(點選上方公眾號,可快速關註)
來源:iceman1952,
blog.csdn.net/iceman1952/article/details/79957290
這是一篇譯文,原文(Every shard deserves a home)於2016-11-11釋出在elastic官方部落格。譯文稍有更改
https://www.elastic.co/blog/every-shard-deserves-a-home
閱讀提示
-
文章包含很多gif動圖,你可以使用“2345看圖王”檢視/暫停/回放gif動圖的每一幀
-
所有圖片都可以在新標簽頁中檢視大圖
-
“索引”有時作動詞,有時作名詞。例如“當索引第一個檔案到新的索引中時…”,第一個索引是動詞,第二個索引是名詞
-
術語及翻譯。有些術語不翻譯,直接使用英文原詞

文章正文開始
文中這些優秀的幻燈片來自於Core Elasticsearch: Operations課程,它們有助於解釋shard分配(shard allocation)的概念。我們推薦您參加完整課程以更好的理解這些概念,但,我會在此列出培訓的梗概
https://www.elastic.co/training/elasticsearch-operations-1
Shard分配(shard allocation)是把shard分配給節點的過程。 當初始恢復(initial recovery)、副分片分配(replica allocation)、重新平衡(rebalancing)或向叢集中加入/移除節點時就會發生shard分配。大部分時間,你無需掛心它,它在後臺由elasticsearch完成。如果你發現自己對這些細節感到好奇,這篇部落格將探索幾種不同場景下的shard分配
本文的叢集由4個節點組成,如下圖所示。文中的例子都使用此叢集完成

我們將改寫四種不同的場景
場景一、 建立索引

如上圖所示,這是最簡單的用例。我們建立了索引c,於是我們必須得為它分配新的shard。當索引第一個檔案到這個新的索引時,就會為它分配shard。上圖使用Kinaba中的Console外掛(之前稱為Sense)來執行灰色高亮的命令,索引一個檔案到索引中
對於索引c,我們正在建立一個primary shard和一個replica shard。master需要建立索引c,併為它分配2個shard,即一個primary shard和一個replica shard。叢集會透過以下方式來平衡叢集
-
考察叢集中每個節點所包含shard的平均數量,然後,盡可能使得每個節點上的此數字保持一致
-
基於叢集中每一個索引來做評估,使得shard跨所有索引而保持平衡
Shard分配過程中存在一些限制,分配決定器(allocation decider)在做分配時會遵從這些限制。分配決定器會評估叢集要做的每一個決定,並給出yes/no的回覆。分配決定器執行在master上。你可以認為是master給出修改提議,分配決定器則告知master此修改提議是否能透過。
關於此最簡單的一個例子就是,你不能把同一個shard的primary shard和replica shard放到同一個節點上
關於此還有一些其他例子
1. 基於Hot/Warm配置作分配過濾

這允許你把shard只放到具有特定屬性的節點上,分配決定器會根據Hot/Warm配置接受或拒絕叢集所作的決定。這是使用者決定直接控制分配決定器的例子
2. 磁碟使用情況分配器(Disk usage allocator)

master監控叢集中磁碟的使用情況,並根據高水位/低水位閾值控制shard分配(見下麵的:“場景二、 是時候移動shard了”)
3. 抑制(Throttles)

