
在碎片化閱讀充斥眼球的時代,越來越少的人會去關註每篇論文背後的探索和思考。
在這個欄目裡,你會快速 get 每篇精選論文的亮點和痛點,時刻緊跟 AI 前沿成果。
點選本文底部的「閱讀原文」即刻加入社群,檢視更多最新論文推薦。
本期推薦的論文筆記來自 PaperWeekly 社群使用者 @jamiechoi。本文主要討論自適應的註意力機制在 Image Caption 中的應用。作者提出了帶有視覺標記的自適應 Attention 模型,在每一個 time step,由模型決定更依賴於影象還是視覺標記。
關於作者:蔡文傑,華南理工大學碩士生,研究方向為Image Caption。
■ 論文 | Knowing When to Look: Adaptive Attention via A Visual Sentinel for Image Captioning
■ 連結 | www.paperweekly.site/papers/219
■ 原始碼 | github.com/jiasenlu/AdaptiveAttention
Introduction
目前大多數的基於 Attention 機制的 Image Captioning 模型採用的都是 encoder-decoder 框架。然而在 decode 的時候,decoder 應該對不同的詞有不同的 Attention 策略。例如,“the”、“of”等詞,或者是跟在“cell”後面的“phone”等組合詞,這類詞叫做非視覺詞(Non-visual Word),更多依賴的是語意資訊而不是視覺資訊。而且,在生成 caption 的過程中,非視覺詞的梯度會誤導或者降低視覺資訊的有效性。
因此,本文提出了帶有視覺標記的自適應 Attention 模型(Adative Attention Model with a Visual Sentinel),在每一個 time step,模型決定更依賴於影象還是 Visual Sentinel。其中,visual sentinel 存放了 decoder 已經知道的資訊。
本文的貢獻在於:
-
提出了帶有視覺標記的自適應 Attention 模型
-
提出了新的 Spatial Attention 機制
-
提出了 LSTM 的擴充套件,在 hidden state 以外加入了一個額外的 Visual Sentinel Vector
Method
Spatial Attention Model
文章介紹了普通的 encoder-decoder 框架,這裡不再贅述。但文章定義了 context vector ct,對於沒有 attention 機制的模型,ct 就是影象經過 CNN 後提取出的 feature map,是不變的;而對於有 attention 機制的模型,基於 hidden state,decoder 會關註影象的不同區域,ct 就是該區域經過 CNN 後提取出的 feature map。
文章對 ct 的定義如下:

其中 g 是 attention function,V=[v1,…,vk] 代表 k 個區域的影象 feature,ht 是 t 時刻 RNN 的 hidden state。 由此可以得到 k 個區域的 attention 分佈 αt:
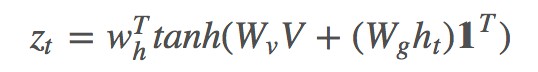
這裡把 V 與 ht 相加,而有些論文則使用一個雙線性矩陣來連線它們。

其中 是所有元素為 1 的向量,目的是讓
是所有元素為 1 的向量,目的是讓 相乘得到 k*k 大小的矩陣。最終本文的 ct 為:
相乘得到 k*k 大小的矩陣。最終本文的 ct 為:

與 show, attend and tell [1] 使用 ht−1 的做法不同,本文使用的是 ht。結構如下:

作者認為 ct 可以看作 ht 的殘差連線,可以在預測下一個詞時降低不確定性或者提供情報。(不是應該做一個實驗驗證使用 ht 和 ht−1 的差別?)並且發現,這種 Spatial Attention 方式比其他模型表現更好。
Adaptive Attention Model
decoder 儲存了長時和短時的視覺和語意資訊,而 Visual Sentinel st 作為從裡面提取的一個新的元件,用來擴充套件上述的 Spatial Attention Model,就得到了 Adaptive Attention Model。
具體的擴充套件方式就是在原有的 LSTM 基礎上加了兩個公式:

其中 xt 是 LSTM 的輸入,mt 是 memory cell(有些論文裡用 ct 表示)。
這裡的 gt 叫 sentinel gate,公式形式類似於 LSTM 中的 input gate, forget gate, output gate,決定了模型到底關註影象還是 visual sentinel;而 st 公式的構造與 LSTM 中的 ht=ot⊙tanh(ct) 類似。
Adaptive Attention Model 中的 Context Vector:

βt∈[0,1] 可以視為真正意義上的 sentinel gate,控制模型關註 visual sentinel 和 ct 的程度。與此同時,Spatial Attention 部分 k 個區域的 attention 分佈 αt 也被擴充套件成了 αt^,做法是在 zt 後面拼接上一個元素:

擴充套件後的 αt^ 有 k+1 個元素,而 βt=αt^[k+1]。(CVPR 和 arXiv 版本的原文都寫的是 βt=αt[k+1],我在 Github 上問了作者,這確實是個筆誤 [2])。
這裡的 Wg 與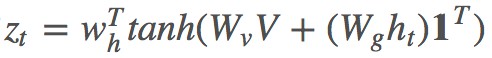 中的 Wg 是相同的(為什麼這樣做?Wh 也一樣嗎?作者在這裡沒有提到,在後續論文 [3] 裡的公式 (9) 提到了)。
中的 Wg 是相同的(為什麼這樣做?Wh 也一樣嗎?作者在這裡沒有提到,在後續論文 [3] 裡的公式 (9) 提到了)。
上述公式可以簡化為:

最終單詞的機率分佈:

具體架構如下:
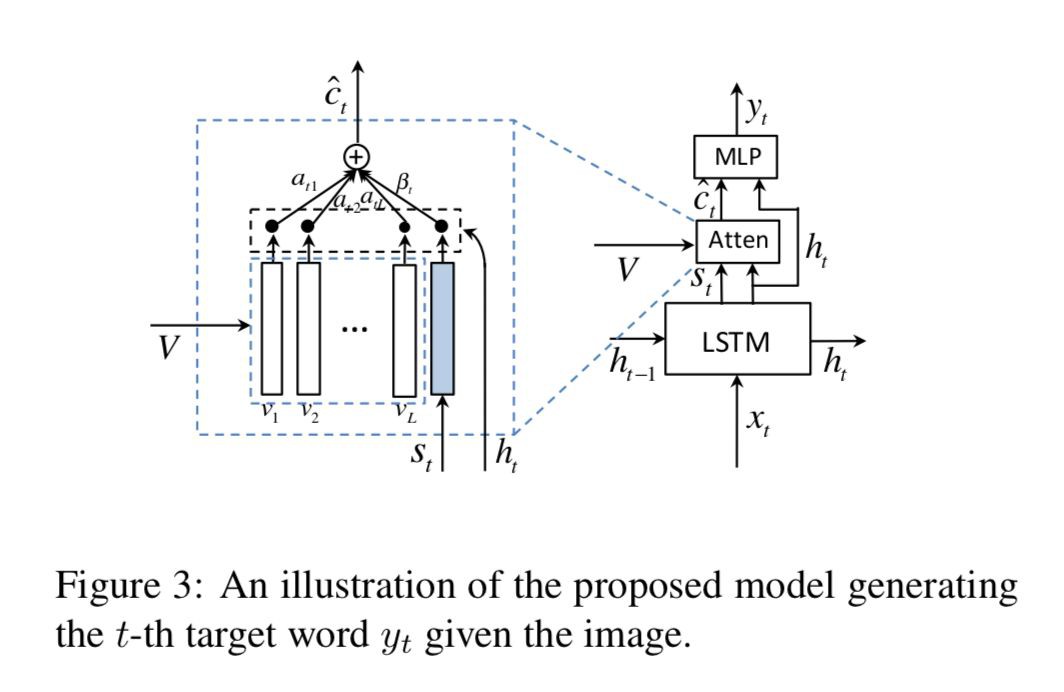
Implementation Details
文章選擇了 ResNet 的最後一層摺積層的特徵來表示影象,維度是 2048x7x7,並使用 來表示 k 個區域性影象特徵,而全域性影象特徵則是區域性特徵的平均:
來表示 k 個區域性影象特徵,而全域性影象特徵則是區域性特徵的平均:

區域性影象特徵需要經過轉換:

