潘衛華 / 唯品會基礎架構部架構師,唯品會Dragonfly日誌系統負責人。
對 Elasticsearch 和大資料流式處理有豐富經驗,對Golang及其程式的效能最佳化也有較多研究。
前言
大家下午好!我是來自唯品會基礎架構部的潘衛華。今天我們來跟大家一起看看在大資料領域裡面,Golang的應用。我們知道在大資料領域裡,Java 和 Scala 語言基本是處於統治地位的,主要是因為像 Hadoop 以及基於 Hadoop 的一些工具棧,比如 HBase/Hive/Spark/Flink 等等,這些都是基於 Java 或者 Scala開發,他們提供 的api 也是主要給 Java 系的語言來使用的。不過實際在專案過程中,我認為還是在一些地方Golang是可以有用武之地的。
我將從以下幾個方面作分享:
一、唯品會日誌系統及本人簡介
二、Access Log儲存需求分析
三、Access Log Writer設計和實現
四、Golang應用在大資料領域的思考
一、唯品會日誌系統及本人簡介
唯品會Dragonfly日誌系統簡介
我在唯品會負責公司日誌系統,叫做 Dragonfiy。大家可能聽過最近阿裡有一個開源工具也叫 Dragonfly,但兩者並不相同,阿裡開源的Dragonfly是做容器映象分發的,我們這個 Dragonfiy 是日誌平臺。我們這個專案從2015年就開始搭建,到現在為止已經接入全公司幾乎全部應用的日誌,還包括一共2000多個應用的訪問日誌,Dragonfly提供一些日誌的儲存和查詢、統計包括告警這些功能。
整個系統是最初基於 ELK 來打造的,之後也加入我們自研的一些模組,包括告警。我們可以讓使用者自定義設計告警規則,比如說有哪些關鍵字,需要達到多少條數,就可以觸發告警,我們也可以智慧的去分析日誌資料,發現異常時可以自己告警,不需要使用者去配置。現在這個日誌系統是整個唯品會監控系統裡面非常重要的組成部分,每天會幫助我們預防或及早發現很多問題。
Golang 在 Dragonfly 方面的應用
這個系統資料量非常大,平日每天接入應用日誌數 600 億條左右,壓縮完之後,每天日誌兩大概有 40 TB。另外訪問日誌數每天超過 1400 億條。下麵介紹在我們日誌系統裡面Golang主要應用。
採集客戶端程式
第一,採集客戶端程式。Elastic公司開源的beats主要用來做日誌的採集上傳,我們的日誌採集工具是基於 beats 做二次開發,在 beats 的基礎上我們做的日誌的解析、統計、配置下發,包括在客戶端裡面配置要採集什麼樣的檔案,是否要做限流或者取樣,還有解析等的一些規則,這些可以透過管理介面配置,動態下發,所以整個配置管理非常方便。 然後我們還支援容器日誌採集。
另外在 beats 的基礎上也做了很多效能的最佳化。我們原來用的Logstash,大家可能之前聽說過,我們效能比Logstash高了4倍以上,而且記憶體比Logstash少很多,Logstash我們原來用1G的記憶體來採集,有的情況還不夠,而我們開發的新日誌採集客戶端,記憶體使用才幾十兆。
