

在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @jsh0123。本文嘗試對指代消解的一種神經網路 Mention Rank 模型的啟髮式損失函式中的超引數利用強化學習方式進行最佳化,提出一種獎勵衡量機制,跟其他方式比效果突出。
關於作者:薑松浩,中國科學院計算技術研究所碩士生,研究方向為機器學習和資料挖掘。
■ 論文 | Deep Reinforcement Learning for Mention-Ranking Coreference Models
■ 連結 | http://www.paperweekly.site/papers/1047
■ 原始碼 | https://github.com/clarkkev/deep-coref
介紹
本文出自斯坦福 NLP 組,發表在 EMNLP 2016,其將深度強化學習應用於指代消解領域是一大創新,相較於其他方法有很好的效果提升。
指代消解是自然語言處理的一大研究領域,常見的指代消解演演算法多數模型採用啟髮式損失函式,不同消解任務為達到良好的使用效果需要對調整損失函式超引數。
常見的指代消解演演算法有 Mention Pair、Mention Rank、Entity Mention 等等,本文將深度強化學習應用於 Mention Rank 實現消解技術的通用性,解決啟髮式損失函式的超參微調問題。
模型介紹
論文作者將其發表於 ACL 2016 的 Neural Mention-ranking 模型 [1] 進行強化學習的改進。
模型結構
如下圖所示,Neural Mention-ranking 模型結構主體部分為多層的前反饋神經網路,分為三個部分:首先是輸入層將指代詞(mention)特徵、候選前指詞(Candidate Antecedent)即指代詞出現前的詞特徵、指導詞所在句子特徵以及其他特徵例如距離特徵、連線關係特徵等等做向量拼接(concate)處理作為模型的輸入 h0。
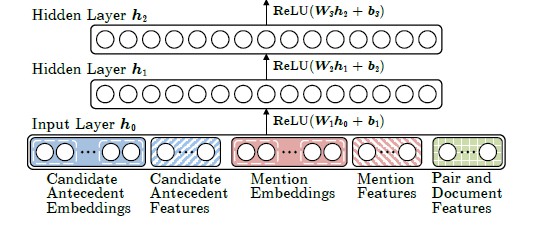
特徵的獲取過程不是本論文的重點,這裡不詳細闡述,對特徵如何獲取感興趣可以參考 [1]。
隱藏層採用 Relu 作為啟用函式,其中隱藏層共 3 層,其公式定義如下:

分數獲取層,其採用基本的線性相乘法,公式定義如下:
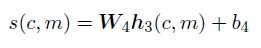
啟髮式損失函式
Neural Mention-ranking 模型結構採用一種啟髮式 Max-Margin 損失函式,Max-Margin 即 Hinge Loss 的一種變種。 首先,先看鬆弛引數 △h 的定義。
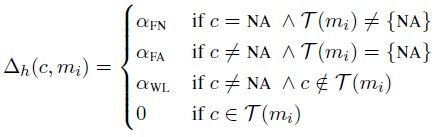
其中 C(mi) 表示預測的候選前指詞庫,T(mi) 表示真實的前指詞庫,c∈C(mi),NA 表示為空,FN、FA、WL 依次表示“不為空”、“錯誤的前指”、“錯誤連線”。 損失函式定義如下,該函式目的是讓真實的前指詞“分數”更高,錯分情況“分數”隨著訓練不斷降低。

其中 ti 表示預測候選詞中真實前指詞的最高“分”(Score),定義如下。

引數 ɑ 的定義採用人工微調的方式,不斷嘗試,最終確定最優值。
強化學習對損失函式的改進
論文采用兩種強化學習方式改進,一種對超引數的改進,採用強化學習的獎勵機制,另一種採用經典的增強策略梯度演演算法。
論文中將 Neural Mention-ranking 模型當做代理(agent),而每個行為 ai 表示第 i 個指代詞的其中一個前指詞。Ai 表示第 i 步中所有的候選行為集合即所有第 i 個指代詞的所有候選詞集合。獎勵函式 R(a1:T) 表示第 1 個行動到最後行動的獎勵,用 B-cubed 函式 [2] 表示。
1. 獎勵衡量機制
這種方式將上述啟髮式損失函式的鬆弛引數 △ 進行改進,由於沒個行為都是沒有關聯性、獨立的,因此可以透過嘗試不同的行為判斷每一步獎勵差異。因此鬆弛引數變化如下所示。

這種機制的訓練方式和啟髮式損失函式一致。
2. 經典強化學習方式
除上述獎勵衡量機制外,採用經典的增強策略梯度演演算法,每個行為 a=(c,m) 的機率定義如下。

損失函式定義如下:

為使獲得獎勵值最大,採用梯度上升法進行引數更新,由於每一次行為選擇隨著句子的增長指數級增長,因此梯度值計算困難。論文采用一種梯度估值,定義如下所示。

模型實驗效果
透過對 CoNLL2012 的英文和中文的指代資料實驗,得到測試結果如下圖所示,獎勵衡量機制效果明顯,表現最佳。

論文評價
這篇論文發表於 2016 年的 EMNLP,嘗試對指代消解的一種神經網路 Mention Rank 模型的啟髮式損失函式中的超引數利用強化學習方式進行最佳化,提出一種獎勵衡量機制,跟其他方式比效果突出。
這種基於強化學習的獎勵衡量機制的超引數調節方式會對很多研究工作產生啟發,特別是對超參設定採用嘗試性遍歷方式的研究工作。可惜論文發表到現在兩年時間,在指代消解中利用強化學習的方式沒有更好的新的嘗試。
相關連結
[1]Kevin Clark and Christopher D. Manning. 2016. Improving coreference resolution by learning entity-level distributed representations. In Association for Computational Linguistics (ACL).
[2]Amit Bagga and Breck Baldwin.1998. Algorithms for scoring coreference chains. In The First International Conference on Language Resources and Evaluation Workshop on Linguistics Coreference, pages 563–566.
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

點選標題檢視更多論文解讀:

▲ 戳我檢視比賽詳情
 #作 者 招 募#
#作 者 招 募#
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 加入社群刷論文