這意味著,理論上我們可以把shard分配到某節點,但,此節點上有太多正在進行中的恢復(recovery)。為了保護節點並且也允許恢復進行,分配決定器讓叢集進行等待,然後在下一個迭代中再重試把shard分配給同一個節點
Shard初始化
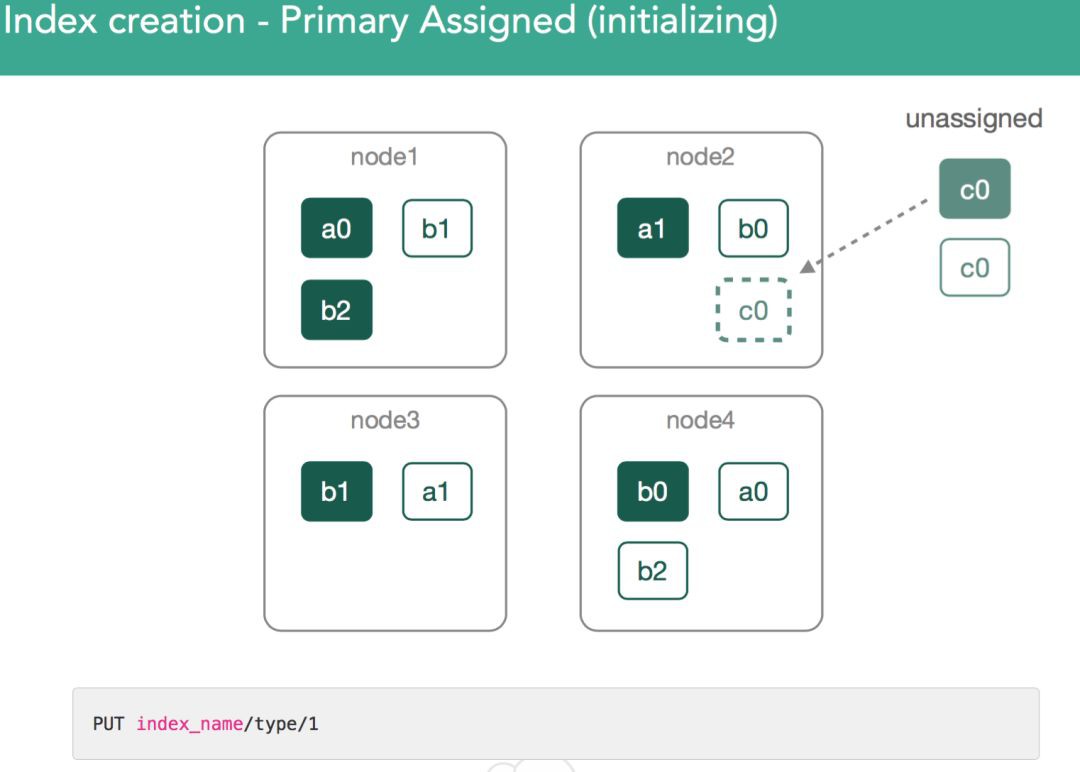
一旦我們做出了primary shard將分配到哪個節點的決定,這個shard的狀態就被標註為”initializing”(正在初始化),並且這個決定會透過一個modified ClusterState廣播到叢集中所有節點,然後叢集中所有節點都將應用這個ClusterState
在shard狀態被標註為”initializing”後,會進行如下動作。如下麵動圖所示
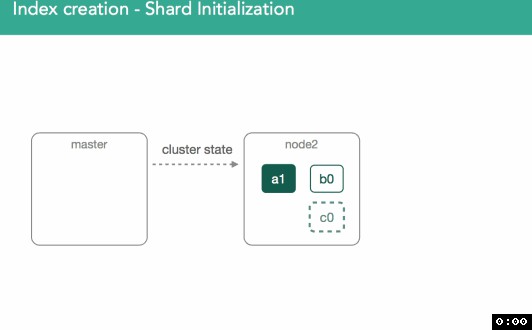
-
被選中的節點探測到它自己被分配了一個新的shard
-
在被選中的節點上,將建立一個空的lucene索引(譯註:每一個shard都是一個獨立的lucene索引),建立完成後被選中的節點向master傳送“shard已經就緒”的通知
-
master收到通知後,master需要把被選中的節點上shard的狀態標註”started”,為了做到這一點,master傳送一個modified ClusterState
-