最初我們系統裡面用Golang的專案就是這個,經過這個專案之後我們發現Go語言效能非常好,而且開發起來效率非常高,後面我們盡可能把Go語言盡可能用在場景語言去。
後來Golang在Dragonfly的第二大應用,就是我們今天介紹的,Access Log儲存系統。
二、Access Log儲存需求分析
Access log儲存和查詢
Access log 每個網際網路公司都會有,通常資料量非常大。像我們公司原來是用Access log 採集上來做離線處理生成一些報表,但是對於使用者的Ad-hoc查詢來說,非常不靈活,透過Hive查詢,每次查詢非常慢,如果每次查某個應用 Access log,可能超過十幾分鐘才能完成一次查詢,如果有些陳述句或者有些欄位輸入有問題,條件不太好,出來並不是客戶想要的結果,他又反覆來查,但這時這個效率就非常低。
我們公司除了 Nginx Access Log ,還有其它元件的Access log,這些也沒有接入到Hive裡面,開發也沒有辦法去用,所以我們想打造另外一個Access log儲存的系統,主要對開發的同事能夠快速提供Access log下載和查詢的系統,這是一個背景。
Access log 的寫入和儲存有什麼樣的特徵,我們先要確定,再看怎麼設計這個系統。
首先,Access log 的資料非常多,比如說我們公司每天有1000多億條資料,平均下來每秒鐘會有各種元件加起來的訪問量都有幾百萬QPS,意味著每秒鐘會有幾百萬條 Access log,這些如果要做儲存,就要思考要做這麼大流量寫入的問題。像我們公司有幾個元件,一個是 Nginx,一個是 janus 伺服器閘道器,還有Osp——微服務元件。
第二個特點就是它們的使用頻率並不是特別高。大家可能也會知道,工信部要求訪問日誌需要儲存半年以上,這種更多是一個儲存是為了監管的需求。另外就是報表,還有就是其它除了問題開發者才需要訪問。很多訪問日誌,幾個月下來有可能完全沒有人來訪問,也是有可能的。
所以訪問頻率很低,針對這種特點,沒有必要花很多硬體或者其它複雜設計上去做一個非常完美的系統,我們只需要提供低成本然後高效能,主要是解決儲存問題,其次提供一個簡單的查詢方案。
第三個特點是實時性不需要特別高,通常幾分鐘的ok的。
所以針對這幾點需求,我們設計了大概的方案是這樣的,就是我們把資料壓縮儲存到HDFS裡面,然後提供一個簡單的查詢結果。為什麼用到HDFS?其實也不一定,像其它分散式儲存系統,比如GlusterFS之類,只要你的容量夠其實也可以的。但儲存的HDFS還保留一個可能,以後資料還會用一些大資料工具去分析,所以我們用HDFS。其實後面要解決一些問題,就算用其它分散式系統也是要解決的。
總體解決方案
這麼大量的資料,我們肯定要壓縮才能儲存進去的,所以我們要選擇壓縮的方式。如果要滿足一個比較高的實質性需求,我們只能選擇流式的壓縮,我們不可能等一個檔案一天寫完之後才導進去一次,這樣使用者也是沒有辦法去查的。我們選的是 gzip 壓縮方式,因為 gzip 是支援拼接的,如果寫完一塊壓縮寫到一個檔案裡面去,然後後面我們再壓縮另外一段資料,拼接到後面,這種資料是可以完整把它解壓出來的,所以它這個 gzip 非常適合流式寫入。
