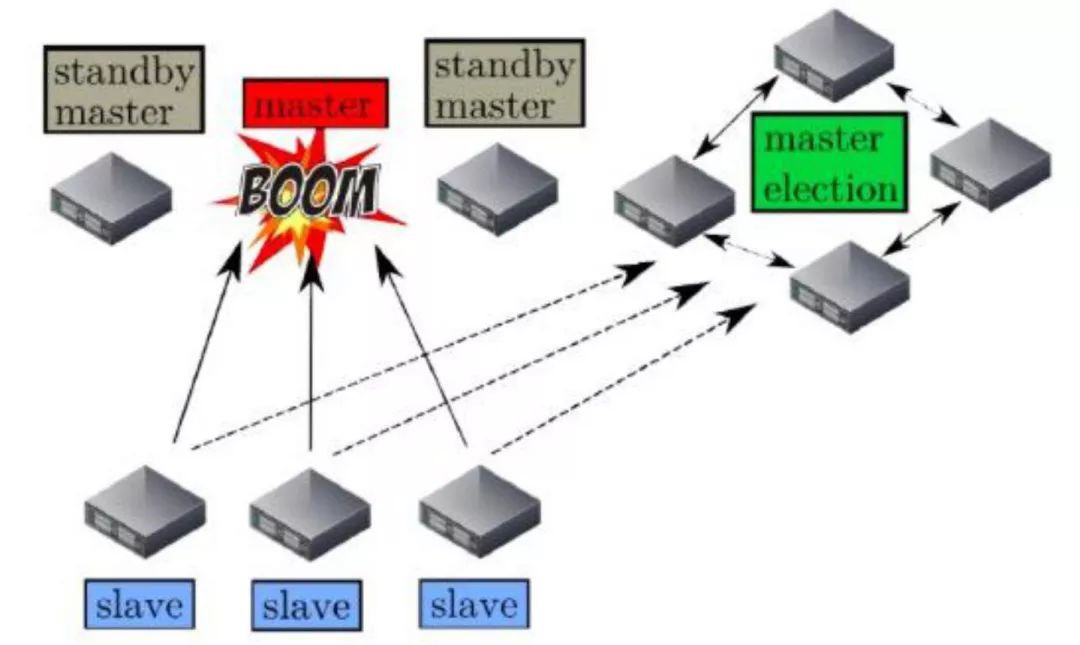
接下來說一下Mesos master的故障恢復機制。
因為Mesos master只有一個軟體狀態,只會列出它之上的framework以及mesos-slave的資訊,在Mesos master需要進行切換的時候,透過ZooKeeper進行leader的重新選取,選取好新的leader後,只需要所有的framework和mesos-slave節點重新註冊到新的Mesos master之上,時間就10秒鐘左右。如有你有上萬臺機器,可能會同時連Mesos master會不會造成大量的連結導致master服務不可用,官方有這樣的設定可以設定連結的比例來進行控制。
-
執行長任務。從應用框架字面的意思,任務就像跑長跑一樣,這個框架其實就是執行長任務(long running job)的。
-
服務發現。Marathon還可以實現服務發現,有比較好的API介面,比如我有一個APP id對應具體機器的IP是什麼。
-
健康檢測&事件通知機制。Marathon支援對你所啟動的任務進行健康檢測,比如埠或者你自定義命令都可以,有事件通知機制,正因為有了事件通知機制才可以在馬拉松之上建立一些實時的服務發現,知道哪些服務宕掉了,在哪些新節點啟動了,可以保證我們的實時發現服務,重新指向新的伺服器。
-
WebUI。Marathon有自己的Web UI,可以透過介面直接操作,非常方便。
-
限定條件。你可以設定一大堆的限定條件,比如我之前說的像你選飛機的艙位一樣,你設定了網絡卡必須是萬兆的,Marathon會根據你設定的限定條件,幫你選擇對應資源。
-
Labels。Labels標簽也是我們常用的,隨著資源利用率越來越大,可能有各種應用,大家可以加上各種的標簽,方便的查詢。
-
資料持久化。資料持久化也是支援的,可以支援掛載本地捲。
-
服務的預熱。這個功能用得不是特別多,比如你在服務啟動的時候會需要啟動時間,這個時間健康檢測是失敗的,你可能需要設定一個預熱時間,保證服務啟動之後正常的健康檢測才生效。
-
優雅退出。優雅退出這個問題,大家可能都會遇到,比如像C++不涉及記憶體自動回收可能需要程式上設計優雅退出的問題,你可以透過Marathon設定一個退出時間,保證你的服務正常退出之後,才把以前的服務都退掉,新的服務啟動。
-
支援自定義的containerizer和GPU資源的排程。
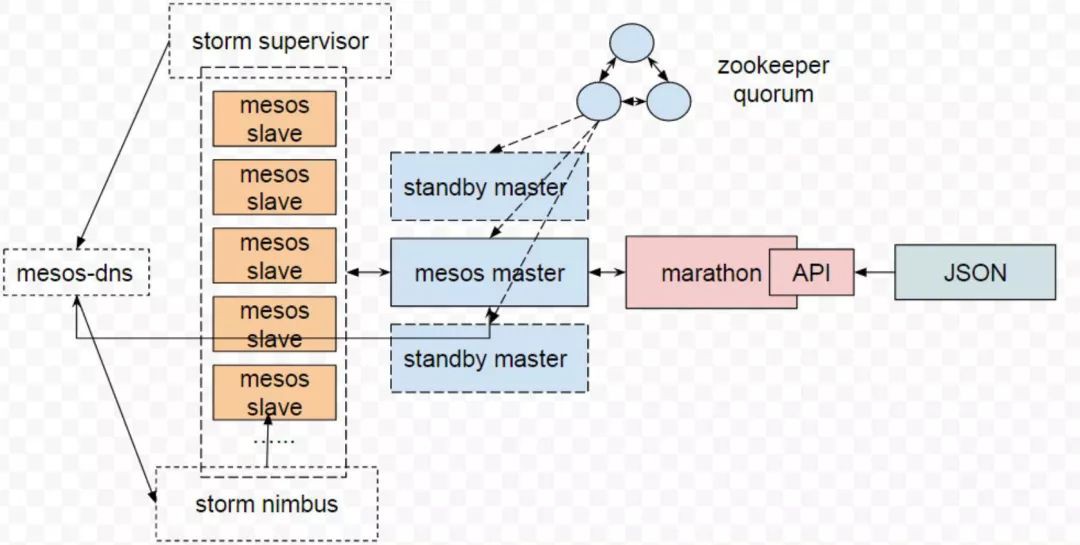
Marathon-LB是我們用的一個實時發現的服務,Marathon-LB是基於Haproxy和Marathon eventbus機制設計的。其實除了Marathon-LB還有一些其他的服務實時發現,但是都是基於Marathon的事件通知機制設計的。因為Marathon有事件匯流排的實時更新,可以實時的改變服務後端的IP。如果有宕機或者有服務自動擴縮容的話,Marathon-LB可以實時改變Haproxy的配置,Marathon-LB主要是透過第四層IP加埠的方式進行服務代理,Marathon-LB支援TCP或者HTTP的代理方式。
