
作者丨李軍毅
學校 | 中國人民大學本科生
研究方向丨機器學習、自然語言處理
前言
本文將介紹 AAAI 2018 中的五篇關於應答生成方面的論文,希望對大家有所啟發。


寫作動機
作者認為,雖然之前的論文對多輪對話的層次結構進行了建模,知道應答的生成應該考慮到背景關係(context)資訊,但是卻忽略了一個重要的事實,就是背景關係中的句子(utterance)和單詞(word)對應答有著不同分量的影響。
所以,作者提出了一種層次化的註意力機制來對多輪對話中不同層面的影響進行刻畫,分別是句子級註意力機制(utterance level attention)和單詞級註意力機制(word level attention)。
具體模型

問題定義:資料集 ,
, 表示背景關係(context),每一個
表示背景關係(context),每一個 表示一個句子,
表示一個句子, ,
,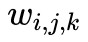 表示
表示![]() 第 k 個單詞,
第 k 個單詞, 表示應答。
表示應答。
Word Level Encoder
對於一個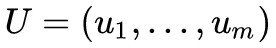 ,論文使用雙向 GRU 將每個 ui 編碼為
,論文使用雙向 GRU 將每個 ui 編碼為 ,每個
,每個 ,
, 和
和 分別表示 GRU 前向和後向的隱藏狀態。
分別表示 GRU 前向和後向的隱藏狀態。
Word Level Attention
 於表示 Decoder 第 t 步時,關於 ui 的 context vector。至於
於表示 Decoder 第 t 步時,關於 ui 的 context vector。至於 如何計算,後面介紹。
如何計算,後面介紹。
Utterance Level Encoder
 將作為 GRU 的輸入,計算
將作為 GRU 的輸入,計算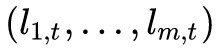 。
。
Utterance Level Attention
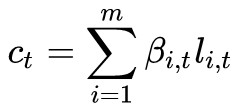 表示 Decoder 在第 t 步時,關於整個 U 的 context vector。至於
表示 Decoder 在第 t 步時,關於整個 U 的 context vector。至於 如何計算,後面介紹。
如何計算,後面介紹。
與傳統的 attention 機制不同,word level attention 不僅依賴 decoder,還依賴 utterance level encoder。所以:
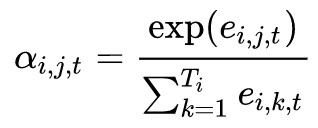
 表示 Decoder 前一個狀態,
表示 Decoder 前一個狀態,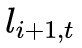 表示 utterance level encoder 前一個狀態,
表示 utterance level encoder 前一個狀態,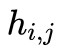 表示 word level encoder 當前狀態。同理:
表示 word level encoder 當前狀態。同理:



寫作動機
作者認為,在基於檢索的應答生成場景中,加入社會常識可以改善檢索結果的質量。
具體模型

上圖表示一個常識庫。它是一個語意網路,concept 是它的節點,relation 是它的邊,三元組 <concept1,relation,concept2> 稱為一個 assertion 。
問題定義
x 是一個message(context), [y1,y2,…,yK]∈Y 是一個應答候選集。
基於檢索的應答生成系統就是要選出最合適的 ,其中 f(x,y) 是衡量 x 和 y 之間的“相容性”的函式。
,其中 f(x,y) 是衡量 x 和 y 之間的“相容性”的函式。

那麼,如何將常識庫融入我們的問題定義中呢?
以上圖為例。首先,事先定義好一個 Assertion={c:
然後,論文裡又定義一個 Ax ,表示所有與 message(context)x 有關的 assertion 三元組。
這個 Ax 的建立規則是:對 message 文字 取 n-gram(所有uni-gram,bi-gram,…,n-gram)短語,然後從 Assertion 詞典選取那些與 n-gram 短語匹配的 key 所對應的 value,加入到 Ax 中。
至此,我們就得到了所有與 message 有關的常識。