gzip 還有一個特點是解壓相對比較方便一點,使用者下載回去以後,這些檔案有些 gzip 這樣的工具就可以解壓開,如果在 zless/zcat 等方式更方便了。但它本身是十幾年前的一種壓縮方法,雖然它的壓縮率很高,但是它的壓縮效能比起最近幾年一些新的演演算法,比如snappy,lz4等等,它的壓縮效能和解壓效能都是沒有那麼高的。但主要考慮到使用者使用方便,我們還是選用 gzip 流式壓縮的方案。
還有一個就是檔案怎麼樣命名給使用者提供一個下載,這個主要考慮到使用者怎麼樣使用,我們在命名方式就是按照型別,前面說的方式是什麼樣的應用存過來的,主機名、日期、小時、滾動序號。這裡主要考慮到使用者如果要下載,如果你有一個檔案非常大,超過100兆下載是有困難的,所以我們是按照100兆來做一個滾動,這是一個檔案命名的規則。
技術難點
在這個方案裡面這裡會遇到什麼樣的技術難點?首先一個資料量比較大,按照我們剛才命名規則來說,我們會遇到這樣一個問題,每小時會寫入幾萬以上的檔案——有很多 Access log 的型別,然後有很多應用,然後有很多主機,我們也有上萬臺主機,各種 Access log 加起來總共會有2萬以上的檔案,我們要支援他能夠流式寫入到檔案系統裡面,這個會對檔案系統 IO 會造成很大的壓力,寫入次數會非常大。這裡就是我前面說的選哪種檔案系統其實沒有很大的關係,你都需要解決高併發量寫入的問題,這是主要的技術難點。
那我們怎麼樣去解決,大家可以思考一下。有這裡有一個套路,這麼大的流量,我們肯定不會讓每個資料都寫入一次,最常用的套路就是快取,快取下來過一段時間再刷一次盤。
所以解決這個效能的一個方案就是快取,快取又會碰到另外一個問題,快取又佔用記憶體,比如說我們是每小時收一個檔案,如果要快取一個小時資料再寫入,這個要非常多記憶體才能支援,所以整個設計方案裡面要考慮到記憶體的佔用。到底快取多少合適,怎麼樣快取比較合適。最初我們透過Spark實現這個方案,這樣的實現方案最直接,Spark 從Kafka撈資料,然後快取一段時間,一分鐘,批次讀一次,批次壓縮。但是這個我們發現對記憶體佔用也是消耗太大了,我們去做其中一種 Access log 的寫入,最開始用了十臺伺服器才能支援,如果支援那麼多中 Access log,可能要幾十臺機器,這個成本有點高,所以後來我們是考慮一定要用更好的方案去實現。
三、Access Log Writer設計和實現
語言選擇
看一下這個設計方案,這個是取用大概的設計思路,從 kafka 裡消費資料,解析出來之後會生成檔案路徑,透過兩級的快取,最後再寫入到 HDFS 裡面。
這個方案最初我們也考慮到用什麼語言去設計。用 Java 還是用 Go?這種比較其實需要把它拆分幾個方面來考慮,考慮不同的權重對我們影響比較大。其中一個方向就是考慮開源框架和開源庫的支援,大資料前面已經說了,Java 是得到非常多支援,有很多庫和框架來做,所以其實Java在這一塊完全是領先的,但是具體到我們剛才涉及到的方案來說,我們其實只需要用兩種開源庫,一個是讀Kafka,一種是寫入到HDFS,這兩個在 Go 裡面其實都是有的,所以對這個框架來說兩個語言都是可以的。前提是不需要分散式協同處理,只需要每臺機能夠單獨處理,可以水平拓展,我們其實用go就可以實現。