被選中的節點收到master傳送的modified ClusterState,於是被選中的節點啟用此shard,並把shard的狀態標註為”started”
因為這是一個primary shard,自此,我們就可以向其索引檔案了
正如你所見,所有的通訊都是透過modified ClusterState進行的。一旦這個週期結束,master會執行re-route,重新評估shard分配,有可能對先前迭代中被抑制的內容做出決定
現在,master要分配剩下的replica shard c0了,這也是由分配決定器來作決定的。分配決定器必須得等到包含primary shard的節點把primary shard的狀態標註為”started”後,才能開始分配replica shard c0。如下圖所示,primary shard c0已經在node2上分配完成且狀態已經被標註為”started”,現在master需要分配剩下的replica shard c0了,replica shard c0的狀態是unassigned
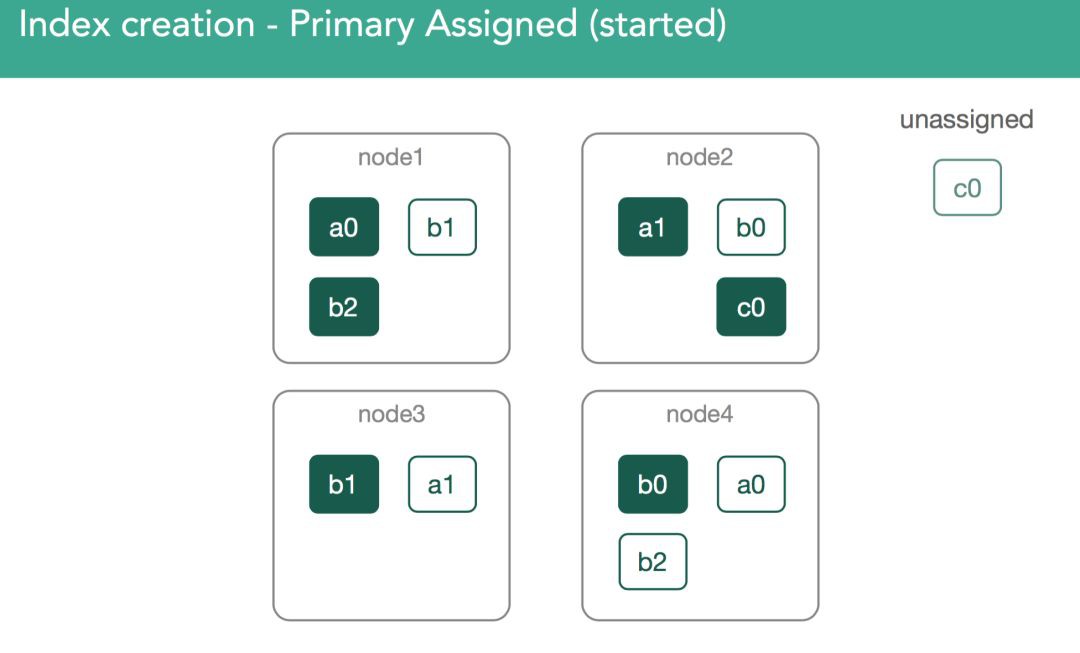
此時,會進行重新平衡,過程就和前面所描述的一樣,重新平衡的目的是使資料在叢集中是平衡的。在當前例子中,叢集將把replica shard c0分配到node3,以使得叢集是平衡的。最終,叢集中每個節點包含3個shard。如下麵兩幅圖所示,重新平衡把replilca shard c0分配給了node node3


