摘自【工匠小豬豬的技術世界】 1.這是一個系列,有興趣的朋友可以持續關註 2.如果你有HikariCP使用上的問題,可以給我留言,我們一起溝通討論 3.希望大家可以提供我一些案例,我也希望可以支援你們做一些調優

本文是 【追光者系列】HikariCP詭異問題撥開迷霧推理破案實錄(上)的下半部分
直奔疑點
首先我直接懷疑是不是資料庫斷掉了連線,於是登上了資料庫查詢了資料庫引數,結果是沒毛病。
為了穩妥起見,我又諮詢了DBA,DBA說線下環境和線上環境引數一樣,並幫我看了,沒有任何問題。

為什麼我直接奔向這個疑點,因為《Solr權威指南》的作者蘭小偉大佬曾經和我分享過一個案例:他前段時間也遇到類似的問題,他用的是c3p0,碰到和我一樣的碰到一樣的exception,那個異常是伺服器主動關閉了連結,而客戶端還拿那個連結去操作,大佬加個testQuery,保持心跳即可解決。c3p0設定一個週期,是定時主動檢測的。
估計是mysql伺服器端連結快取時間設定的太短,伺服器端主動銷毀了連結,一般做法是客戶端連線池配置testQuery。 testQuery我覺得比較影響hikariCP的效能,所以我決定跟一下原始碼瞭解一下原理並定位問題。
撥開迷霧
按著上一篇的推測,我們在Hikari核心原始碼中打一些日誌記錄。
第一處,在com.zaxxer.hikari.pool.HikariPool#getConnection中增加IDEA log expression
public Connection getConnection(final long hardTimeout) throws SQLException {
suspendResumeLock.acquire();
final long startTime = currentTime();
try {
long timeout = hardTimeout;
PoolEntry poolEntry = null;
try {
do {
poolEntry = connectionBag.borrow(timeout, MILLISECONDS);
if (poolEntry == null) {
break; // We timed out... break and throw exception
}
final long now = currentTime();
if (poolEntry.isMarkedEvicted() || (elapsedMillis(poolEntry.lastAccessed, now) > ALIVE_BYPASS_WINDOW_MS && !isConnectionAlive(poolEntry.connection))) {
closeConnection(poolEntry, "(connection is evicted or dead)"); // Throw away the dead connection (passed max age or failed alive test)
timeout = hardTimeout - elapsedMillis(startTime);
}
else {
metricsTracker.recordBorrowStats(poolEntry, startTime);
return poolEntry.createProxyConnection(leakTask.schedule(poolEntry), now);
}
} while (timeout > 0L);
metricsTracker.recordBorrowTimeoutStats(startTime);
}
catch (InterruptedException e) {
if (poolEntry != null) {
poolEntry.recycle(startTime);
}
Thread.currentThread().interrupt();
throw new SQLException(poolName + " - Interrupted during connection acquisition", e);
}
}
finally {
suspendResumeLock.release();
}
throw createTimeoutException(startTime);
}
我們對於直接拋異常的程式碼的條件判斷入口處增加除錯資訊
if (poolEntry.isMarkedEvicted() || (elapsedMillis(poolEntry.lastAccessed, now) > ALIVE_BYPASS_WINDOW_MS && !isConnectionAlive(poolEntry.connection)))code> <code class="">String.format("Evicted: %s; enough time elapse: %s;poolEntrt: %s;", poolEntry.isMarkedEvicted(), elapsedMillis(poolEntry.lastAccessed, now) > ALIVE_BYPASS_WINDOW_MS,poolEntry);
第二處、在com.zaxxer.hikari.pool.HikariPool#softEvictConnection處增加除錯資訊
private boolean softEvictConnection(final PoolEntry poolEntry, final String reason, final boolean owner) {
poolEntry.markEvicted();
if (owner || connectionBag.reserve(poolEntry)) {
closeConnection(poolEntry, reason);
return true;
}
return false;
}
String.format("Scheduled soft eviction for connection %s is due; owner %s is;", poolEntry.connection,owner)
為什麼要打在softEvictConnection這裡呢?因為在createPoolEntry的時候註冊了一個延時任務,並透過poolEntry.setFutureEol設定到poolEntry中 softEvictConnection,首先標記markEvicted。然後如果是使用者自己呼叫的,則直接關閉連線;如果從connectionBag中標記不可borrow成功,則關閉連線。
這個定時任務是在每次createPoolEntry的時候,根據maxLifetime隨機設定一個variance,在maxLifetime – variance之後觸發evict。
/**
* Creating new poolEntry.
*/
private PoolEntry createPoolEntry() {
try {
final PoolEntry poolEntry = newPoolEntry();
final long maxLifetime = config.getMaxLifetime();
if (maxLifetime > 0) {
// variance up to 2.5% of the maxlifetime
final long variance = maxLifetime > 10_000 ? ThreadLocalRandom.current().nextLong( maxLifetime / 40 ) : 0;
final long lifetime = maxLifetime - variance;
poolEntry.setFutureEol(houseKeepingExecutorService.schedule(
() -> {
if (softEvictConnection(poolEntry, "(connection has passed maxLifetime)", false /* not owner */)) {
addBagItem(connectionBag.getWaitingThreadCount());
}
},
lifetime, MILLISECONDS));
}
return poolEntry;
}
catch (Exception e) {
if (poolState == POOL_NORMAL) {
LOGGER.debug("{} - Cannot acquire connection from data source", poolName, (e instanceof ConnectionSetupException ? e.getCause() : e));
}
return null;
}
}
守株待兔
做瞭如上處理之後我們就安心得等結果

