

當年的我還是那麼風華正茂、幽默風趣…
言歸正傳,本次使用的是
selenium模擬登入+BeautifulSoup4爬取資料+wordcloud生成詞雲圖
BeautifulSoup安裝
pip install beautifulsoup4
下表列出了主要的解析器,以及它們的優缺點:

selenium模擬登入
使用selenium模擬登入QQ空間,安裝pip install selenium
我用的是chrom瀏覽器,webdriver.Chrome(),獲取Chrome瀏覽器的驅動。
這裡還需要下載安裝對應瀏覽器的驅動,否則在執行指令碼時,會提示
chromedriver executable needs to be in PATH錯誤,用的是mac,網上找的一篇下載驅動的文章,https://blog.csdn.net/zxy987872674/article/details/53082896
同理window的也一樣,下載對應的驅動,解壓後,將下載的**.exe 放到Python的安裝目錄,例如 D:\python 。 同時需要將Python的安裝目錄新增到系統環境變數裡。
qq登入頁http://i.qq.com,利用webdriver開啟qq空間的登入頁面
driver = webdriver.Chrome()
driver.get(“http://i.qq.com”)
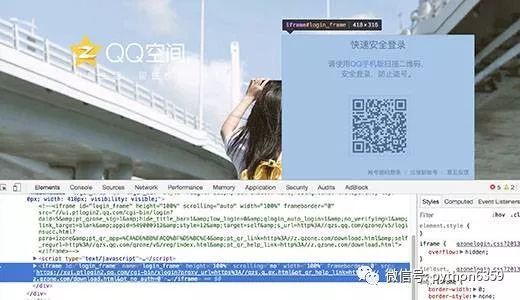
開啟之後右擊檢查檢視頁面元素,發現帳號密碼登入在login_frame裡,先定位到所在的frame,driver.switch_to.frame(“login_frame”) ,再自動點選 帳號密碼登入 按鈕,自動輸入帳號密碼登入,並且開啟說說頁面,詳細程式碼如下

這個時候可以看到已經開啟了qq說說的頁面了,註意 部分空間開啟之後會出現一個提示框,需要先模擬點選事件關閉這個提示框


同時因為說說內容是動態載入的,需要自動下拉捲軸,載入出全部的內容,再模擬點選 下一頁 載入內容。
BeautifulSoup爬取說說
F12檢視內容,可以找到說說在feed_wrap這個
- 裡面的
- 標簽陣列裡面,具體每條說說內容在
class=”bd”的
標簽中。


至此QQ說說已經爬取下來,並且儲存在了qq_word檔案裡
詞雲圖
使用wordcloud包生成詞雲圖,pip install wordcloud
這裡還可以使用jieba分詞,我並沒有使用,因為我覺得qq說說的句子讀起來才有點感覺,個人喜好,用jieba分詞可以看到說說高頻次的一些詞語。
設定下wordcloud的一些屬性,註意 這裡要設定font_path屬性,否則漢字會出現亂碼。
這裡還有個要提醒的是,如果使用了虛擬環境的,不要在虛擬環境下執行以下指令碼,否則可能會報錯

我就遇到了這種情況,deactivate 退出了虛擬環境再跑的
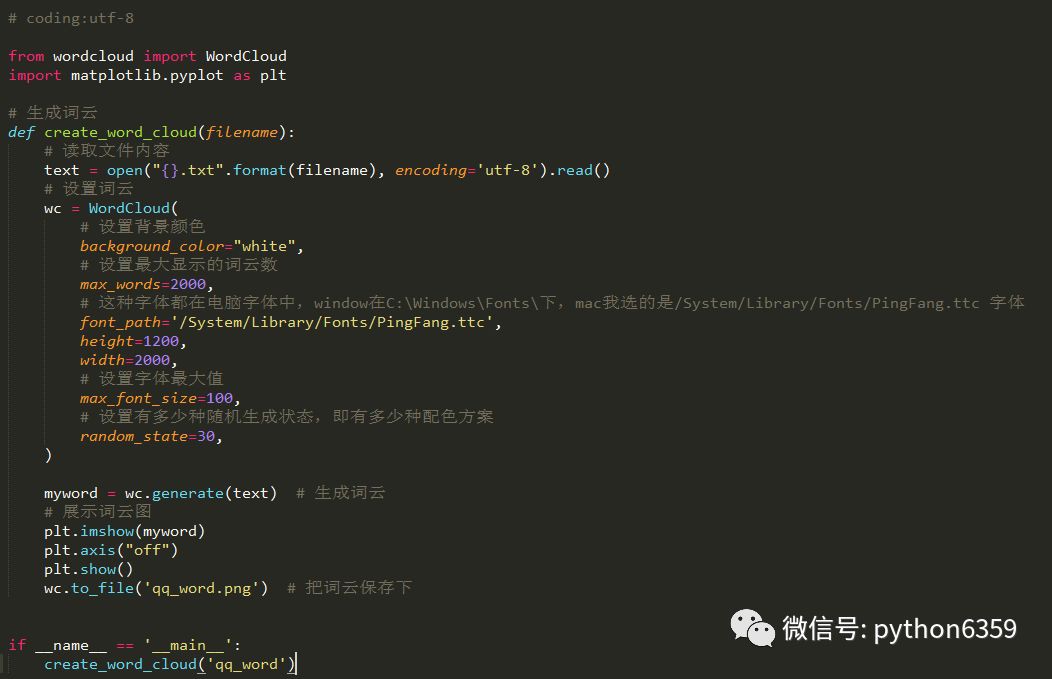
至此,爬取qq說說內容,並生成詞雲圖。

作者:程式猿tx
源自:
https://juejin.im/post/5af7ef69f265da0b9b0769cb
宣告:文章著作權歸作者所有,如有侵權,請聯絡小編刪除