上例子中,我們只是建立了一個空的replica shard,這比,假設說已經存在某個狀態為”started”且包含資料的primary shard,要簡單。對於這種情況,我們必須得確保新的replica shard包含有和primary shard同樣的資料。如下麵兩幅圖所示,第一幅,master把需要初始化replica shard c0的ClusterState廣播到整個叢集;第二幅,node2探測到自己被分配了一個新的shard


當replica shard分配完成後,需要理解的很重要的一點是,我們會從primary shard複製所有缺失的資料到replica shard,資料複製完成後,master才會把replica shard的狀態標註為”started”,並且向叢集中廣播一個新的ClusterState。如下麵動圖所示

場景二、 是時候移動shard了

有時你的叢集可能需要在叢集內部移動已經存在的shard。這可能會有很多原因
1. 使用者配置
這方面最常見的一個例子就是Hot/Warm配置,當資料老化時,會根據Hot/Warm配置把資料移動到訪問速度較慢的磁碟上。如下圖所示

2. 使用者使用命令顯式移動shard
使用者透過cluster re-route命令來使得elasticsearch將shard從一個地方移到另一個地方
3. 磁碟相關的配置
存在與磁碟使用空間相關的以下兩個設定,分配決定器會根據這些設定的閾值來移動shard
-
cluster.routing.allocation.disk.watermark.low
-
cluster.routing.allocation.disk.watermark.high
超過低水位閾值時,elasticsearch將阻止我們寫入新的shard。同樣,超過高水位閾值時,elasticsearch會把此節點上shard重新分配到其他節點上,直到當前節點的磁碟佔用低於高水位閾值。如下圖所示
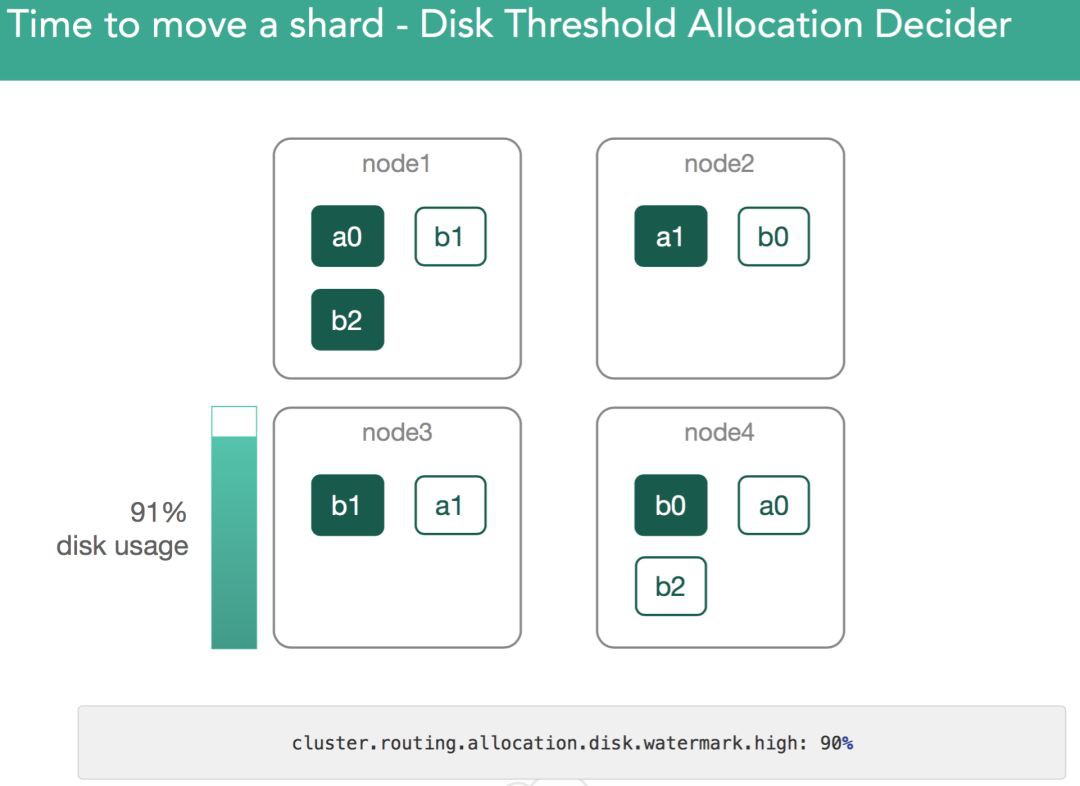
4. 叢集新增節點
可能你的叢集已經達到最大容量,於是你添加了一個新的節點,此時elasticsearch會重新平衡(rebalance)整個叢集。如下圖所示

Shard可能會包含很多G的資料,因此,在叢集間移動它們可能產生極大的效能影響。為使這個過程對使用者透明,移動shard必須在後臺執行。也就是盡可能的降低移動shard對elasticsearch其他方面的影響。為此,引入了一個抑制引數(indices.recovery.max_bytes_per_sec/cluster.routing.allocation.node_concurrent_recoveries) ),以保證移動shard期間依然可以繼續向這些shard索引資料。如下圖所示