從考慮效能來說,本來 Java 效能也不錯,但是 Java 的一個很大問題,它的 GC 調優非常困難,我們整個日誌系統裡面原來大部分都是 Java 和 scala 做的,在我們以前經驗來看,處理很大吞吐量情況下,Java 的 GC 會是一個非常大的問題,我們之前會花很多時間來做 GC 的調優。雖然最終 Java 和 Golang 可能會差不多,但是考慮到調優的複雜度來說,對記憶體使用的複雜度來說,其實 Golang 還是更優一點。在jdk9之前,Java對每個文字字元,需要兩個byte來儲存。所以它記憶體用 Go 來說,其實有比較大的優勢。
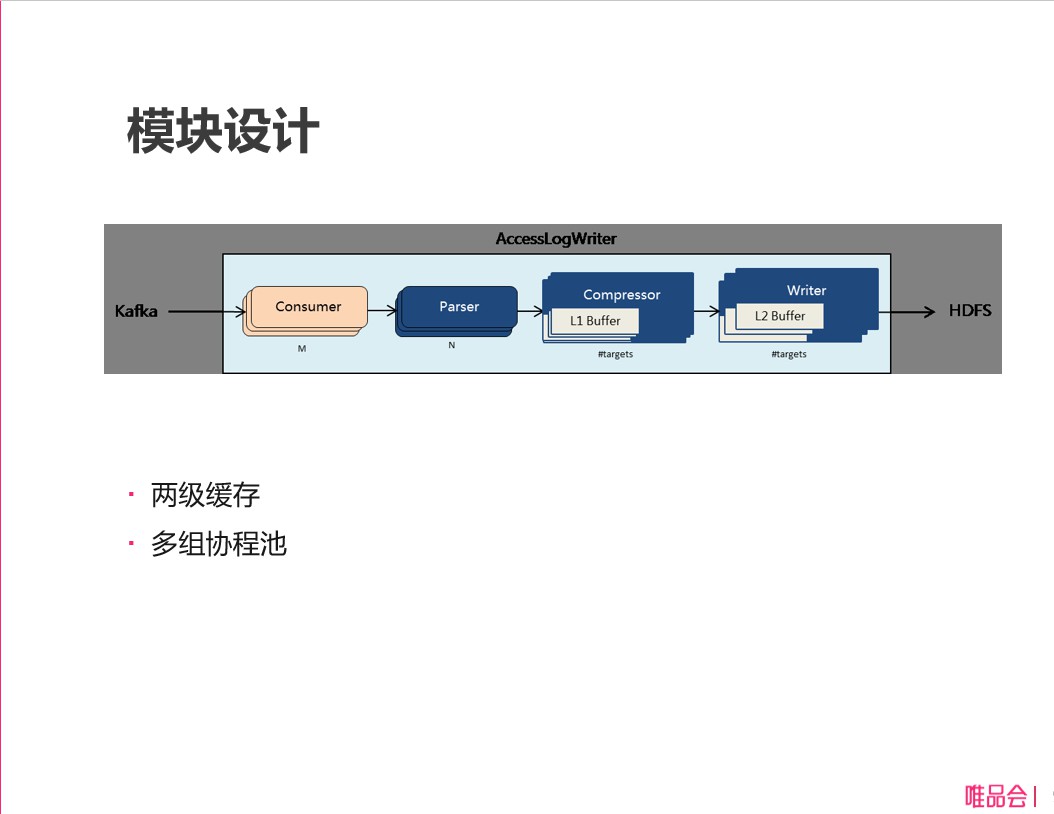
模組設計
剛才說過了主要是兩級快取、多組協程池,每個模組都是多組 Goroutine。
模組一、consumer
下麵再仔細深入一下,第一個模組 consumer,這塊主要是消費 Kafka 的資料。日誌是在客戶端採集完之後上傳到 Kafka 裡面去的,就是需要從 Kafka 把它消費出來。
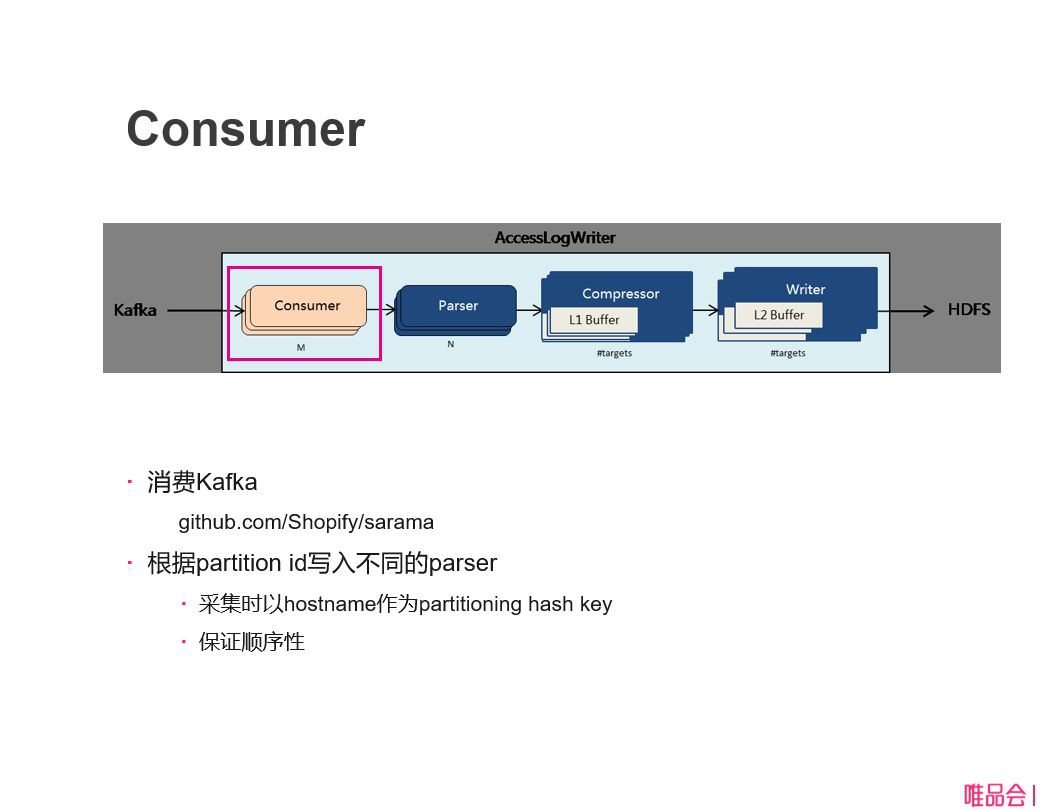
這裡我們用到一個 sarama 讀Kafka的庫,讀完kafka資料之後,需要把資料塞到 parser 解析,這裡會根據讀出來訊息的partition id 到不同的 parser 裡面去,這裡有個目的是保證最終寫入到檔案裡面的 Access log 的順序性。我們在客戶端,它是以什麼樣的順序落盤的,我們最終提供給使用者 Access log 的檔案也要保證順序性。這裡需要做兩件事情:
第一、在採集的時候就需要用 hostname 作為 partition,如果大家有接觸過Kafka就知道,它有個 key 的配置,就是我以什麼 key 來做Hash,然後決定寫入到哪個 partition 裡面去。如果以 hostname 作為 partition,我們就能保證同一臺主機檔案是落入到裡面的,它在同一個 partition 裡面處理是順序處理,所以我們就能保證他的順序性。
第二、在 Kafka上面保證順序性之後,在這個地方處理的時候也要保證順序性,就讓同一個 partition 過來的資料也在同一個 parser 裡面去處理,然後一直留到後面去。
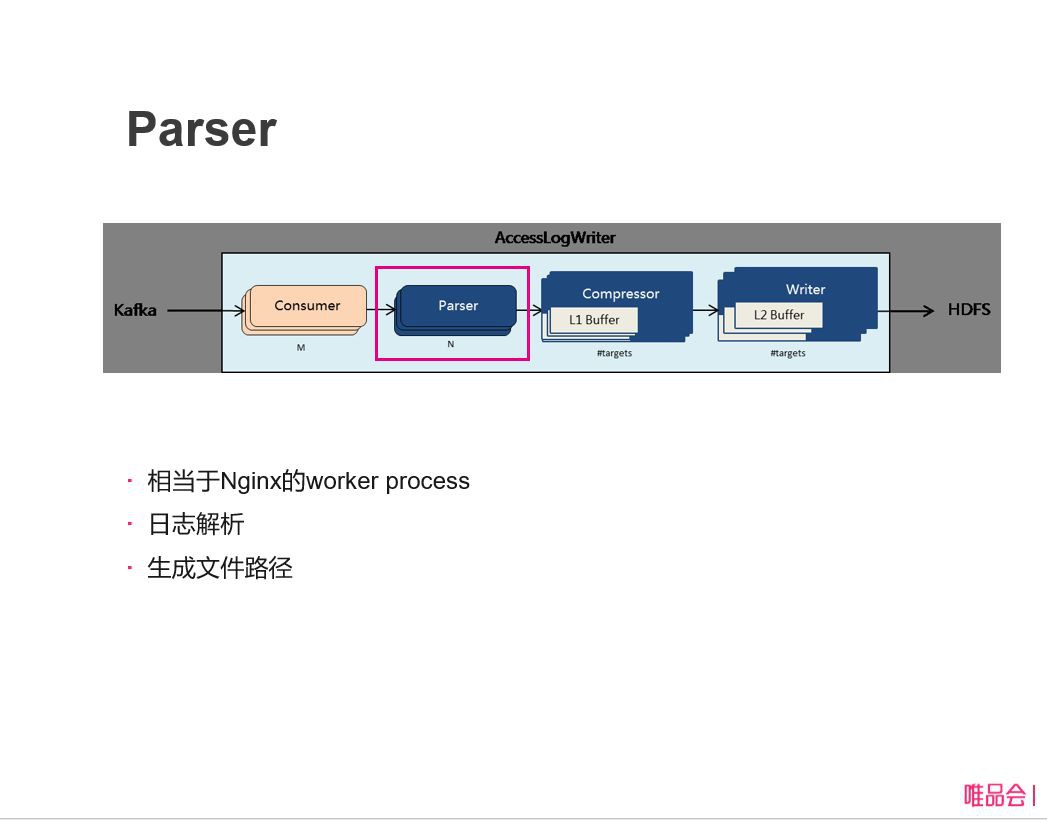
模組二、parser
parser 這部分比較簡單一點,工作樣式就類似於 Nginx 裡面的 worker process,做無狀態的處理,它把日誌解析完之後,提取了前面說那幾個欄位:應用名、主機名、時間戳的解析等等,那些解析完之後就成成一個檔案路徑,丟到後面不同的 Compressor 裡面去。
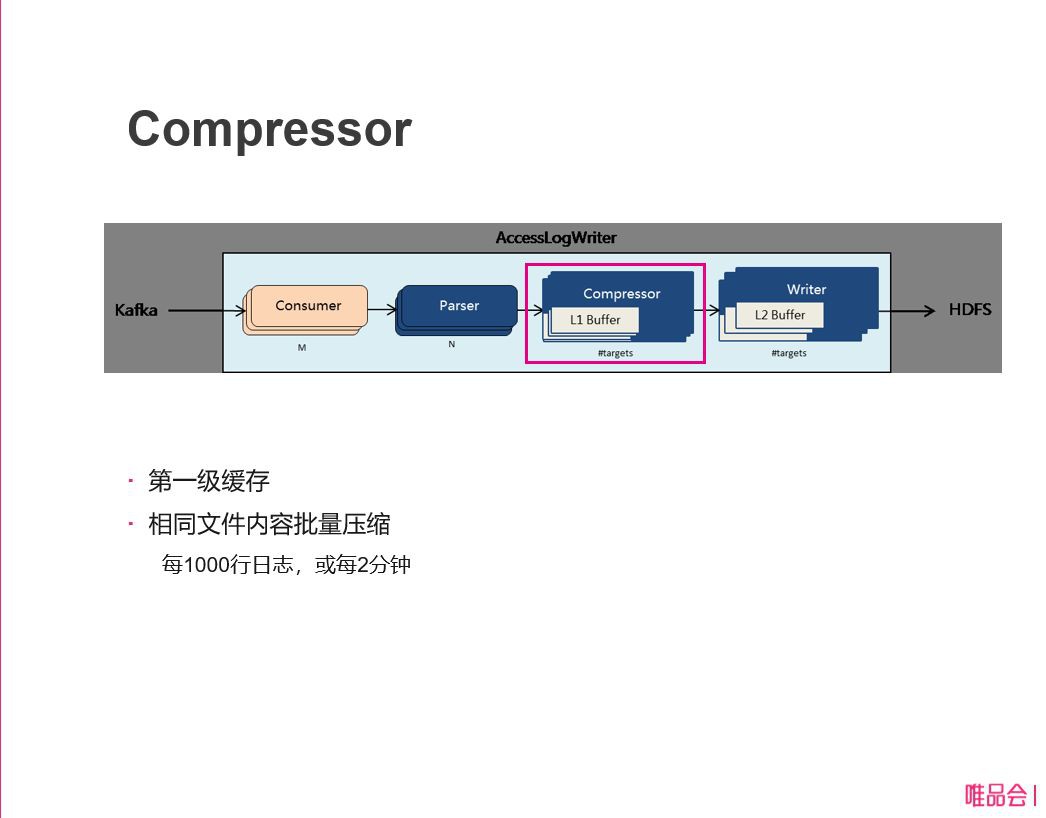
模組三、Compressor
