
導讀: 用了微信幾年了,微訊號有也不少了,但是真正瞭解自己的好友嗎?好友最多的城市是哪個?好友男女比例是多少?好友簽名都是什麼?今天我們來充分瞭解自己的微信好友。
01 準備工作
執行平臺:Windows
Python版本:Python3.6
IDE:Sublime Text
1. 庫介紹
只有登入微信才能獲取到微信好友的資訊,本文采用wxpy該第三方庫進行微信的登入以及資訊的獲取。
wxpy 在 itchat 的基礎上,透過大量介面最佳化提升了模組的易用性,併進行豐富的功能擴充套件。
wxpy一些常見的場景:
-
控制路由器、智慧家居等具有開放介面的玩意兒
-
執行指令碼時自動把日誌傳送到你的微信
-
加群主為好友,自動拉進群中
-
跨號或跨群轉發訊息
-
自動陪人聊天
-
逗人玩
總而言之,可用來實現各種微信個人號的自動化操作。
2. wxpy庫安裝
wxpy 支援 Python 3.4-3.6,以及 2.7 版本
將下方命令中的 “pip” 替換為 “pip3” 或 “pip2”,可確保安裝到對應的 Python 版本中
從 PYPI 官方源下載安裝 (在國內可能比較慢或不穩定):
pip install -U wxpy
從豆瓣 PYPI 映象源下載安裝 (推薦國內使用者選用):
pip install -U wxpy -i "https://pypi.doubanio.com/simple/"3. 登入微信
wxpy中有一個機器人物件,機器人 Bot 物件可被理解為一個 Web 微信客戶端。Bot在初始化時便會執行登陸操作,需要手機掃描登陸。
透過機器人物件 Bot 的 chats(), friends(),groups(), mps() 方法, 可分別獲取到當前機器人的 所有聊天物件、好友、群聊,以及公眾號串列。
本文主要透過friends()獲取到所有好友資訊,然後進行資料的處理。
from wxpy import *
# 初始化機器人,掃碼登陸
bot = Bot()
# 獲取所有好友
my_friends = bot.friends()
print(type(my_friends))
以下為輸出訊息:
Getting uuid of QR code.
Downloading QR code.
Please scan the QR code to log in.
Please press confirm on your phone.
Loading the contact, this may take a little while.
as 王強?>
<class ‘wxpy.api.chats.chats.Chats‘>
wxpy.api.chats.chats.Chats物件是多個聊天物件的合集,可用於搜尋或統計,可以搜尋和統計的資訊包括sex(性別)、province(省份)、city(城市)和signature(個性簽名)等。
02 微信好友男女比例
1. 資料統計
使用一個字典sex_dict來統計好友中男性和女性的數量。
# 使用一個字典統計好友男性和女性的數量
sex_dict = {'male': 0, 'female': 0}
for friend in my_friends:
# 統計性別
if friend.sex == 1:
sex_dict['male'] += 1
elif friend.sex == 2:
sex_dict['female'] += 1
print(sex_dict)
以下為輸出結果:
{'male': 255, 'female': 104}
2. 資料呈現
本文采用 ECharts餅圖 進行資料的呈現,開啟連結http://echarts.baidu.com/echarts2/doc/example/pie1.html,可以看到如下內容:
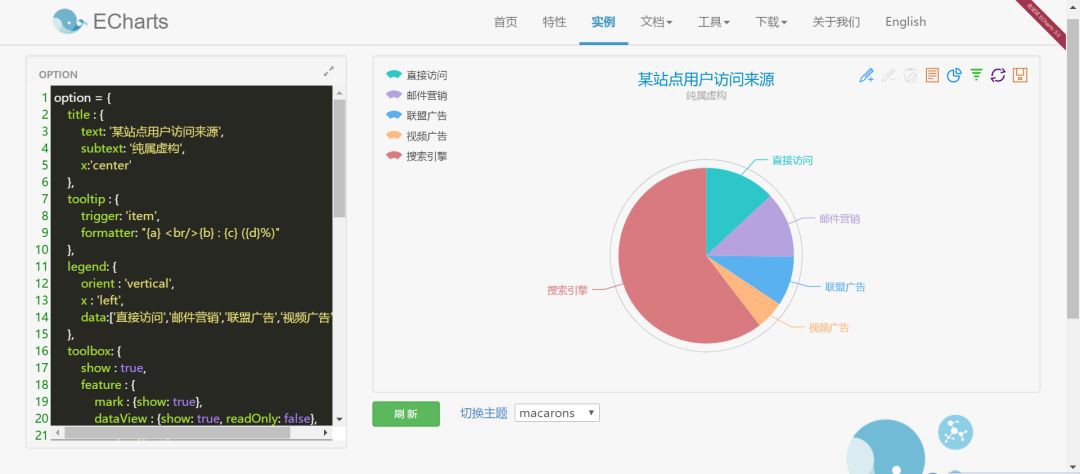
▲echarts餅圖原始內容
從圖中可以看到左側為資料,右側為呈現的資料圖,其他的形式的圖也是這種左右結構。看一下左邊的資料:
option = {
title : {
text: '某站點使用者訪問來源',
subtext: '純屬虛構',
x:'center'
},
tooltip : {
trigger: 'item',
formatter: "{a}
{b} : {c} ({d}%)"
},
legend: {
orient : 'vertical',
x : 'left',
data:['直接訪問','郵件營銷','聯盟廣告','影片廣告','搜尋引擎']
},
toolbox: {
show : true,
feature : {
mark : {show: true},
dataView : {show: true, readOnly: false},
magicType : {
show: true,
type: ['pie', 'funnel'],
option: {
funnel: {
x: '25%',
width: '50%',
funnelAlign: 'left',
max: 1548
}
}
},