記住:elasticsearch的所有資料都是透過Lucene儲存的。Lucene使用被稱為segment的一組檔案來儲存一組倒排索引。給定的tokens/words時,倒排索引結構可以方便的告訴你這些tokens/words包含在哪些檔案中,出現在檔案中的什麼位置。當Lucene索引檔案時,檔案暫存於記憶體中的indexing buffer。當indexing buffer滿或,elasticsearch發出refresh操作(從而引發lucene flush)時,indexing buffer中的資料就被強制寫入被稱為segment的倒排索引中。如下圖所示
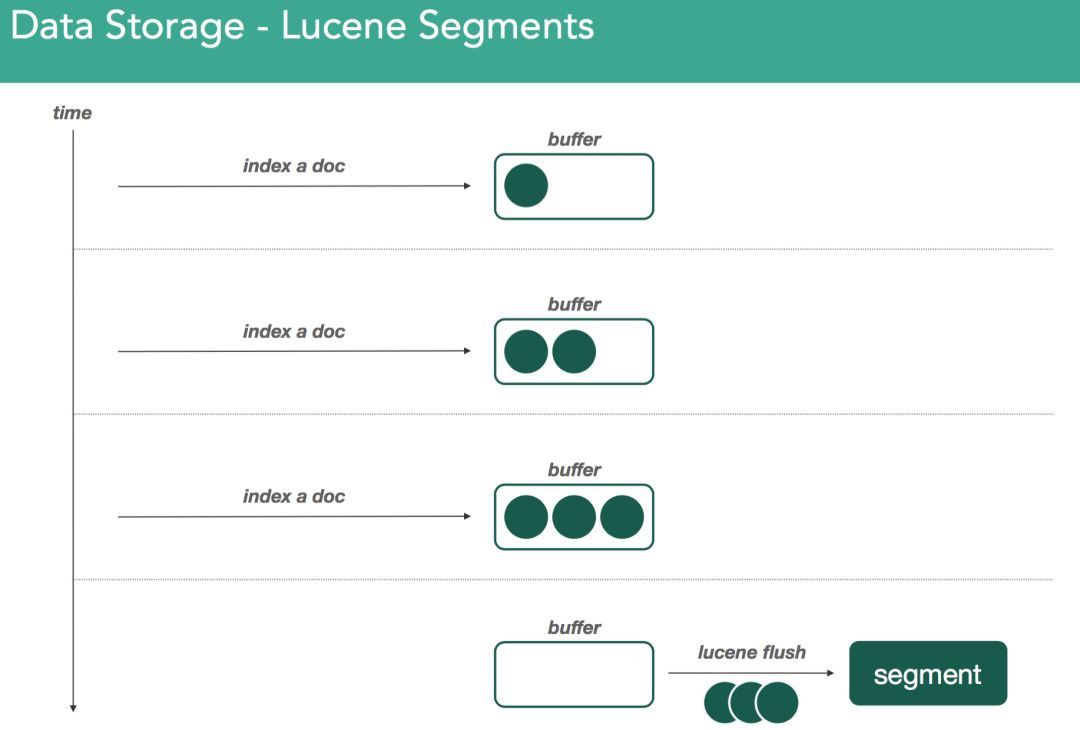
隨著我們繼續索引檔案,我們會用同樣的方式建立新的segment。關於segment,一個重要的事情就是segment是不可變的(immutable)。這意味著,一旦寫了一個segment,這個segment就永遠不會改變了。如果你發出刪除或任何改變,這些動作將發生在新的segment上,在新的segment上同樣發生合併過程。如下圖所示

既然資料是儲存在記憶體的,理論上在資料提交到segment檔案之前(譯註:即使已寫入segment也可能會丟失,因為segment寫入filesystem時,只是寫入了記憶體即filesystem cache,只有呼叫filesystem的fsync後,內容才真正寫入了磁碟。而出於效能考慮,filesystem是週期性而不是實時的呼叫fsync的),資料是有可能丟失的。elasticsearch使用transaction log來緩解這種情況。每當檔案索引進Lucene時,檔案也會被寫入transaction log。如下圖所示

Transaction log是順序寫入的,最後一個請求位於檔案的末尾。藉助transaction log,我們就可以恢復尚未寫入Lucene中的檔案。elasticsearch的持久化模型如下圖所示

生成segment時可能並未執行fsync,此時segment會暫存於filesystem cache記憶體中,OS會暫緩掃清資料到磁碟。這麼作是出於效能原因,因此,必須要把filesystem cache記憶體中的segment寫入到磁碟,同時清空transaction log,這個工作是透過elasticsearch flush來完成的
當發出elasticsearch flush(從而引發lucene commit)命令時,會做兩件事情
-
把indexing buffer中的資料寫入磁碟,從而生成一個新的segment
-
遍歷所有的segment檔案,請求filesystem使用fsync將所有segment寫入磁碟
執行elasticsearch flush就把記憶體中所有資料(即indexing buffer中的資料以及filesystem cache記憶體中的segment),統統寫入了磁碟,並且清空了transaction log,這確保我們不會丟失任何資料。對於重新安置(relocation)shard,如果我們捕獲並儲存一組給定的segment,則我們得到一個時間點一致且資料不可變的資料快照
譯註:參考Elasticsearch: 權威指南–>持久化變更瞭解檔案寫入過程。梗概總結如下圖所示
https://www.elastic.co/guide/cn/elasticsearch/guide/current/translog.html

以下麵動圖為例,叢集想要把node4上的a0移動到node5,於是master標註a0為正在從node4重新安置到node5,node5收到請求後在node5上初始化一個shard。對這個行為,有一個非常重要的事情需要註意,當進行重新平衡時,看起來replica shard正在從node4移動到node5,但事實上,重新安置shard時總是從primary shard複製資料的(即:node1上的a0)