我們還使用了Mesos官方的Mesos-DNS服務,用於一些對實時性要求不高的服務,比如我們把STORM容器化以後Nimbus和Supervisor之間的通訊可能就不是那麼頻繁,如果有Nimbus宕機的情況,只需要透過Mesos-DNS就可以重新發現AppID對應的新的Nimbus IP。你可以使用Mesos-DNS發現AppID對應的所有後端節點的IP,可以保證你的服務節點隨時都可以訪問到你想訪問到的IP。Mesos-DNS有一定的延遲性,我們測試大概有十幾秒。
我說一下在我們做技術選型的時候,我們也做過Mesos和YARN方面的調研。
Mesos主要是能排程各種樣的資源,有CPU、記憶體、埠、硬碟;YARN主要是CPU和記憶體。
Mesos本身只做資源的排程,不負責具體任務的排程,把任務排程交給framework排程。
YARN全都是YARN本身進行資源排程,一個程式提交給它一個任務都由YARN來決定是否接受或者拒絕這個資源,而Mesos卻不同。
Mesos因為是對物理資源進行管理與排程的,YARN主要基於Hadoop來做。
根據需要,我們最後還是選擇了Mesos來作我們的分佈資源管理框架。
說起Mesos可能很多同學覺得使用了Marathon提供了容器任務的管理能力,可能就需要跟Kubernetes系統進行比較一下。
本身來講,Mesos和Kubernetes是兩個東西,Mesos是一個分散式的資源管理框架,被稱為分散式系統的核心。假如你有很多物理資源,你想把它整合成一個邏輯資源層面的物理資源池,那麼你用Mesos是最合適不過的了。
Mesos解決問題的核心是如何把資源整合成一個大型的物理資源池,它上面執行什麼,怎麼跑它並不關註。
Kubernetes主要是一個自動化的容器操作平臺,操作主要包括部署、排程還有節點叢集間的擴容等等。
Kubernetes解決問題的核心主要是圍繞容器來做的,這兩個系統本身沒有可比性。因為Mesos支援很多framework,比如Marathon可以實現容器的排程,所以大家就會把這兩個平臺進行比較。
如果你想搭建這樣一個容器管理平臺或者排程平臺,從我個人來講第一點從任務上來講,Marathon只支援長任務型的,Kubernetes支援的比較廣,比如支援長時間任務(long running job),節點後臺支撐型(node-daemon)等等各種各樣的任務。
說一下穩定性方面,Kubernetes是谷歌官方推出的,它的更新比較頻繁,更新頻繁可能帶來的就不是特別穩定,大家可能理解我可以多做一些線下測試,但是事實確實是這樣的,Kubernetes更新非常頻繁。Mesos一般每半年更新一次,一年釋出兩個版本,會經過充分測試。Mesos產品設計因為是開源的,是Apache基金會下麵的頂級專案,會在社群跟大家進行投票與溝通,決定未來我們的產品怎麼做,我們會增加哪些功能。