restore : {show: true},
saveAsImage : {show: true}
}
},
calculable : true,
series : [
{
name:'訪問來源',
type:'pie',
radius : '55%',
center: ['50%', '60%'],
data:[
{value:335, name:'直接訪問'},
{value:310, name:'郵件營銷'},
{value:234, name:'聯盟廣告'},
{value:135, name:'影片廣告'},
{value:1548, name:'搜尋引擎'}
]
}
]
};
可以看到option =後面的大括號裡是JSON格式的資料,接下來分析一下各項資料:
-
title:標題
-
text:標題內容
-
subtext:子標題
-
x:標題位置
-
tooltip:提示,將滑鼠放到餅狀圖上就可以看到提示
-
legend:圖例
-
orient:方向
-
x:圖例位置
-
data:圖例內容
-
toolbox:工具箱,在餅狀圖右上方橫向排列的圖示
-
mark:輔助線開關
-
dataView:資料檢視,點選可以檢視餅狀圖資料
-
magicType:餅圖(pie)切換和漏斗圖(funnel)切換
-
restore:還原
-
saveAsImage:儲存為圖片
-
calculable:暫時不知道它有什麼用
-
series:主要資料
-
data:呈現的資料
其它型別的圖資料格式類似,後面不再詳細分析。只需要修改data、legend->data、series->data即可,修改後的資料為:
option = {
title : {
text: '微信好友性別比例',
subtext: '真實資料',
x:'center'
},
tooltip : {
trigger: 'item',
formatter: "{a}
{b} : {c} ({d}%)"
},
legend: {
orient : 'vertical',
x : 'left',
data:['男性','女性']
},
toolbox: {
show : true,
feature : {
mark : {show: true},
dataView : {show: true, readOnly: false},
magicType : {
show: true,
type: ['pie', 'funnel'],
option: {
funnel: {
x: '25%',
width: '50%',
funnelAlign: 'left',
max: 1548
}
}
},
restore : {show: true},
saveAsImage : {show: true}
}
},
calculable : true,
series : [
{
name:'訪問來源',
type:'pie',
radius : '55%',
center: ['50%', '60%'],
data:[
{value:255, name:'男性'},
{value:104, name:'女性'}
]
}
]
};
資料修改完成後,點選頁面中綠色的掃清按鈕,可以得到餅圖如下(可以根據自己的喜好修改主題):

▲好友性別比例
將滑鼠放到餅圖上可以看到詳細資料:
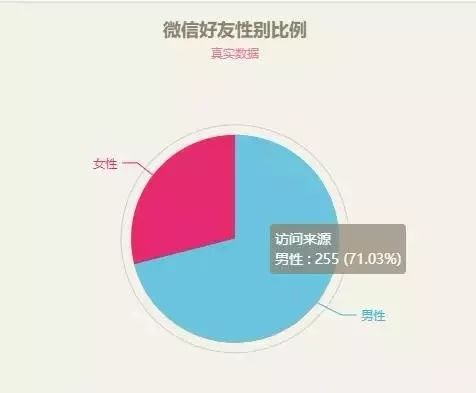
▲好友性別比例檢視資料
03 微信好友全國分佈圖
1. 資料統計
# 使用一個字典統計各省好友數量
province_dict = {'北京': 0, '上海': 0, '天津': 0, '重慶': 0,
'河北': 0, '山西': 0, '吉林': 0, '遼寧': 0, '黑龍江': 0,
'陝西': 0, '甘肅': 0, '青海': 0, '山東': 0, '福建': 0,
'浙江': 0, '臺灣': 0, '河南': 0, '湖北': 0, '湖南': 0,
'江西': 0, '江蘇': 0, '安徽': 0, '廣東': 0, '海南': 0,
'四川': 0, '貴州': 0, '雲南': 0,
'內蒙古': 0, '新疆': 0, '寧夏': 0, '廣西': 0, '西藏': 0,
'香港': 0, '澳門': 0}
# 統計省份
for friend in my_friends:
if friend.province in province_dict.keys():
province_dict[friend.province] += 1
# 為了方便資料的呈現,生成JSON Array格式資料
data = []
for key, value in province_dict.items():
data.append({'name': key, 'value': value})
print(data)
以下為輸出結果:
[{'name': '北京', 'value': 91}, {'name': '上海', 'value': 12}, {'name': '天津', 'value': 15}, {'name': '重慶', 'value': 1}, {'name': '河北', 'value': 53}, {'name': '山西', 'value': 2}, {'name': '吉林', 'value': 1}, {'name': '遼寧', 'value': 1}, {'name': '黑龍江', 'value': 2}, {'name': '陝西', 'value': 3}, {'name': '甘肅', 'value': 0}, {'name': '青海', 'value': 0}, {'name': '山東', 'value': 7}, {'name': '福建', 'value': 3}, {'name': '浙江', 'value': 4}, {'name': '臺灣', 'value': 0}, {'name': '河南', 'value': 1}, {'name': '湖北', 'value': 4}, {'name': '湖南', 'value': 4}, {'name': '江西', 'value': 4}, {'name': '江蘇', 'value': 9}, {'name': '安徽', 'value': 2}, {'name': '廣東', 'value': 63}, {'name': '海南', 'value': 0}, {'name': '四川', 'value': 2}, {'name': '貴州', 'value': 0}, {'name': '雲南', 'value': 1}, {'name': '內蒙古', 'value': 0}, {'name': '新疆', 'value': 2}, {'name': '寧夏', 'value': 0}, {'name': '廣西', 'value': 1}, {'name': '西藏', 'value': 0}, {'name': '香港', 'value': 0}, {'name': '澳門', 'value': 0}]
可以看出,好友最多的省份為北京。那麼問題來了:為什麼要把資料重組成這種格式?因為ECharts的地圖需要這種格式的資料。
2. 資料呈現
採用ECharts地圖 來進行好友分佈的資料呈現。開啟該網址,將左側資料修改為:
option = {
title : {
text: '微信好友全國分佈圖',
subtext: '真實資料',
x:'center'
},
tooltip : {
trigger: 'item'
},
legend: {
orient: 'vertical',
x:'left',
data:['好友數量']
},
dataRange: {
min: 0,
max: 100,
x: 'left',
y: 'bottom',
text:['高','低'], // 文字,預設為數值文字
calculable : true
},
toolbox: {
show: true,
orient : 'vertical',
x: 'right',
y: 'center',
feature : {
mark : {show: true},
dataView : {show: true, readOnly: false},
restore : {show: true},
saveAsImage : {show: true}
}
},
roamController: {
show: true,
x: 'right',
mapTypeControl: {
'china': true
}
},
series : [
{
name: '好友數量',
type: 'map',
mapType: 'china',
roam: false,
itemStyle:{
normal:{label:{show:true}},
emphasis:{label:{show:true}}
},
data:[
{'name': '北京', 'value': 91},
{'name': '上海', 'value': 12},
{'name': '天津', 'value': 15},
{'name': '重慶', 'value': 1},
{'name': '河北', 'value': 53},
{'name': '山西', 'value': 2},
{'name': '吉林', 'value': 1},
{'name': '遼寧', 'value': 1},
{'name': '黑龍江', 'value': 2},
{'name': '陝西', 'value': 3},
{'name': '甘肅', 'value': 0},
{'name': '青海', 'value': 0},
{'name': '山東', 'value': 7},
{'name': '福建', 'value': 3},
{'name': '浙江', 'value': 4},
{'name': '臺灣', 'value': 0},
{'name': '河南', 'value': 1},
{'name': '湖北', 'value': 4},