以下麵動圖為例,我們來演示“把node1上的primary shard重新安置到node5”。記住我們前面所說的兩種資料儲存機制,transaction log和lucene segment
此例中node5是空節點,node1上有primary shard。全部步驟如下
-
master向node5發送了一個modified ClusterState,master要求node5初始化一個新的shard
-
node5探測到自己被分配了一個新的shard
-
node5向node1(node1上有primary shard)傳送請求,請求開始恢復過程
-
node1收到node5的請求,然後,node1驗證它自己知道node5傳送的請求
-
node1驗證透過,於是在node1上,elasticsearch固定transaction log以防止其被刪除並捕獲索引的segment快照,確保我們捕獲了shard中的所有資料
-
node1將segment資料傳送到node5上的標的檔案
-
在node5重放node1的transaction log,這會確保資料複製期間新索引進來的檔案也能複製進入到node5上的標的檔案
-
node1傳送“資料恢復已完成”給node5
-
node5告知master“node5上的shard已經就緒”
-
master傳送modified ClusterState到node5,啟用shard,將shard狀態標註為”started”。同時,master刪除掉node1上的源shard
上面這一切都在後臺發生,因此整個過程中你依然可以向primary shard中索引資料。在這個過程中,如果確實又向primary shard中索引了新的資料,那麼,這些新的資料並不包含在步驟5所捕獲快照中,但這沒有關係,因為透過步驟7重放node1的transaction log就可以確保這些新的資料也被覆制進入了新的shard

現在問題來了,何時才能停下?複製過程中可能依然有新索引的檔案進入primary shard,這意味著transaction log是一直增長的。在1.x中,我們的措施是鎖定transaction log,從鎖定點開始,所有再進來的請求都被阻塞,直到重放transaction log完成
在2.x/5.x中,我們作的更好。一旦我們開始重新安置(relocation),primary shard會把所有的索引操作傳送到新的primary shard(位於node5上)。因為我們知道我們何時捕獲的lucene快照,我們也知道shard是何時被初始化的,於是我們就確切的知道需要重放transaction log中的哪些資料
一旦恢復完成,標的節點(target node)給master傳送通知,告知master“shard都已就緒”。master處理請求,複製剩餘的primary shard(譯註:因為一個索引可能儲存多個primary shard),並啟用shard。然後,源shard可以被移除了,這個過程一直重覆,直到重新平衡(rebalancing)完成
場景三、 重啟整個叢集
我們要考察的下一個場景是重啟整個叢集。在這個場景中,我們並不處理啟用的segment,而是在每個節點上找到本地資料。重啟整個叢集可能會發生在 維護週期,升級以及與計劃中維護相關的任何事情