Compressor 是我們兩級快取的第一級,這裡是做一個檔案的批次壓縮,同一個檔案每超過1000行的日誌或者等到2分鐘之後,就做一個壓縮,生成壓縮塊往後丟。為什麼要批次壓縮?這個是為了提高壓縮效率,如果每條日誌過來壓縮也是可以的,但是這個壓縮率大家知道沒有大批次資料一起壓縮的壓縮率高的,所以第一級快取主要提高壓縮率。
模組四、writer
然後是 writer 的模組,這裡就是第二級快取,每超過5MB或者每10分鐘的時候,我們就往 HDFS 寫入一次,透過這個快取可以減少寫 HDFS 的寫入次數。另外它還要處理檔案滾動,檔案每達到100兆可能就要寫入一次,如果寫入失敗我們叫做重試等等。
剛才介紹完整個設計的思路,整個程式碼量不是太多,如果去掉什麼引數處理,監控API之類的,核心程式碼不超過1000行。
最佳化
後面講一下最佳化的思路,怎麼樣達到非常高的效能。我們做Go語言開發,大家如果做過最佳化就知道,通常有兩個方面:
第一,CPU的分析和最佳化。這個主要用火焰圖的工具。二是記憶體使用的最佳化。
透過火焰圖的分析我們發現有幾個地方是使用CPU的熱點,這個需要我們最佳化的,其中一個是壓縮的部分,我們找了一下,其實剛才看到整個資料的流程裡面壓縮那塊佔用最大一塊CPU的時間,所以壓縮庫這塊我們查了一下,一個有github.com/klauspost/compress/gzip這麼一個壓縮庫,比原來Go自帶的模組來說效能提高了20%。其實Go語言不少自帶庫的效能都不怎麼樣,比如說json序列化就非常差,一般會儘量用easyjson等庫來替代。這個壓縮庫也是。

第二,這裡給大家介紹一下 Kafka 庫的最佳化,這並不是說庫本身有什麼問題。這裡給大家介紹一下, slice growup,這是 Go 語言裡面經常碰到對效能影響比較大的地方。像 Sarama 庫裡面也是,它會申請一塊記憶體做一個訊息的解壓。kafka 裡面他會批次壓縮幾百條訊息,然後丟到 Kafka 裡面,去消費的時候也需要把這塊東西解壓出來再處理的,Sarama這個庫是耗記憶體的,需要把壓縮的資料拉過來之後解壓放到 buffer 裡面,剛開始它不知道 buffer 需要多大,所以一開始是很小的,所以一邊解壓一邊丟過去,發現 slice 不夠大的時候,就申請新的空間,把舊資料copy過去,這塊是非常消耗效能的,如果呼叫數特別多。

這是大家經常看到的一個地方,看火焰圖或者看 CPU 分析裡面也可以看到,通常解決方案就是預分配一個大小給buffer物件預分配一個大小,最關鍵我們怎麼預測到這個 buffer 大小多大,避免這個 grow 或者減少 grow 的情況,在這個例子裡面,我們設計了滑動平均值的變數,這個滑動平均值我們是用來計算壓縮率的平均,就是滑動平均的情況,根據歷史壓縮滑動平均值然後乘上現在進來壓縮塊的大小,我們可以預測出來解壓後有多大,經過這麼一個最佳化,我們對整個程式其實也提高10%的效能,也是非常不錯的。
第三,記憶體管理,我們整個模組裡面用到非常多記憶體,無論在第一級裡面還是第二級,如果沒有一個比較好的記憶體管理,這個記憶體塊用完就丟,也會造成一些問題。在這裡也用到一個 Free list 去快取我們這個記憶體塊。