Dual-LSTM Encoder
上圖中下麵的方框。利用 LSTM 結構對 message x 和 response y 進行編碼,得到![]() 和
和![]() 向量,
向量,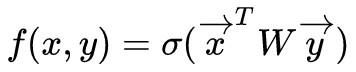 計算兩者之間的“相容性”。
計算兩者之間的“相容性”。
Tri-LSTM Encoder
上圖中上面的方框。因為 c1 和 c2 都有可能是幾個單詞透過下劃線連在一起的concept,所以我們將 c1 拆成 [c11,c12,c13,…] , c2 拆成 [c21,c22,c23,…] ,至於為什麼不拆 relation?因為 concept 是由多個常見詞連線起來的單詞,如果將這個合成詞直接作為詞典中的單詞,那麼詞典將會很大,而 relation 則沒有幾種。
最終,三元組  向量,然後,我們取 response 與所有常識“相容性”最大的值
向量,然後,我們取 response 與所有常識“相容性”最大的值 。
。
最後,將兩個 Encoder 的“相容性”值加起來,最終選擇總和最大的 response。


寫作動機
作者認為,以前的生成模型在生成單詞時,模型需要遍歷整個詞典。如果詞典非常大,那麼每次遍歷都非常耗時。所以,作者提出,每次生成單詞時,都可以根據輸入的情況靈活地選擇需要遍歷的詞典的大小以及它裡面的詞,這樣將可以節省大量時間。
具體模型
問題定義
資料集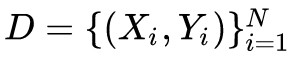 , Xi 表示 message, Yi 表示 response,生成 Ti 的標的詞典為
, Xi 表示 message, Yi 表示 response,生成 Ti 的標的詞典為 , |V| 表示詞典的大小,
, |V| 表示詞典的大小,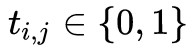 ,0 表示單詞不在詞典中,1 表示單詞在詞典中。
,0 表示單詞不在詞典中,1 表示單詞在詞典中。
Ti 是從多元伯努利分佈 中隨機取樣得到,
中隨機取樣得到, 。
。

那麼又是怎麼得到呢?
如上圖,在詞典 V 中,單詞可以分為兩類:function words 和 content words。
其中,function words 出現 10 次以上,除了名詞、動詞、形容詞、副詞,它們保證了 response 的語法正確性和流暢性,在每個 response 中都可能出現,所以,這些單詞的 , I(c) 是這些單詞的索引;content words 則是詞典中其他的詞,它們的
, I(c) 是這些單詞的索引;content words 則是詞典中其他的詞,它們的 。
。
最後,根據得到的多元伯努利分佈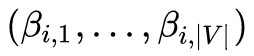 隨機取樣得到 Ti ,進而得到標的詞典。得到詞典後,剩下的過程則和以前傳統的過程類似了。
隨機取樣得到 Ti ,進而得到標的詞典。得到詞典後,剩下的過程則和以前傳統的過程類似了。


寫作動機
這篇論文解決的問題是,基於檢索的應答生成場景下如何從候選應答集選擇合適應答的難題。論文使用的方法是多臂老虎機模型。
多臂老虎機模型
一個賭徒,要去搖老虎機,走進賭場一看,一排老虎機,外表一模一樣,但是每個老虎機吐錢的機率不一樣,他不知道每個老虎機吐錢的機率分佈是什麼,那麼想最大化收益該怎麼辦?這就是多臂賭博機問題(Multi-armed bandit problem, K-armed bandit problem, MAB)。
如何解決呢?論文中使用的是湯普森抽樣方法。
假設每個臂產生收益的機率為 p,我們不斷地試驗,去估計出一個置信度較高的*機率p的機率分佈*就能近似解決這個問題了。
怎麼估計機率 p 的機率分佈呢? 假設機率 p 的機率分佈符合 beta (wins, lose) 分佈,它有兩個引數:wins,lose。
每個臂都維護一個 beta 分佈的引數。每次試驗後,選中一個臂,搖一下,有收益則該臂的 wins 增加 1,否則該臂的 lose 增加 1。
每次選擇臂的方式是:用每個臂現有的 beta 分佈產生一個隨機數 b,選擇所有臂產生的隨機數中最大的那個臂去搖。
具體模型