這裡,master被選舉出來,然後會新建一個ClusterState或者從磁碟恢復一個ClusterState。現在我們有了一個待分配的shard的串列,這些shard第一次被分配時,分配決定器可以把它們分配到任何一個節點上,但,現在不能再隨便分配了。這意味著,我們需要找到這些資料,並確保我們能開啟這些我們之前建立的lucene索引。如下圖所示
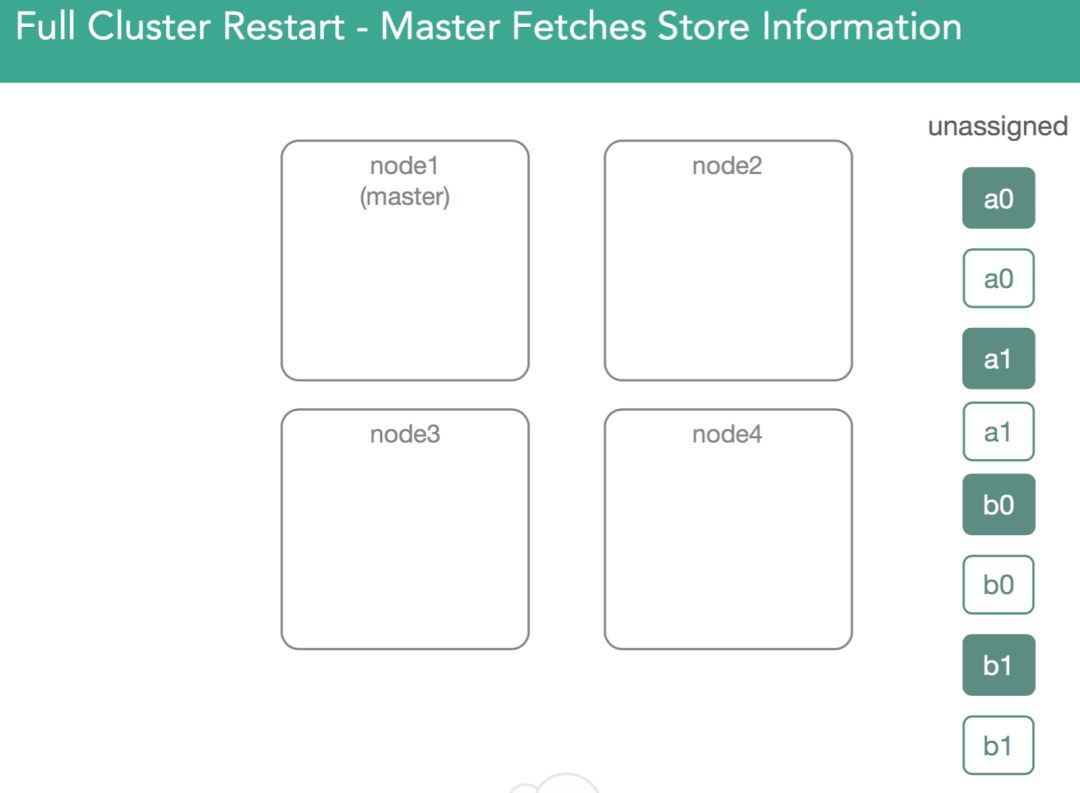
為了做到這點(找到資料並開啟之前建立的索引),master在叢集中每一個節點上分配一個primary shard,且要求此primary shard傳回磁碟上的所有內容。這意味著,我們物理上開啟segment,然後透過確認一個shard副本來響應master。這時,master決定哪個節點將得到primary shard。在5.x中,我們會優先選擇之前的primary shard(這是一個最佳化)。如下圖所示

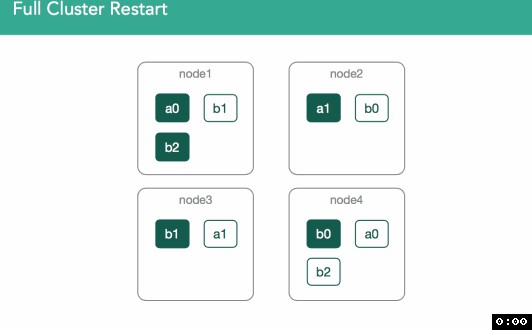
在下麵的例子中,我們可以看到,node1上的a0之前是primary shard,但,其他任何副本都可能變成primary shard。在這個例子中,node4上的shard被標註為”initializing”,但,不同之處在於,這一次我們要使用已經存在的資料,並且可以檢查節點上的lucene索引來驗證lucene索引有效且可以開啟。master會收到“shard已經就緒”、“shard已被分配”的通知,然後,master把這些shard的分配結果加入到叢集狀態中。如下麵動圖所示
為了驗證兩個shard上資料是一樣的,我們會有一個複製過程,這個過程和重新安置非常類似,不同之處在於因為所有shard副本都是從磁碟恢復得來的,這些shard可能已經是匹配的了,因此可能無需傳輸shard。此連結詳細描述了這個過程。如下圖所示

因為segment就是獨立的lucene索引,大量索引檔案之後,非常可能磁碟上的segment和其他節點上相同的segment並不一致。有些segment用了更多資源,有些segment擁有煩人的鄰居(nosy neighbors)。如下圖所示