前面也提到golang官網裡這個 effective go的文章,Free list 其實是 effective go 裡面例子,也是教大家怎麼樣有效管理記憶體。我覺得這個非常好用,所以我們用在這個模組裡面,是一個簡潔的方案。首先定義了一個固定大小的 channel,叫做 Free list,然後當我們需要新的 buffer 的時候,如果調 getBuffer 這個函式,它先看 Free list 裡面有沒有多餘物件,已經放到這個 chan 裡面,有直接在 chan 彈一個出來,我們就得到一個 Buffer,如果沒有就建立一個新的 Buffer 物件,getBuffer 的過程,我們再結合 returnBuffer 的過程,returnBuffer 我們用完這個 Buffer 的時候,我們就把這個 Buffer 塞到 Free list 裡面,塞進去就是裡面如果 get 的時候,發現這個 chan 裡面有,就可以直接拿出來,這個 Buffer 就可以反覆被使用,如果這個 Free list 裡面已經滿的時候,我們可以丟掉一些,因為有時候正在使用已經佔一大批,同時有很多傳回 Free list,chan 可能已經滿了,這時候就可以把 chan 丟棄就可以了,大家可以看到 Free list 管理記憶體池一個東西,是非常簡練的實現。


各位有多少在學習golang的時候見過這個記憶體管理的方法的?我建議大家看一下官方檔案,無論屬於什麼語言,最好的教材就是官方檔案,除了語法外還有很多技巧, effective go 裡面有非常好的用法。

最終效果,我們這個模組最後能夠控制透過 HDFS 寫入頻率在 50QPS 左右,對每小時2萬個檔案,如果不停有訊息寫入,HDFS 會非常高,對這個情況已經優化了很多,50QPS 對於 HDFS 來說一點壓力都沒有,對於其它檔案系統來說也一點壓力都沒有。在我們公司常用的伺服器上面,我們處理能力能夠達到每秒達到150萬條日誌,我們用128GB的記憶體,實際上記憶體使用在64G以下,我們會預留一些 Buffer 來說,如果有延遲,可以用更多資料快取。在這次雙十一大促的時候,我們日誌峰值達到每秒鐘1200萬條日誌,我們只用8臺伺服器就可以支撐下來,效能非常高,跑起來非常穩定。

除了寫入之外,我們還提供了簡單查詢,也是用go來做的,這塊主要考慮支援使用者以前傳統使用 Access log 的習慣,習慣做 AWK 等等命令這些拼接起來處理,可以算一下在某一段時間最大的響應時間或者90分位之類的統計,透過這種計算都可以做的。
總結
總結一下我們整個設計裡面重點:
第一,gzip 流式壓縮是整個設計的前提;
第二,兩級快取,第一級快取裡面減少快取的大小,前面說Spark對記憶體佔用很多,還有沒有壓縮,或者說壓縮比例很小,透過一級快取,我們快取裡面可以放更多的日誌。透過第二級快取我們可以降低HDFS寫入次數;
第三,我們透過Golang保證整個系統效能非常高,對資源佔用也有保障。

我們回頭再看一下,透過這麼一個專案,大家想象一下 Golang 在大資料裡面到底有多大的使用前景?