第三種主要是從功能上來講,Kubernetes是由谷歌做的,所以它的考慮會非常全面,它的生態非常全面,你想要的功能基本都有,包括網路Kubernetes其實也是有的,其實Kubernetes本身的網路做得不是特別好,很多用Kubernetes都是用Calico實現的。Mesos系統的設計思路則定義了任務排程和功能上整體依賴於排程器的設計,所以可以把Mesos看成一個大樂高底層的基礎板。
對於這兩個框架,選擇哪一個都沒有對與錯,只有適合與否,選擇一個適合你們的工具才是最重要的。
我說一下Mesos/Container在360的一些應用。
我們從2015年開始,就對分散式的排程系統或者容器排程平臺進行了調研,最後選擇使用Mesos,因為我們想構建一個大型的物理資源池。在2016年業務正式上線,包括之後說的一些服務的容器化,2016年我們也使用了Chronos,可以執行一些物理機上執行的crontab任務,長時間支援服務線上執行。2017年我們已經實現了兩個機房各部署了一個大型的資源池,節點達到了單叢集最大1000個以上,任務達到5000個以上,10個以上的自定義framework。
部署,現在部署可能你只需要在Marathon上改變你的映象(image)地址,或者只需要把instance數改大就可以擴容。
故障恢復,如果有一臺mesos-slave宕掉了,會自動在其他的節點上啟動。
服務降級,關於服務降級,我們的資源池伺服器是有限的,1000臺伺服器如果資源快用滿了,有些業務就需要做服務降級,不是所有業務都有動態擴縮容。我們主要處理廣告業務,廣告業務實時日誌流比較多,在資源不夠的時候,會讓某些業務降級。平時每秒處理20萬條,降級時讓它每秒處理10萬條或者5萬條,有一定資料延遲也沒有關係,因為資料不會丟只會慢慢處理完。
服務發現,關於服務發現,現在有了Mesos-DNS和Marathon-LB我們可以做到實時的服務發現,因為是動態資源劃分,我們的任務就可能實時變化。
上圖是原來透過物理級部署的,所有的Supervisor節點都是一臺臺物理機還要單獨部署一個Nimbus,如果Nimbus節點宕掉非常麻煩,比如有些同學說我可能會用Keepalived做高可用,這確實是一種方案,但是如果你的叢集需要頻繁的擴容或者縮容就會非常麻煩,你要是不對資源進行動態管理的話,勢必帶來的就是資源的浪費,因為不可能一天24小時都滿負荷執行。
把服務容器化之後,所有的Supervisor都執行在container(mesos-slave)中,Supervisor節點會透過Mesos-DNS發現Nimbus(master)的IP。現在叢集資源都是動態利用的。
圖片服務主要用的PHP 7來做的,我們也會面臨像阿裡一樣在雙十一的時候,因為廣告展示與投放量非常大,每秒達到上百萬次,因為給使用者進行展示與投放的圖片會根據使用者的習慣去動態的縮放與拼接。如果我放著很多機器專門用來做圖片服務,可能也可以達到你的需求,但是在空閑時間段比如夜裡資源浪費得非常多,對資源的利用率不是非常好。
我們就制定了這樣一套方案,首先把PHP服務容器化,之後我們根據亞馬遜AWS的策略,做了自己的方案,跑一個long running job,根據Marathon的API獲取你的圖片服務具體是哪臺機器,由於所有機器上的監控都用了二次開發,透過API介面能獲取負載、CPU,記憶體等等資訊。當圖片伺服器的負載上升了肯定是壓力最大的時候,這樣我們只需要設定一個閾值。