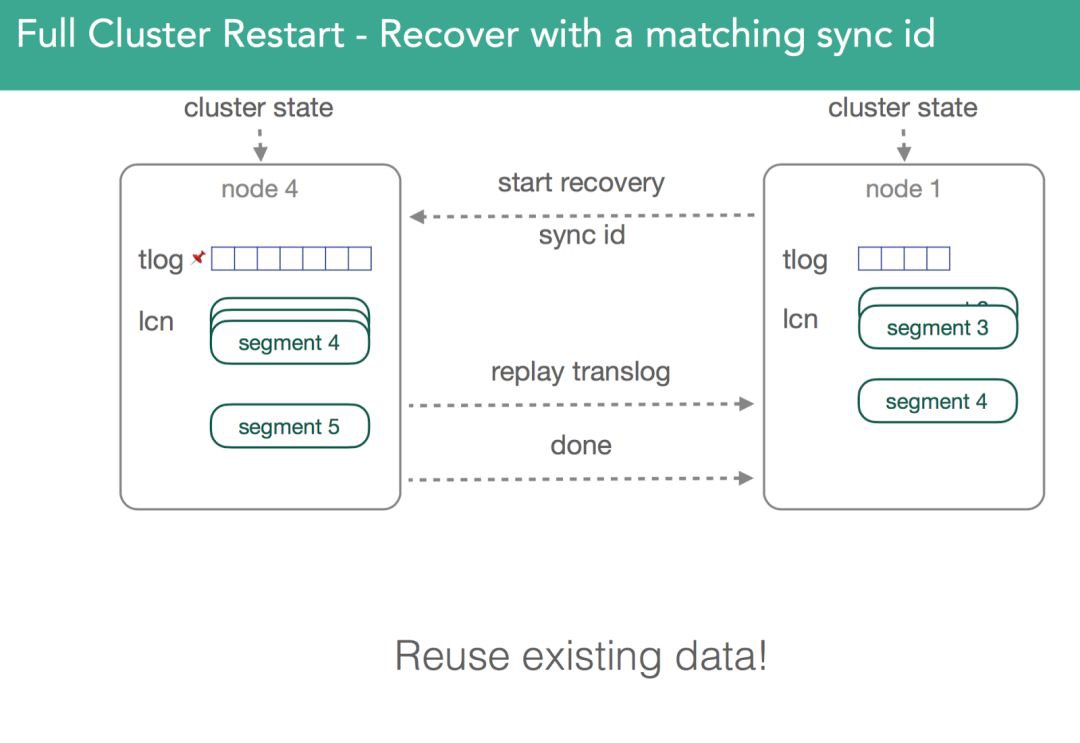
在v1.6之前,必須得複製所有segment。正是由於這些,v1.6之前的恢復是很慢的。我們必須得同步primary shard和replic shard,卻又不能使用本地資料。為瞭解決這個問題,我們添加了sync_flush和sync_id。取不發生索引檔案的某個時刻,使用一個唯一識別符號來表示捕獲的資訊,確保同一個shard的各個副本是完全一致的。因此,當我們進行恢復時,我們傳送sync_id識別符號,如果識別符號一致,則無需複製檔案了,就可以重用老的副本。因為lucene中的segment是不可變的,這隻對非啟用的shard有效。註意:下圖展示的是不同節點上的同一個shard,複製的數字就是發生的變化

場景四、 單個節點丟失(node3丟失)
在下圖中,node3從叢集中被移除了,node3上儲存有b1的primary shard。此時,首先立即採取的步驟是master把當前位於node1上的b1的replica shard提升為primary shard。b1所在索引的健康狀態以及叢集的健康狀態變成黃色,因為存在某個shard備份並沒有全部被分配(shard所有備份的數量是使用者在定義索引時指定的)。因此,master要嘗試在剩下的某個節點上再分配一個新的b1的replica shard。如果node3是由於暫時的網路故障(或JVM GC引起的長時間STW)所導致,且,在網路故障恢復和節點再回到叢集前,並未向shard中索引任何檔案,則在node3缺席的這段時間內,在某個剩下的節點上重新複製一個新的b1的replica shard就純屬是浪費資源。如下麵動圖所示

在v1.6中,引入了基於index(per-index)設定來解決這個問題(index.unassigned.node_left.delayed_timeout,預設1分鐘)。當node3離開時,會先延遲此處指定的時長再進行重新分配shard。如果在此時長之前node3回來了,則考察primary shard較node3上的shard是否發生了變化,若在此期間,primary shard並未有任何變化,則node3上的shard就被指定為replica shard;若primary shard發生了變化,則丟棄node3上的shard,並且重新從primary shard複製shard到node3
在v2.0中,引入了一個改進,如果node3在延遲超時之後才回來,對於位於node3上且依然匹配primary shard的任何shard(使用sync_id識別符號來決定匹配與否),即使重新複製已經開始了,這些重新複製過程也會被停止,然後,node3上的這些shard被指定為replica shard。如下圖所示

看完本文有收穫?請轉發分享給更多人
關註「ImportNew」,提升Java技能