{'name': '湖南', 'value': 4},
{'name': '江西', 'value': 4},
{'name': '江蘇', 'value': 9},
{'name': '安徽', 'value': 2},
{'name': '廣東', 'value': 63},
{'name': '海南', 'value': 0},
{'name': '四川', 'value': 2},
{'name': '貴州', 'value': 0},
{'name': '雲南', 'value': 1},
{'name': '內蒙古', 'value': 0},
{'name': '新疆', 'value': 2},
{'name': '寧夏', 'value': 0},
{'name': '廣西', 'value': 1},
{'name': '西藏', 'value': 0},
{'name': '香港', 'value': 0},
{'name': '澳門', 'value': 0}
]
}
]
};
註意兩點:
-
dataRange->max 根據統計資料適當調整
-
series->data 的資料格式
點選掃清按鈕後,可以生成如下地圖:

▲好友全國分佈圖
從圖中可以看出我的好友主要分佈在北京、河北和廣東。
有趣的是,地圖左邊有一個滑塊,代表地圖資料的範圍,我們將上邊的滑塊拉到最下麵可以看到沒有微信好友分佈的省份:

▲沒有微信好友的省份
按照這個思路,我們可以在地圖上看到確切數量好友分佈的省份,讀者可以動手試試。
04 好友簽名統計
1. 資料統計
def write_txt_file(path, txt):
'''
寫入txt文字
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f.write(txt)
# 統計簽名
for friend in my_friends:
# 對資料進行清洗,將標點符號等對詞頻統計造成影響的因素剔除
pattern = re.compile(r'[一-龥]+')
filterdata = re.findall(pattern, friend.signature)
write_txt_file('signatures.txt', ''.join(filterdata))
上面程式碼實現了對好友簽名進行清洗以及儲存的功能,執行完成之後會在當前目錄生成signatures.txt檔案。
2. 資料呈現
資料呈現採用詞頻統計和詞雲展示,透過詞頻可以瞭解到微信好友的生活態度。
詞頻統計用到了 jieba、numpy、pandas、scipy、wordcloud庫。如果電腦上沒有這幾個庫,執行安裝指令:
-
pip install jieba -
pip install pandas -
pip install numpy -
pip install scipy -
pip install wordcloud
2.1 讀取txt檔案
前面已經將好友簽名儲存到txt檔案裡了,現在我們將其讀出:
def read_txt_file(path):
'''
讀取txt文字
'''
with open(path, 'r', encoding='gb18030', newline='') as f:
return f.read()
2.2 stop word
下麵引入一個概念:stop word, 在網站裡面存在大量的常用詞比如:“在”、“裡面”、“也”、“的”、“它”、“為”這些詞都是停止詞。這些詞因為使用頻率過高,幾乎每個網頁上都存在,所以搜尋引擎開發人員都將這一類詞語全部忽略掉。如果我們的網站上存在大量這樣的詞語,那麼相當於浪費了很多資源。
在百度搜索stopwords.txt進行下載,放到py檔案同級目錄。
content = read_txt_file(txt_filename)
segment = jieba.lcut(content)
words_df=pd.DataFrame({'segment':segment})
stopwords=pd.read_csv("stopwords.txt",index_col=False,quoting=3,sep=" ",names=['stopword'],encoding='utf-8')
words_df=words_df[~words_df.segment.isin(stopwords.stopword)]
2.3 詞頻統計
重頭戲來了,詞頻統計使用numpy:
import numpy
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"計數":numpy.size})
words_stat = words_stat.reset_index().sort_values(by=["計數"],ascending=False)
2.4 詞頻視覺化:詞雲
詞頻統計雖然出來了,可以看出排名,但是不完美,接下來我們將它視覺化。使用到wordcloud庫,詳細介紹見 github 。
from scipy.misc import imread