Golang應用在大資料領域的思考
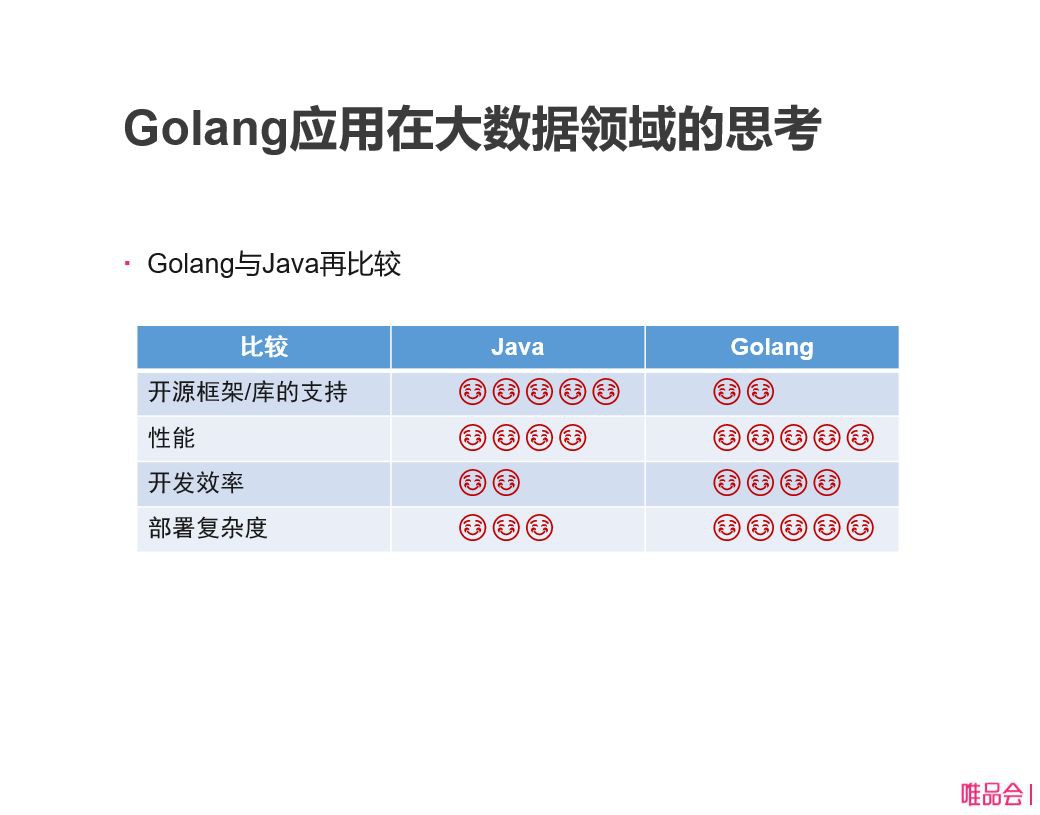
討論這個問題,我們再對比一下 Golang 和Java,Java 開源框架和開源庫的支援是非常好的,可以打5星,Golang 在這方面還是比較缺失。總體來說如果要用多很多開源方向庫,Java 這塊還是優勢,另外還有效能前面對比過了,考慮對記憶體使用來說,Golang 還是稍微好一點。開發效率,Golang 比 Java 要強很多,還有部署複雜度大家非常清楚,Golang部署非常方便。
從這裡引申開來,我認為Go語言在大資料領域確實有不適應的場景,特別是需要用在 MapReduce 等分散式計算模型。這裡就包括如果在多臺機器上面處理資料,最終需要聚合起來,用 reduce 計算的情況,用 go 是因為沒有這種框架的,如果要做完全自己實現是非常複雜的邏輯。所以如果用 reduce 的處理這種 Golang 是不適合,意味著大部分離線計算,現在很多離線計算是用 MapReduce 或者用 Spark 上面類似於 MapReduce 這樣的計算框架來做的,如果沒有這個框架是做不了這個計算的。在哪些地方可以適用,最大場景就是ETL,這個ETL作用就是從拉取原資料做資料的轉換,然後再儲存到資料倉庫裡面過程,這個大資料計算裡面非常重要的環節,其實剛才我們介紹了的Access Log儲存就是這麼一個過程。

中間的轉化主要是包括這麼目的,一個是資料的清洗,有沒有無效的資料要把它清洗掉,還有一個資料的修複,比如說有些欄位本來是正值,忽然傳來負值真麼辦,這時候應該嘗試修複一下,而不是把它丟掉,還有一些資料格式的轉化,按照你資料的格式把它轉化一下再儲存到資料倉庫裡面,這是ETL的過程。
其實前面幾年大家都追求大資料,希望資料越多約好,現在大家開始註重資料質量,儲存到大資料裡面的資料質量,最重要大資料處理的結果是不是有非常大的影響,所以在ETL的過程,我認為 Golang 由於前面效能的優勢,在這塊是可以施展拳腳的。引申開就是分散式協同計算,不需要reduce計算的流式處理。還有就是中小規模資料量,針對ETL,用 Go 沒有分散式框架來做,可能麻煩一點,如果涉及到需要很大的叢集,有幾十臺機器,上百臺機器,這時候就需要加入到排程框架上面做這些事情,因為在 Java 已經有成熟的框架支援,所以會簡單一些,在 GO 上,在幾臺伺服器規模的實踐上其實是可以做的,這些是我的思考,有些思路希望跟大家分享一下。
我的分享就這麼多,大家有什麼問題。
Q&A;
問:有兩個問題想問一下,第一, Access log 該怎麼使用,Access log 對報表統計或者什麼計算之類的,剛才聽到使用API,這是你們做二次開發處理使用者的命令嗎?
