作者:李平
來自:https://www.cnblogs.com/leefreeman/p/8286550.html
1、背景
對於資料庫系統來說在多使用者併發條件下提高併發性的同時又要保證資料的一致性一直是資料庫系統追求的標的,既要滿足大量併發訪問的需求又必須保證在此條件下資料的安全,為了滿足這一標的大多數資料庫透過鎖和事務機制來實現,MySQL資料庫也不例外。儘管如此我們仍然會在業務開發過程中遇到各種各樣的疑難問題,本文將以案例的方式演示常見的併發問題並分析解決思路。
2、表鎖導致的慢查詢的問題
首先我們看一個簡單案例,根據ID查詢一條使用者資訊:
mysql> select * from user where id=6;
這個表的記錄總數為3條,但卻執行了13秒。

出現這種問題我們首先想到的是看看當前MySQL行程狀態:

從行程上可以看出select陳述句是在等待一個表鎖,那麼這個表鎖又是什麼查詢產生的呢?這個結果中並沒有顯示直接的關聯關係,但我們可以推測多半是那條update陳述句產生的(因為行程中沒有其他可疑的SQL),為了印證我們的猜測,先檢查一下user表結構:

果然user表使用了MyISAM儲存引擎,MyISAM在執行操作前會產生表鎖,操作完成再自動解鎖。如果操作是寫操作,則表鎖型別為寫鎖,如果操作是讀操作則表鎖型別為讀鎖。正如和你理解的一樣寫鎖將阻塞其他操作(包括讀和寫),這使得所有操作變為序列;而讀鎖情況下讀-讀操作可以並行,但讀-寫操作仍然是序列。以下示例演示了顯式指定了表鎖(讀鎖),讀-讀並行,讀-寫序列的情況。
顯式開啟/關閉表鎖,使用lock table user read/write; unlock tables;
session1:

session2:
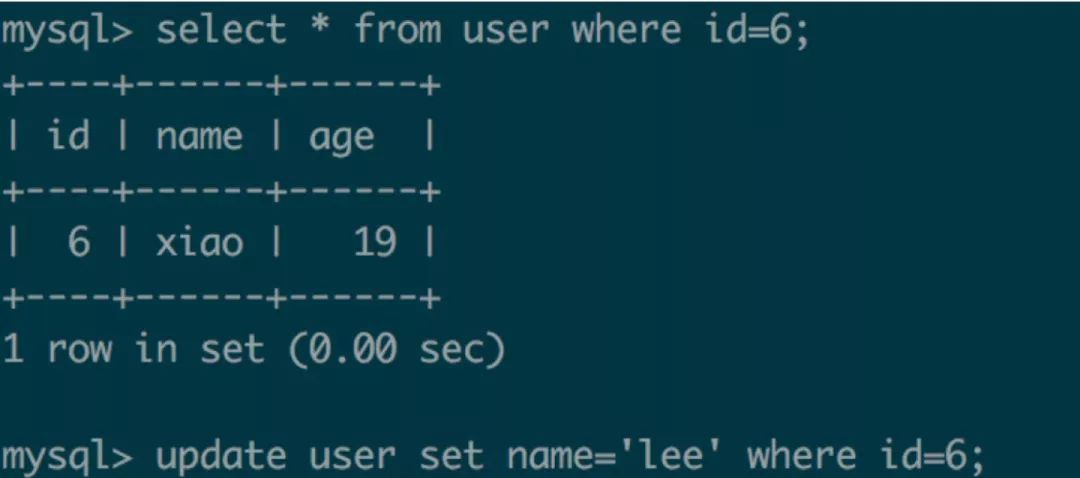
可以看到會話1啟用表鎖(讀鎖)執行讀操作,這時會話2可以並行執行讀操作,但寫操作被阻塞。接著看:
session1:
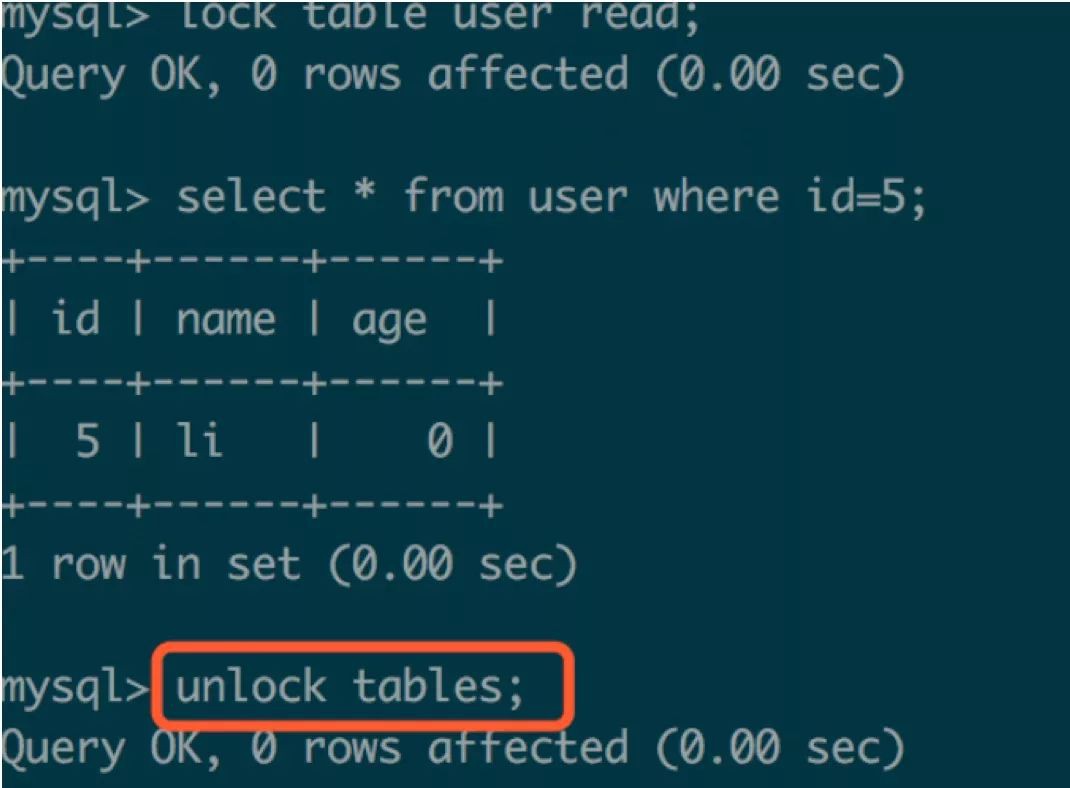
session2:

當session1執行解鎖後,seesion2則立刻開始執行寫操作,即讀-寫序列。
總結:
到此我們把問題的原因基本分析清楚,總結一下——MyISAM儲存引擎執行操作時會產生表鎖,將影響其他使用者對該表的操作,如果表鎖是寫鎖,則會導致其他使用者操作序列,如果是讀鎖則其他使用者的讀操作可以並行。所以有時我們遇到某個簡單的查詢花了很長時間,看看是不是這種情況。
解決辦法:
1)儘量不用MyISAM儲存引擎,在MySQL8.0版本中已經去掉了所有的MyISAM儲存引擎的表,推薦使用InnoDB儲存引擎。
2)如果一定要用MyISAM儲存引擎,減少寫操作的時間;
3、線上修改表結構有哪些風險?
如果有一天業務系統需要增大一個欄位長度,能否線上上直接修改呢?在回答這個問題前,我們先來看一個案例:
![]()
以上陳述句嘗試修改user表的name欄位長度,陳述句被阻塞。按照慣例,我們檢查一下當前行程:
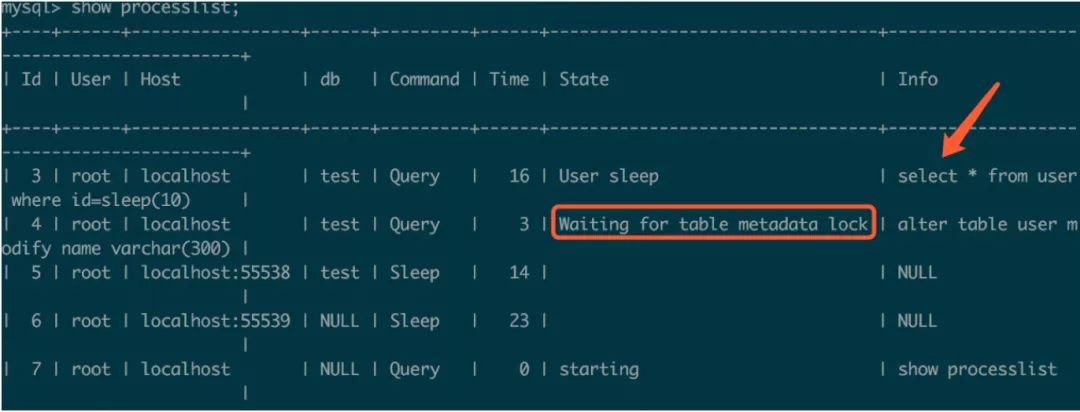
從行程可以看出alter陳述句在等待一個元資料鎖,而這個元資料鎖很可能是上面這條select陳述句引起的,事實正是如此。在執行DML(select、update、delete、insert)操作時,會對錶增加一個元資料鎖,這個元資料鎖是為了保證在查詢期間表結構不會被修改,因此上面的alter陳述句會被阻塞。那麼如果執行順序相反,先執行alter陳述句,再執行DML陳述句呢?DML陳述句會被阻塞嗎?例如我正線上上環境修改表結構,線上的DML陳述句會被阻塞嗎?答案是:不確定。
在MySQL5.6開始提供了online ddl功能,允許一些DDL陳述句和DML陳述句併發,在當前5.7版本對online ddl又有了增強,這使得大部分DDL操作可以線上進行。詳見:https://dev.mysql.com/doc/refman/5.7/en/innodb-create-index-overview.html