最終全域性影象特徵將與 word embedding 拼接在一起成為 LSTM 的輸入:xt=[wt;vg] 區域性影象特徵則用在了 attention 部分。
Experiment
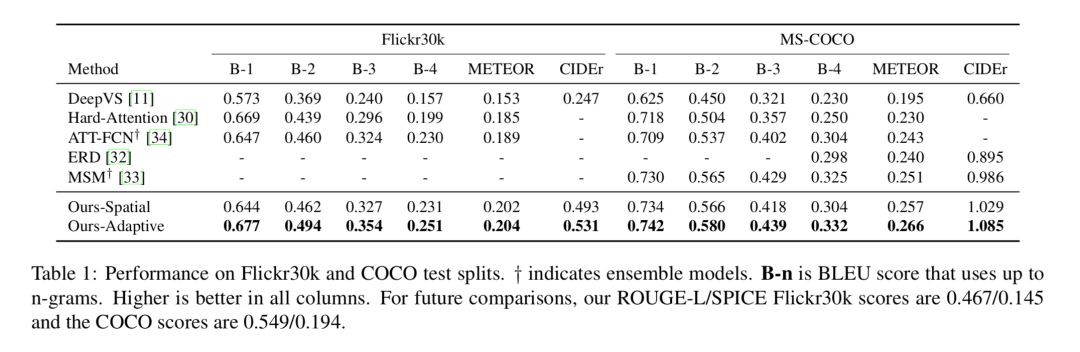
Table 1 在 test splits 上對比了在 Flickr30k 和 MSCOCO 資料集上模型與其他模型的表現,可以看到,模型的 Spatial Attention 部分就已經比其他模型表現好了,而加入了 Adaptive Attention 部分以後表現更加出色。

Table 2 在 COCO server 上對比了模型與其他模型的表現可以看到,Adaptive Attention 模型(emsemble後)的表現是當時 SOTA 的結果。

Fig 4 是 Spatial Attention的權重 α 的視覺化結果,前兩列是成功的樣本,最後一列是失敗的樣本。模型進行 attention 的區域基本都是合理的,只是可能對一些物體的材質判斷失誤。
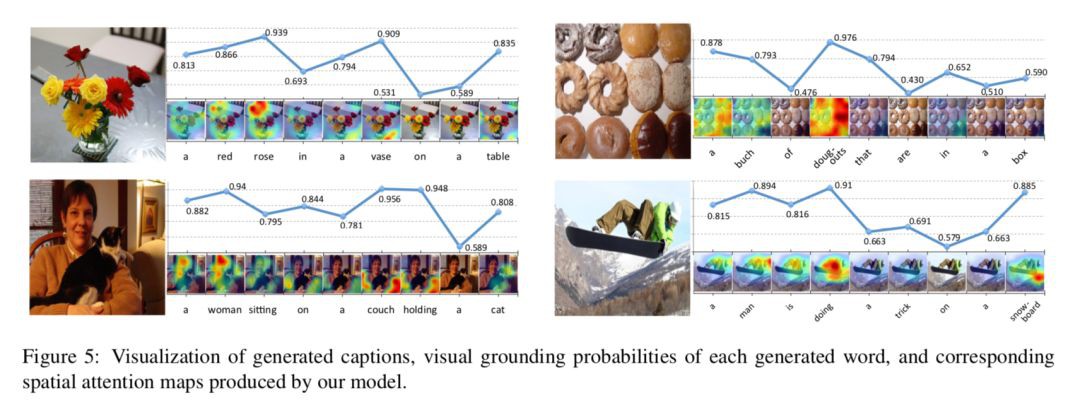
Fig 5 主要是 sentinel gate 1−β 的視覺化,對於視覺詞,模型給出的機率較大,即更傾向於關註影象特徵 ct,對於非視覺詞的機率則比較小。同時,同一個詞在不同的背景關係中的機率也是不一樣的。如”a”,在一開始的機率較高,因為開始時沒有任何的語意資訊可以依賴、以及需要確定單複數。
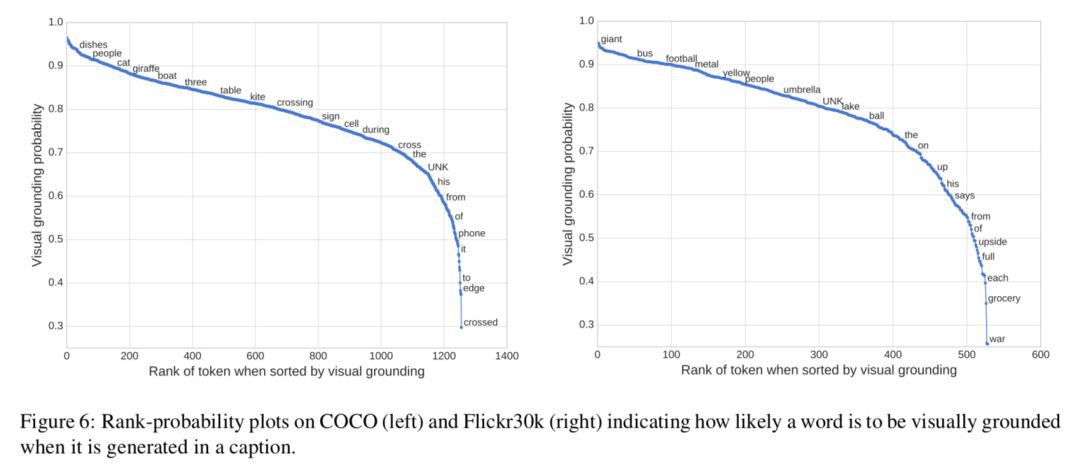
Fig 6 對 COCO 和 Flickr30k 中詞典中的詞被認為是視覺詞的平均機率進行了排序,來看看模型能否分辨出視覺詞與非視覺詞,兩個資料集間的相關性為 0.483。其中:
1. 對於一些實際上是視覺詞,但是與其他詞有很大關聯性的詞,模型也會把它視為非視覺詞,如”phone”一般都跟在”cell”後面;
2. 不同資料集上不同的詞的機率不一樣,如”UNK”,可能是由於訓練資料分佈的不同;
3. 對於一些有相近意義的同源詞,如”crossing”, “cross”, “crossed”,他們的機率卻相差很大。(為什麼?) 模型沒有依賴外部的語料資訊,完全是自動地發現這些趨勢。