from wordcloud import WordCloud, ImageColorGenerator
# 設定詞雲屬性
color_mask = imread('background.jfif')
wordcloud = WordCloud(font_path="simhei.ttf", # 設定字型可以顯示中文
background_color="white", # 背景顏色
max_words=100, # 詞雲顯示的最大詞數
mask=color_mask, # 設定背景圖片
max_font_size=100, # 字型最大值
random_state=42,
width=1000, height=860, margin=2,# 設定圖片預設的大小,但是如果使用背景圖片的話, # 那麼儲存的圖片大小將會按照其大小儲存,margin為詞語邊緣距離
)
# 生成詞雲, 可以用generate輸入全部文字,也可以我們計算好詞頻後使用generate_from_frequencies函式
word_frequence = {x[0]:x[1]for x in words_stat.head(100).values}
print(word_frequence)
word_frequence_dict = {}
for key in word_frequence:
word_frequence_dict[key] = word_frequence[key]
wordcloud.generate_from_frequencies(word_frequence_dict)
# 從背景圖片生成顏色值
image_colors = ImageColorGenerator(color_mask)
# 重新上色
wordcloud.recolor(color_func=image_colors)
# 儲存圖片
wordcloud.to_file('output.png')
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
執行效果圖如下(左圖為背景圖,右圖為生成詞雲圖片):

▲背景圖和詞雲圖對比
從詞雲圖可以分析好友特點:
-
做——————–行動派
-
人生、生活——–熱愛生活
-
快樂—————–樂觀
-
選擇—————–決斷
-
專業—————–專業
-
愛——————–愛
05 總結
至此,微信好友的分析工作已經完成,wxpy的功能還有很多,比如聊天、檢視公眾號資訊等,有意的讀者請自行查閱官方檔案。
06 完整程式碼
上面的程式碼比較鬆散,下麵展示的完整程式碼我將各功能模組封裝成函式:
#-*- coding: utf-8 -*-
import re
from wxpy import *
import jieba
import numpy
import pandas as pd
import matplotlib.pyplot as plt
from scipy.misc import imread
from wordcloud import WordCloud, ImageColorGenerator
def write_txt_file(path, txt):
'''
寫入txt文字
'''
with open(path, 'a', encoding='gb18030', newline='') as f:
f.write(txt)
def read_txt_file(path):
'''
讀取txt文字
'''
with open(path, 'r', encoding='gb18030', newline='') as f:
return f.read()
def login():
# 初始化機器人,掃碼登陸
bot = Bot()
# 獲取所有好友
my_friends = bot.friends()
print(type(my_friends))
return my_friends
def show_sex_ratio(friends):
# 使用一個字典統計好友男性和女性的數量
sex_dict = {'male': 0, 'female': 0}
for friend in friends:
# 統計性別
if friend.sex == 1:
sex_dict['male'] += 1
elif friend.sex == 2:
sex_dict['female'] += 1
print(sex_dict)
def show_area_distribution(friends):
# 使用一個字典統計各省好友數量
province_dict = {'北京': 0, '上海': 0, '天津': 0, '重慶': 0,
'河北': 0, '山西': 0, '吉林': 0, '遼寧': 0, '黑龍江': 0,
'陝西': 0, '甘肅': 0, '青海': 0, '山東': 0, '福建': 0,
'浙江': 0, '臺灣': 0, '河南': 0, '湖北': 0, '湖南': 0,