所以對於特定場景執行DDL過程中,DML是否會被阻塞需要視場景而定。
總結:透過這個例子我們對元資料鎖和online ddl有了一個基本的認識,如果我們在業務開發過程中有線上修改表結構的需求,可以參考以下方案:
1. 儘量在業務量小的時間段進行;
2. 檢視官方檔案,確認要做的表修改可以和DML併發,不會阻塞線上業務;
3. 推薦使用percona公司的pt-online-schema-change工具,該工具被官方的online ddl更為強大,它的基本原理是:透過insert… select…陳述句進行一次全量複製,透過觸發器記錄表結構變更過程中產生的增量,從而達到表結構變更的目的。
例如要對A表進行變更,主要步驟為:
建立目的表結構的空表,A_new;
在A表上建立觸發器,包括增、刪、改觸發器;
透過insert…select…limit N 陳述句分片複製資料到目的表
Copy完成後,將A_new表rename到A表。
4、一個死鎖問題的分析
線上上環境下死鎖的問題偶有發生,死鎖是因為兩個或多個事務相互等待對方釋放鎖,導致事務永遠無法終止的情況。為了分析問題,我們下麵將模擬一個簡單死鎖的情況,然後從中總結出一些分析思路。
演示環境:MySQL5.7.20 事務隔離級別:RR
表user:
|
CREATE TABLE `user` ( |
|---|
下麵演示事務1、事務2工作的情況:
|
|
事務1 |
事務2 |
事務監控 |
|---|---|---|---|
| T1 |
begin; Query OK, 0 rows affected (0.00 sec) |
begin; Query OK, 0 rows affected (0.00 sec) |
|
| T2 |
select * from user where id=3 for update; +—-+——+——+ |
select * from user where id=4 for update; +—-+——+——+ |
select * from information_schema.INNODB_TRX; 透過查詢元資料庫innodb事務表,監控到當前執行事務數為2,即事務1、事務2。 |
| T3 |
update user set name=’haha’ where id=4; 因為id=4的記錄已被事務2加上行鎖,該陳述句將阻塞 |
監控到當前執行事務數為2。 | |
| T4 | 阻塞狀態 |
update user set name=’hehe’ where id=3; ERROR 1213 (40001): Deadlock found when trying to get lock; try restarting transaction id=3的記錄已被事務1加上行鎖,而本事務持有id=4的記錄行鎖,此時InnoDB儲存引擎檢查出死鎖,本事務被回滾。 |
事務2被回滾,事務1仍在執行中,監控當前執行事務數為1。 |
| T5 |
Query OK, 1 row affected (20.91 sec) 由於事務2被回滾,原來阻塞的update陳述句被繼續執行。 |
監控當前執行事務數為1。 | |
| T6 |
commit; Query OK, 0 rows affected (0.00 sec) |
事務1已提交、事務2已回滾,監控當前執行事務數為0。 |
這是一個簡單的死鎖場景,事務1、事務2彼此等待對方釋放鎖,InnoDB儲存引擎檢測到死鎖發生,讓事務2回滾,這使得事務1不再等待事務B的鎖,從而能夠繼續執行。那麼InnoDB儲存引擎是如何檢測到死鎖的呢?為了弄明白這個問題,我們先檢查此時InnoDB的狀態:
show engine innodb statusG
————————
LATEST DETECTED DEADLOCK
————————