如上圖,左邊是 context,使用雙向 LSTM 編碼, ci 表示 context 向量,等於所有單詞向量![]() 的平均和。右邊是 response,也使用雙向 LSTM 編碼, uj 表示 response 向量,等於所有單詞向量
的平均和。右邊是 response,也使用雙向 LSTM 編碼, uj 表示 response 向量,等於所有單詞向量![]() 的平均和。如果是傳統的離線學習過程,那麼訓練過程應該為:
的平均和。如果是傳統的離線學習過程,那麼訓練過程應該為:
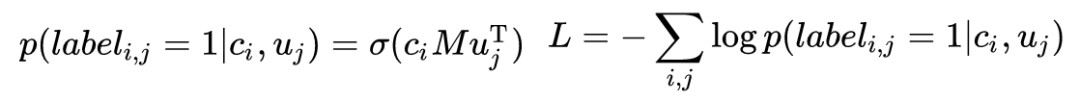
對損失做反向傳播即可。
但本文解決的是線上學習場景,模型隨機選擇一個 context,然後檢索到一個 response,使用者對這個選擇做出打分,正確則 reward=1,錯誤則 reward=0。然後,作者企圖利用線性邏輯回歸湯普森取樣對 reward 進行擬合, 。
。


寫作動機
作者覺得,生成 response 時應該生成多種 style 的 response,所以,作者提出了一種 Elastic Responding Machine (ERM) 模型,生成多種型別的 response。
具體模型
-
Encoder-Decoder
-
Encoder-Diverter-Decoder

這個模型來自 Zhou et al. 2017 的 Mechanism-Aware Neural Machine for Dialogue Response Generation。 表示 M 個 mechanism 的集合,mechanism 可以理解為 style。
表示 M 個 mechanism 的集合,mechanism 可以理解為 style。
Diverter 的作用是選出最適合 context c 的 mechanism,透過公式:

選擇評分最高的 mechanism,最終生成 response y 的機率為:

-
Encoder-Diverter-Filter-Decoder

本文作者在前文的基礎上,又加入了 Filter 模組,作者的目的是從所有 mechanism 集合中選出一個子集 Sx ,包含足夠多的 mechanism,能夠生成多種 style 的 response。
這個子集 Sx 需要滿足兩個條件:1)包含足夠多的 mechanism;2)子集的 mechanism 沒有太高的重覆性,沒有冗餘。選中了子集 Sx 後,生成 response y 的機率為:
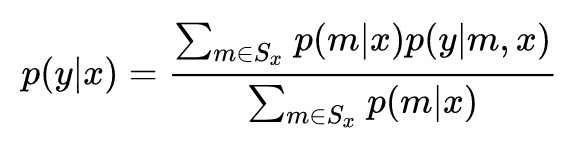
那麼,怎麼選擇子集 Sx 呢?論文使用的是強化學習的方法。
Action:at 表示停止動作, ac 表示繼續動作;
State: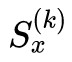 表示子集中包含 top k 個 mechanism 的狀態;
表示子集中包含 top k 個 mechanism 的狀態;
Policy: ,
, ,m0 表示停止的 mechanism;
,m0 表示停止的 mechanism;
Reward:作者認為,如果子集沒有達到要求的 K 個 mechanism 的規模,則沒有獎勵。
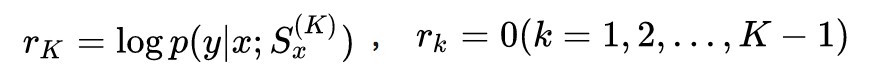
選出包含 K 個 mechanism 之後,依次將 c 和 mi (mi∈Sx) 連線在一起輸入到 decoder 中生成各自 mechanism 對應的 response。下麵是具體的演演算法流程:


點選以下標題檢視其他文章:

▲ 戳我檢視比賽詳情
 #作 者 招 募#
#作 者 招 募#
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 進入作者知乎專欄