很快來了一組資料,我們可以看到確實poolEntry.isMarkedEvicted()一直都是false,(elapsedMillis(poolEntry.lastAccessed, now) > ALIVEBYPASSWINDOW_MS這個判斷為true。
sharedlist 是 CopyOnWriteArrayList,每次getConnection都是陣列首
softEvictConnection這裡的資訊在20分鐘到了的時候也出現了
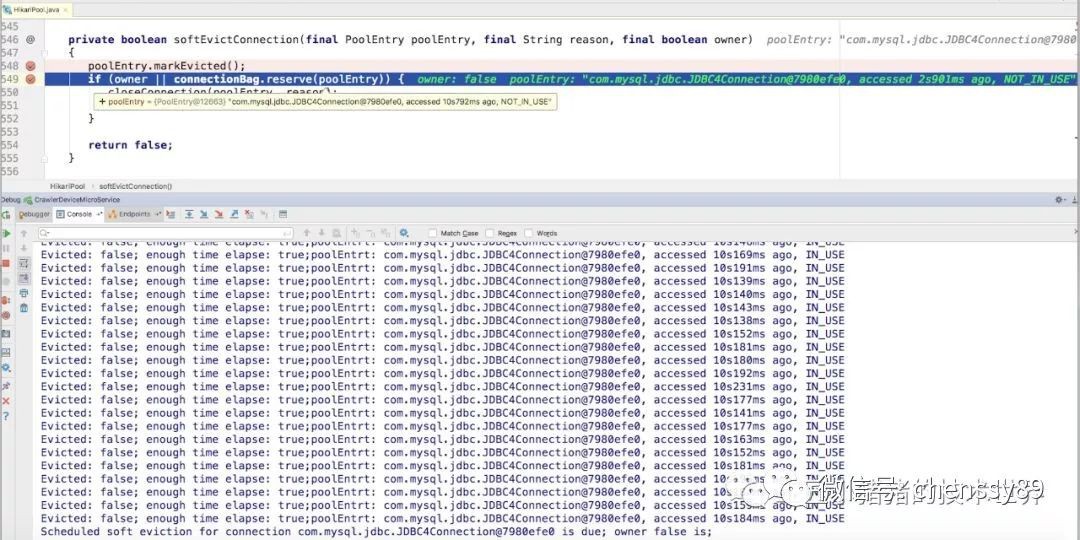
從這張圖我們可以看到,owner是false,第一個觸發定時任務的也正好是第一個連線。刪除的那個就是每次微服務健康檢測healthcheck連線用的那個。

我仔細數了一下,確實一共建立了十次SSL,也就是本次週期確實重新連了十次資料庫TCP連線。那麼問題來了,為什麼每次正好是8次或者9次異常日誌?
抽絲剝繭
定時任務的執行時間是多少?
這個定時任務是在每次createPoolEntry的時候,根據maxLifetime隨機設定一個variance,在maxLifetime – variance之後觸發evict。 maxLifetime我現在設定的是20分鐘,
// variance up to 2.5% of the maxlifetime
final long variance = maxLifetime > 10_000 ? ThreadLocalRandom.current().nextLong( maxLifetime / 40 ) : 0;
final long lifetime = maxLifetime - variance
按照20分鐘1200秒來算,這個evict的操作是1170秒左右,按理說離20分鐘差30秒左右。
但是透過觀察,好像第一個連線建立的時間比其他連線快 4 秒。

也就是說時間上被錯開了,本來10個連線是相近的時間close的,第一個連線先被定時器close了,其他連線是getconnection的時候close的,這樣就造成了一個迴圈。其他連線是getconnection的時候幾乎同時被關閉的,就是哪些warn日誌出現的時候。
這猜想和我debug得到的結果是一致的,第一個getConnection健康監測是被定時器close的,close之後立馬fillpool,所以warn的是小於10的。和我們看到的歷史資料一樣,8為主,也有9。

定時器close之後的那個新連線,會比其他的連線先進入定時器的排程,其他的9個被迴圈報錯關閉。

getconnection時報錯關閉的那些連線,跟被定時器關閉的連線的定時器時間錯開,如上圖所示,有兩個連線已經處於remove的狀態了。
9次是比較好解釋的,第一個連線是同步建立的,建構式裡呼叫checkFailFast會直接建一個連線,其他連線是 housekeeper裡非同步fillpool建立的。
做了一次測試,這一波果然打了9次日誌

那麼9次就可以這麼合理的解釋了。
8次的解釋應該就是如上圖所示2個已經被remove掉的可能性情況。
柳暗花明
這時小手一抖,netstat了一把


發現很快就closewait了,而closewait代表已經斷開了,基本不能再用了。其實就是被對方斷開了。
這時我又找了DBA,告訴他我得到的結論,DBA再次幫我確認之後,焦急的等待以後,螢幕那頭給我這麼一段回覆:

這時叫了一下配置中心的同學一起看了一下這個資料庫的地址,一共有5個配置連到了這個廢棄的proxy,和我們線上出問題的數目和應用基本一致!
配置中心的同學和DBA說這個proxy曾經批次幫業務方改過,有些業務方居然又改回去了。。。。這時業務方的同學也說話了,“難怪我navicate 在proxy上edit一個表要等半天。。stable環境就秒出”
真相大白
修改了這個廢棄的proxy改為真正的資料庫地址以後,第二天業務方的同學給了我們反饋:

圖左邊2個綠色箭頭,下麵那個是調整過配置的環境,上面是沒有調整的,調整過的今天已經沒有那個日誌了,那17.6%是正常的業務日誌。
END