2018-01-14 12:17:13 0x70000f1cc000
*** (1) TRANSACTION:
TRANSACTION 5120, ACTIVE 17 sec starting index read
mysql tables in use 1, locked 1
LOCK WAIT 3 lock struct(s), heap size 1136, 2 row lock(s)
MySQL thread id 10, OS thread handle 123145556967424, query id 2764 localhost root updating
update user set name=’haha’ where id=4
*** (1) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 94 page no 3 n bits 80 index PRIMARY of table `test`.`user` trx id 5120 lock_mode X locks rec but not gap waiting
Record lock, heap no 5 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
0: len 4; hex 80000004; asc ;;
1: len 6; hex 0000000013fa; asc ;;
2: len 7; hex 520000060129a6; asc R ) ;;
3: len 4; hex 68616861; asc haha;;
4: len 4; hex 80000015; asc ;;
*** (2) TRANSACTION:
TRANSACTION 5121, ACTIVE 12 sec starting index read
mysql tables in use 1, locked 1
3 lock struct(s), heap size 1136, 2 row lock(s)
MySQL thread id 11, OS thread handle 123145555853312, query id 2765 localhost root updating
update user set name=’hehe’ where id=3
*** (2) HOLDS THE LOCK(S):
RECORD LOCKS space id 94 page no 3 n bits 80 index PRIMARY of table `test`.`user` trx id 5121 lock_mode X locks rec but not gap
Record lock, heap no 5 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
0: len 4; hex 80000004; asc ;;
1: len 6; hex 0000000013fa; asc ;;
2: len 7; hex 520000060129a6; asc R ) ;;
3: len 4; hex 68616861; asc haha;;
4: len 4; hex 80000015; asc ;;
*** (2) WAITING FOR THIS LOCK TO BE GRANTED:
RECORD LOCKS space id 94 page no 3 n bits 80 index PRIMARY of table `test`.`user` trx id 5121 lock_mode X locks rec but not gap waiting
Record lock, heap no 7 PHYSICAL RECORD: n_fields 5; compact format; info bits 0
0: len 4; hex 80000003; asc ;;