潘衛華:第一個問題你說Access log該怎麼使用,一個場景是做報表,我們公司是有Hive的系統來做的,當然以後我們這邊也去考慮,也可以提供報表的功能。另外主要服務於開發者,關於他發現問題,需要查某個來源IP,他呼叫了什麼URL,會查這個記錄的時候,必須訪問到Access log做快速查詢,也就是所謂的Ad-hoc查詢。
問:第二個問題,我看到你們四個階段,從消費、解析、壓縮到寫入,這四個階段,訊息會丟失什麼場景?
潘衛華:在寫HDFS的時候是最有可能發生失敗的地方,我們會進行重試,超過一定次數之後如果還是失敗,我們還是會落盤到本地,透過定時任務把處理失敗的資料會再重新寫到HDFS裡面去。
問:剛才只聽到只是Buffer重試,你前面好幾個步驟,比如說服務端重啟這些場景。
潘衛華:這些就要考慮到使用者到底對資料的可靠性要求有多高,或者說不同的應用場景有不同的設計方法。如果資料要求非常高,比如說交易資料,可能就要單獨做一個 Kafka 消費模型,最終寫入到 HDFS,才能確定這個資料寫入成功了,這種非常高的可靠性要求,對效能也會損失很多。對於日誌查詢這種應用,我們認為它的場景並不需要那麼高的可靠性要求,所以做得簡單一點。當真的出現丟失問題的時候,我們有需要的話還是可以從kafka再重新拉取資料補回。
問:講師您好,請教一下,目前 Access log 是運用在公司包括各個應用服務的產品嗎?比如各個業務做應用,它的日誌收集是會用到 Access log 去做收集嗎?
潘衛華:主要是 Access log 或者有前面所說幾個特徵的日誌場景,我們都可以幫他收集,我們公司都這幾種,主要是外網的網端,內網我們有一些閘道器,可以作用防火牆或者流量的分發,還有微服務元件會有 Access log。
問:其實格式大家已經統一了?
潘衛華:對,這幾種元件的日誌都有各自統一格式的。
問:如果業務性開發應用,這些理論上沒有辦法,除非你們提供了一個結構格式給他們。
潘衛華:對於Nginx Access Log,主要需要運維去做推動。如果不統一,我們也可以在寫過很多規則去適配它來做,但最好方法就是統一。
問:當時在選型儲存的時候,你這邊選可是 HDFS,其實是不是可以用時序資料庫,你要儲存半年或者三個月這個要做什麼考慮?
潘衛華:首先時序資料庫TSDB,適合用來放指標類的東西,主要用來看趨勢線的,日誌這種放進去是不合適的。
問:老師您好,我想問一下剛剛說收集那一塊,它的效能有沒有對比過像 Flume這種,他們兩種對比你覺得優勢在哪裡?
潘衛華:不同採集端的效能我們是對比過,Flume效能還不錯,但是前面說 Flume 是基於Java,對記憶體的消耗比較大,會佔用預期的記憶體,另外是二次開發複雜度,我們用GO二次開發比他那邊開發基於Flume開發還要快。
問:對於完備性有沒有對比過,收集會不會丟失,你把它抓取到了,會不會存在丟失的情況?
潘衛華:首先它會有記錄Offset,它讀了多少,它會記錄在檔案裡面,整個開發處理完之後會發給 Kafka,整個過程中間沒有發現丟失。