'江西': 0, '江蘇': 0, '安徽': 0, '廣東': 0, '海南': 0,
'四川': 0, '貴州': 0, '雲南': 0,
'內蒙古': 0, '新疆': 0, '寧夏': 0, '廣西': 0, '西藏': 0,
'香港': 0, '澳門': 0}
# 統計省份
for friend in friends:
if friend.province in province_dict.keys():
province_dict[friend.province] += 1
# 為了方便資料的呈現,生成JSON Array格式資料
data = []
for key, value in province_dict.items():
data.append({'name': key, 'value': value})
print(data)
def show_signature(friends):
# 統計簽名
for friend in friends:
# 對資料進行清洗,將標點符號等對詞頻統計造成影響的因素剔除
pattern = re.compile(r'[一-龥]+')
filterdata = re.findall(pattern, friend.signature)
write_txt_file('signatures.txt', ''.join(filterdata))
# 讀取檔案
content = read_txt_file('signatures.txt')
segment = jieba.lcut(content)
words_df = pd.DataFrame({'segment':segment})
# 讀取stopwords
stopwords = pd.read_csv("stopwords.txt",index_col=False,quoting=3,sep=" ",names=['stopword'],encoding='utf-8')
words_df = words_df[~words_df.segment.isin(stopwords.stopword)]
print(words_df)
words_stat = words_df.groupby(by=['segment'])['segment'].agg({"計數":numpy.size})
words_stat = words_stat.reset_index().sort_values(by=["計數"],ascending=False)
# 設定詞雲屬性
color_mask = imread('background.jfif')
wordcloud = WordCloud(font_path="simhei.ttf", # 設定字型可以顯示中文
background_color="white", # 背景顏色
max_words=100, # 詞雲顯示的最大詞數
mask=color_mask, # 設定背景圖片
max_font_size=100, # 字型最大值
random_state=42,
width=1000, height=860, margin=2,# 設定圖片預設的大小,但是如果使用背景圖片的話, # 那麼儲存的圖片大小將會按照其大小儲存,margin為詞語邊緣距離
)
# 生成詞雲, 可以用generate輸入全部文字,也可以我們計算好詞頻後使用generate_from_frequencies函式
word_frequence = {x[0]:x[1]for x in words_stat.head(100).values}
print(word_frequence)
word_frequence_dict = {}
for key in word_frequence:
word_frequence_dict[key] = word_frequence[key]
wordcloud.generate_from_frequencies(word_frequence_dict)
# 從背景圖片生成顏色值
image_colors = ImageColorGenerator(color_mask)
# 重新上色
wordcloud.recolor(color_func=image_colors)
# 儲存圖片
wordcloud.to_file('output.png')
plt.imshow(wordcloud)
plt.axis("off")
plt.show()
def main():
friends = login()
show_sex_ratio(friends)
show_area_distribution(friends)
show_signature(friends)
if __name__ == '__main__':
main()
作者 / 來源:C與Python實戰
ID:CPythonPractice
推薦閱讀
Q: 你有哪些奇葩微信好友?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩,請在後臺點選“歷史文章”檢視