1: len 6; hex 0000000013fe; asc ;;
2: len 7; hex 5500000156012f; asc U V /;;
3: len 4; hex 68656865; asc hehe;;
4: len 4; hex 80000014; asc ;;
*** WE ROLL BACK TRANSACTION (2)
InnoDB狀態有很多指標,這裡我們擷取死鎖相關的資訊,可以看出InnoDB可以輸出最近出現的死鎖資訊,其實很多死鎖監控工具也是基於此功能開發的。
在死鎖資訊中,顯示了兩個事務等待鎖的相關資訊(藍色代表事務1、綠色代表事務2),重點關註:WAITING FOR THIS LOCK TO BE GRANTED和HOLDS THE LOCK(S)。
WAITING FOR THIS LOCK TO BE GRANTED表示當前事務正在等待的鎖資訊,從輸出結果看出事務1正在等待heap no為5的行鎖,事務2正在等待 heap no為7的行鎖;
HOLDS THE LOCK(S):表示當前事務持有的鎖資訊,從輸出結果看出事務2持有heap no為5行鎖。
從輸出結果看出,最後InnoDB回滾了事務2。
那麼InnoDB是如何檢查出死鎖的呢?
我們想到最簡單方法是假如一個事務正在等待一個鎖,如果等待時間超過了設定的閾值,那麼該事務操作失敗,這就避免了多個事務彼此長等待的情況。引數innodb_lock_wait_timeout正是用來設定這個鎖等待時間的。
如果按照這個方法,解決死鎖是需要時間的(即等待超過innodb_lock_wait_timeout設定的閾值),這種方法稍顯被動而且影響系統效能,InnoDB儲存引擎提供一個更好的演演算法來解決死鎖問題,wait-for graph演演算法。簡單的說,當出現多個事務開始彼此等待時,啟用wait-for graph演演算法,該演演算法判定為死鎖後立即回滾其中一個事務,死鎖被解除。該方法的好處是:檢查更為主動,等待時間短。
下麵是wait-for graph演演算法的基本原理:
為了便於理解,我們把死鎖看做4輛車彼此阻塞的場景:
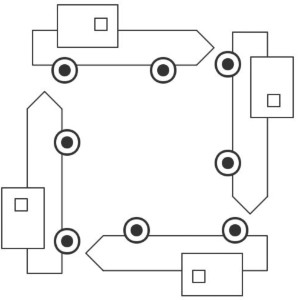

4輛車看做4個事務,彼此等待對方的鎖,造成死鎖。wait-for graph演演算法原理是把事務作為節點,事務之間的鎖等待關係,用有向邊表示,例如事務A等待事務B的鎖,就從節點A畫一條有向邊到節點B,這樣如果A、B、C、D構成的有向圖,形成了環,則判斷為死鎖。這就是wait-for graph演演算法的基本原理。
總結:
1. 如果我們業務開發中出現死鎖如何檢查出?剛才已經介紹了透過監控InnoDB狀態可以得出,你可以做一個小工具把死鎖的記錄收集起來,便於事後檢視。
2. 如果出現死鎖,業務系統應該如何應對?從上文我們可以看到當InnoDB檢查出死鎖後,對客戶端報出一個Deadlock found when trying to get lock; try restarting transaction資訊,並且回滾該事務,應用端需要針對該資訊,做事務重啟的工作,並儲存現場日誌事後做進一步分析,避免下次死鎖的產生。
5、鎖等待問題的分析
在業務開發中死鎖的出現機率較小,但鎖等待出現的機率較大,鎖等待是因為一個事務長時間佔用鎖資源,而其他事務一直等待前個事務釋放鎖。
|
|
事務1 |
事務2 |
事務監控 |
|---|---|---|---|
| T1 |
begin; Query OK, 0 rows affected (0.00 sec) |
begin; Query OK, 0 rows affected (0.00 sec) |
|
| T2 |
select * from user where id=3 for update; +—-+——+——+ |
其他查詢操作 |
select * from information_schema.INNODB_TRX; 透過查詢元資料庫innodb事務表,監控到當前執行事務數為2,即事務1、事務2。 |
