來源: tuohai666
http://www.cnblogs.com/tuohai666/p/8853601.html

介紹
大家好!回顧上一期,我們在介紹了爬蟲的基本概念之後,就利用各種工具橫衝直撞的完成了一個小爬蟲,目的就是猛、糙、快,方便初學者上手,建立信心。對於有一定基礎的讀者,請不要著急,以後我們會學習主流的開源框架,打造出一個強大專業的爬蟲系統!不過在此之前,要繼續打好基礎,本期我們先介紹爬蟲的種類,然後選取最典型的通用網路爬蟲,為其設計一個迷你框架。有了自己對框架的思考後,再學習複雜的開源框架就有頭緒了。
今天我們會把更多的時間用在思考上,而不是一根筋的coding。用80%的時間思考,20%的時間敲鍵盤,這樣更有利於進步。

語言&環境
語言:帶足彈葯,繼續用Python開路!






一個迷你框架
下麵以比較典型的通用爬蟲為例,分析其工程要點,設計並實現一個迷你框架。架構圖如下:
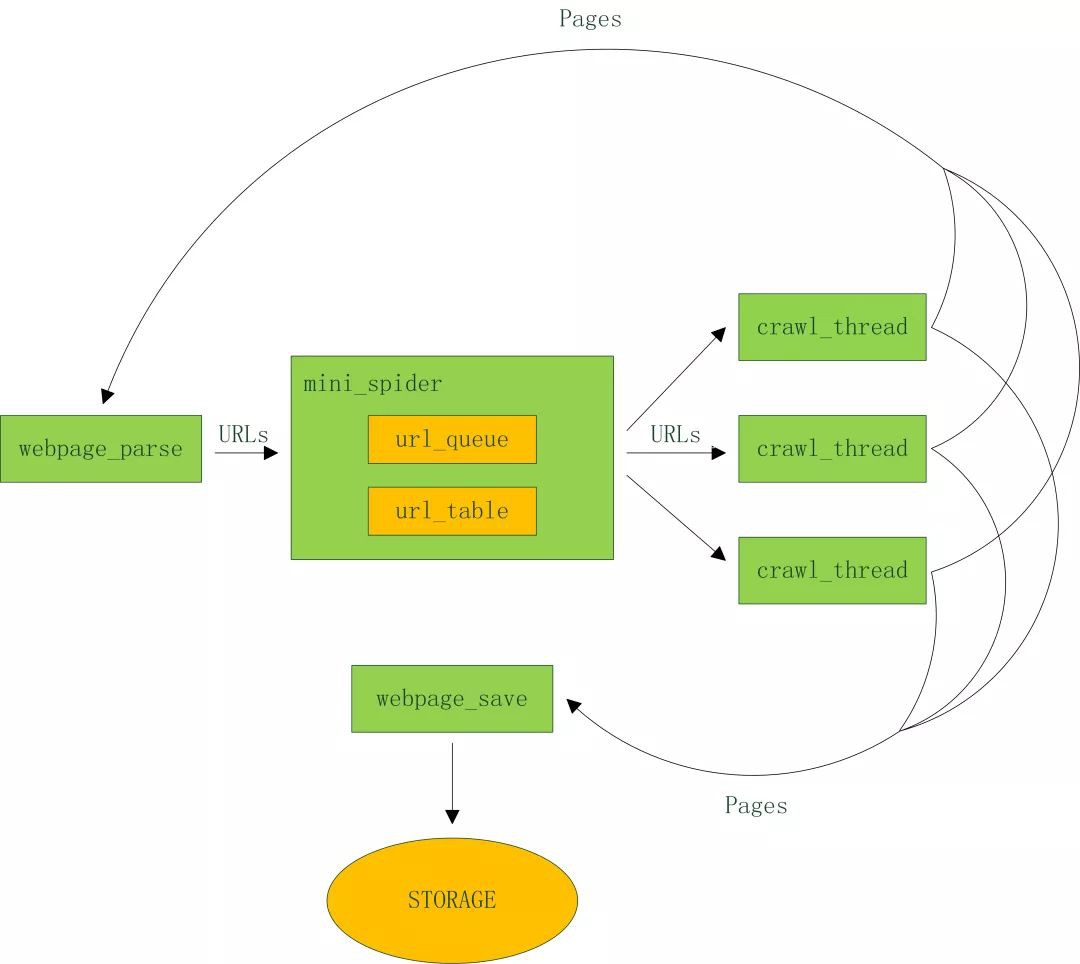
程式碼結構:

config_load.py 配置檔案載入
crawl_thread.py 爬取執行緒
mini_spider.py 主執行緒
spider.conf 配置檔案
url_table.py url佇列、url表
urls.txt 種子url集合
webpage_parse.py 網頁分析
webpage_save.py 網頁儲存
看看配置檔案裡有什麼內容:
spider.conf





url_table.py
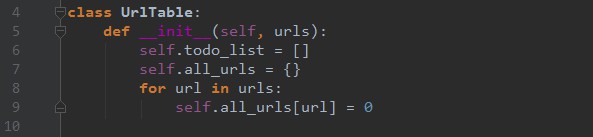
Step 3. 記錄哪些網頁已經下載過的小本本——URL表。
在網際網路上,一個網頁可能被多個網頁中的超連結所指向。這樣在遍歷網際網路這張圖的時候,這個網頁可能被多次訪問到。為了防止一個網頁被下載和解析多次,需要一個URL表記錄哪些網頁已經下載過。再遇到這個網頁的時候,我們就可以跳過它。
crawl_thread.py




Step 5. 頁面分析模組
從網頁中解析出URLs或者其他有用的資料。這個是上期重點介紹的,可以參考之前的程式碼。
Step 6. 頁面儲存模組
儲存頁面的模組,目前將檔案儲存為檔案,以後可以擴展出多種儲存方式,如mysql,mongodb,hbase等等。
webpage_save.py

寫到這裡,整個框架已經清晰的呈現在大家眼前了,千萬不要小看它,不管多麼複雜的框架都是在這些基本要素上擴展出來的。
下一步
基礎知識的學習暫時告一段落,希望能夠幫助大家打下一定的基礎。下期開始為大家介紹強大成熟的爬蟲框架Scrapy,它提供了很多強大的特性來使得爬取更為簡單高效,更多精彩,敬請期待!
●編號409,輸入編號直達本文
●輸入m獲取文章目錄

演演算法與資料結構
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