Fig 11 顯示了使用弱監督方法生成的 bounding box 與真實 bounding box 的對比。本文是第一個使用這種方法來評估 image caption 的 attention 效果的。
具體生成方法是,對於某個單詞而言,先用 NLTK 將其對映到大類上,如“boy”, “girl”對映到 people。然後影象中 attention weight 小於閾值(每個單詞的閾值都不一樣)的部分就會被分割出來,取分割後的最大連通分量來生成 bounding box。
並計算生成的和真實 bounding box 的 IOU (intersection over union),對於 spatial attention 和 adaptive attention 模型,其平均定位準確率分別為 0.362 和 0.373。說明瞭,知道何時關註影象,也能讓模型更清楚到底要去關註影象的哪個部分。

Fig 7 顯示了 top 45 個 COCO 資料集中出現最頻繁的詞的定位準確性。對於一些體積較小的物體,其準確率是比較低的,這是因為 attention map 是從 7×7 的 feature map 中直接放大的,而 7×7 的 feature map 並不能很好地包含這些小物體的資訊。

Fig 8 顯示了單詞“of”在 spatial attention 和 adaptive attention 模型中的 attention map。如果沒有 visual sentinel,非視覺詞如“of”的 attention 就會高度集中在影象的邊緣部分,可能會在反向傳播時形成噪聲影響訓練。
總結
本文提出了 Adaptive Attention 機制,其模型公式都非常簡單,Adaptive Attention 部分增加的幾個變數也非常簡潔,但卻對模型的表現有了很大的提升。文章進行的詳盡的實驗又進一步驗證了 Adaptive Attention 的有效性,可謂非常巧妙。
相關連結
[1]. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
https://arxiv.org/abs/1502.03044
[2]. 筆誤
https://github.com/jiasenlu/AdaptiveAttention/issues/14
[3]. Neural Baby Talk
https://www.paperweekly.site/papers/1801
本文由 AI 學術社群 PaperWeekly 精選推薦,社群目前已改寫自然語言處理、計算機視覺、人工智慧、機器學習、資料挖掘和資訊檢索等研究方向,點選「閱讀原文」即刻加入社群!

點選標題檢視更多論文解讀:

▲ 戳我檢視招募詳情
 #作 者 招 募#
#作 者 招 募#
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 檢視作者部落格