| T3 | 其他查詢操作 |
update user set name=’hehe’ where id=3; 因為id=3的記錄被事務1加上行鎖,所以該陳述句將阻塞(即鎖等待) |
監控到當前執行事務數為2。 |
| T4 | 其他查詢操作 |
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction 鎖等待時間超過閾值,操作失敗。註意:此時事務2並沒有回滾。 |
監控到當前執行事務數為2。 |
| T5 | commit; | 事務1已提交,事務2未提交,監控到當前執行事務數為1。 |
從上述可知事務1長時間持有id=3的行鎖,事務2產生鎖等待,等待時間超過innodb_lock_wait_timeout後操作中斷,但事務並沒有回滾。如果我們業務開發中遇到鎖等待,不僅會影響效能,還會給你的業務流程提出挑戰,因為你的業務端需要對鎖等待的情況做適應的邏輯處理,是重試操作還是回滾事務。
在MySQL元資料表中有對事務、鎖等待的資訊進行收集,例如information_schema資料庫下的INNODB_LOCKS、INNODB_TRX、INNODB_LOCK_WAITS,你可以透過這些表觀察你的業務系統鎖等待的情況。你也可以用一下陳述句方便的查詢事務和鎖等待的關聯關係:
| SELECT r.trx_id waiting_trx_id, r.trx_mysql_thread_id waiting_thread, r.trx_query wating_query, b.trx_id blocking_trx_id, b.trx_mysql_thread_id blocking_thread, b.trx_query blocking_query FROM information_schema.innodb_lock_waits w INNER JOIN information_schema.innodb_trx b ON b.trx_id = w.blocking_trx_id INNER JOIN information_schema.innodb_trx r ON r.trx_id = w.requesting_trx_id; |
|---|
結果:
waiting_trx_id: 5132
waiting_thread: 11
wating_query: update user set name=’hehe’ where id=3
blocking_trx_id: 5133
blocking_thread: 10
blocking_query: NULL
總結:
1. 請對你的業務系統做鎖等待的監控,這有助於你瞭解當前資料庫鎖情況,以及為你最佳化業務程式提供幫助;
2. 業務系統中應該對鎖等待超時的情況做合適的邏輯判斷。
6、小結
本文透過幾個簡單的示例介紹了我們常用的幾種MySQL併發問題,並嘗試得出針對這些問題我們排查的思路。文中涉及事務、表鎖、元資料鎖、行鎖,但引起併發問題的遠遠不止這些,例如還有事務隔離級別、GAP鎖等。真實的併發問題可能多而複雜,但排查思路和方法卻是可以復用,在本文中我們使用了show processlist;show engine innodb status;以及查詢元資料表的方法來排查發現問題,如果問題涉及到了複製,還需要藉助master/slave監控來協助。
參考資料:
-
薑承堯《InnoDB儲存引擎》
-
李宏哲 楊挺 《MySQL排查指南》
-
何登成 http://hedengcheng.com
●編號324,輸入編號直達本文
●輸入m獲取到文章目錄

Python程式設計
更多推薦《18個技術類公眾微信》
涵蓋:程式人生、演演算法與資料結構、駭客技術與網路安全、大資料技術、前端開發、Java、Python、Web開發、安卓開發、iOS開發、C/C++、.NET、Linux、資料庫、運維等。