比如系統負載大於10超過10次,就進行一次擴容,擴容的倍數是1.5倍,原來我有10臺機器,現在要擴容到15臺。大家可能會問你這個最大能擴到多少?我一定要設定一個最大值不能無限的擴。比如我們設定一個36,最大擴到36臺,在5分鐘內可能判斷10次,如果這個負載水平一直很高,就不進行縮容。
我肯定還會設定一個最低值,比如最低值是6臺,可能到了夜裡直接減為6臺,每次都需要透過Marathon的API實時發現後端所有機器計算出一個平均值。服務的監控,我們對每臺Mesos slave都有監控,具體的container我們做了非同步,透過非同步把日誌寫到Graylog中,監控日誌傳輸透過UDP協議。如果發生網路中斷的情況也不會有太大影響,因為UDP是可丟的不可靠的。
我們還有其他服務的一些容器化,有Web service相關的,Aerospike服務,透過組播實現叢集之間的通訊部署起來比較方便,Marathon-LB也是完全的Docker化的,畢竟是代理層像LVS一樣,可能會有服務瓶頸。Kafka MirrorMaker我們用來進行多機房之間的資料傳輸,原來直接部署在物理機上,這樣雖然不會有太大問題,如果宕掉之後資料不能在多個叢集當中進行同步,對實時性不能要求那麼高。如果做了容器化之後是可排程的,都是可高可用的,我們會保證服務的可靠性。Redis也有做容器化,支援資料的落地和持久化,因為我們有CephFS還有更多的一些無狀態的服務也執行在Mesos之上。
最後我要說一下我們的服務CI/CD是怎麼做的,CI/CD主要是透過GitLab runner。我們會定義一個Gitlab-CI,可以直接把你提交的程式碼進行Docker build,把映象自動提交到對應的倉庫,透過API修改Marathon上面對應的地址,最後實現上線自動化。
未來我們想做的,因為CephFS的量不是很大,CephFS之後想上一些寫入量比較大的業務,看看效果如何。我們不是做公有雲的對於Calico的需求不是那麼急切,之前一直沒有上這個服務。之後我們可能會做一些Calico相關的,比如一些爬蟲的應用,如果用公司的Nat代理的話,可能遇到一些IP被封,導致整個代理IP都不能訪問對應的網站就有一些問題了。
還有一些實時的機器學習,現在機器學習主要都基於離線業務來做,實時學習比較少,Marathon和Mesos本身是支援的。
本次培訓內容包括:Docker基礎、容器技術、Docker映象、資料共享與持久化、Docker三駕馬車、Docker實踐、Kubernetes基礎、Pod基礎與進階、常用物件操作、服務發現、Helm、Kubernetes核心元件原理分析、Kubernetes服務質量保證、排程詳解與應用場景、網路、基於Kubernetes的CI/CD、基於Kubernetes的配置管理等,點選瞭解具體培訓內容。
長按二維碼向我轉賬

受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。