[導 讀]春季到來,春招不久也會開始。在本專案中,作者為大家準備了 ML 演演算法工程師面試指南,它提供了完整的面試知識點、程式設計題及題解、各科技公司的面試題錦等內容。目前該 GitHub 專案已經有 1 萬+的收藏量,想要跳一跳的同學快來試試吧。
專案地址:
https://github.com/imhuay/Algorithm_Interview_Notes-Chinese
如下所示為整個專案的結構,其中從機器學習到數學主要提供的是筆記與面試知識點,讀者可回顧整體的知識架構。後面從演演算法到筆試面經主要提供的是問題及解答方案,根據它們可以提升整體的解題水平與程式設計技巧。

面試知識點
面試題多種多樣,但機器學習知識就那麼多,那麼為了春招或春季跳槽,何不過一遍 ML 核心知識點?在這個 GitHub 專案中,作者前一部分主要介紹了機器學習及各子領域的知識點。其中每一個知識點都只提供最核心的概念,如果讀者遇到不熟悉的演演算法或者遇到知識漏洞,可以進一步閱讀相關文獻。
專案主要從機器學習、深度學習、自然語言處理和數學等方面提供詳細的知識點,因為作者比較關註 NLP,所以並沒有提供詳細的計算機視覺筆記。
機器學習
首先對於機器學習,專案主要從基礎概念、基本實踐、基本演演算法和整合學習專題這四個方面概括 ML 的總體情況。其中基礎概念可能是最基本的面試問題,例如“偏差方差怎麼權衡?”、“生成模型和判別模型的差別是什麼?”、“先驗和後驗機率都是什麼,它們能轉換嗎?”。
這些知識點一般是入門者都需要瞭解的,而對於 ML 基本實踐,主要會從如何做好傳統 ML 開發流程的角度提問。例如“你如何選擇超引數,能介紹一些超引數的基本搜尋方法嗎?”、“混淆矩陣、準確率、精確率、召回率或 F1 值都是什麼,如何使用它們度量模型的好壞?”、“你能介紹資料清洗和資料預處理的主要流程嗎,舉個例子?”。
這些問題都能在前兩部分的知識點中找到答案。後一部分的基本演演算法就非常多了,從最簡單的 Logistic 回歸到複雜的梯度提升樹,這一部分總結了主流的機器學習演演算法:
-
資訊理論
-
邏輯斯蒂回歸
-
支援向量機
-
決策樹
-
整合學習
-
梯度提升決策樹 GBDT
-
隨機森林
其中每一種演演算法都提供了最核心的概念,例如對於決策樹中的 CART 演演算法,筆記主要取用了李航《統計學習方法》中的描述:

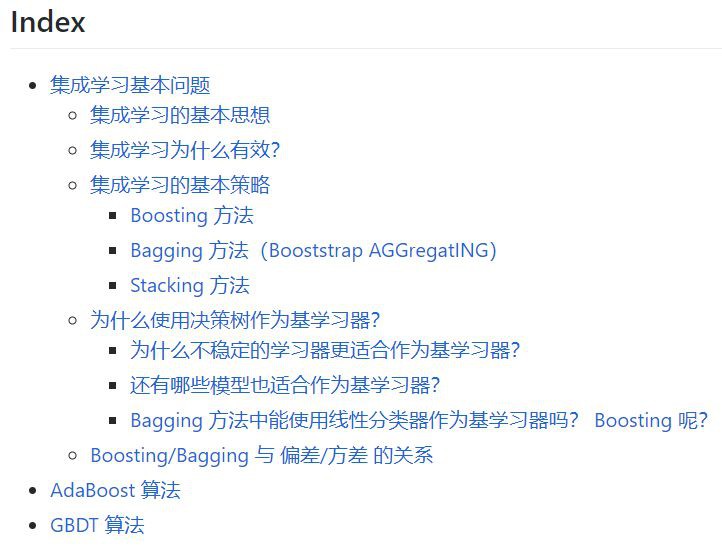
最後機器學習還有一個關於整合方法的專題。除了支援向量機,整合方法相關的問題在 ML 中也比較重要,因為像 XGboost 和隨機森林等方法在傳統 ML 中效果應該是頂尖的,被問到的機率也大得多。
深度學習
深度學習的內容就相對比較多了,目前也有非常多的筆記或資料,但是我們可能會感覺深度學習的問題並沒有機器學習難。頂多會讓我們手推一個反向傳播演演算法,不會像手推支援向量機那樣讓我們從運算式推一下摺積網路。如果要為深度學習打基礎,其實最好的辦法是學習 Ian Goodfellow 的《Deep Learning》,我們只要閱讀這本書的前兩部分:應用數學與機器學習基礎;深度網路:現代實踐。第三部分因為涉及大量前沿研究的東西,我們暫時可以不急著學。
該專案主要從以下幾個方面介紹深度學習面試知識點:
-
深度學習基礎
-
深度學習實踐
-
CNN 專題
-
RNN 專題
-
最佳化演演算法專題
-
序列建模專題
-
《Deep Learning》整理
前面 6 個專題都是介紹的筆記,每一個專題都有非常多的具體內容,其中序列建模專題還取用了機器之心綜述的從迴圈到摺積,探索序列建模的奧秘。如下展示了最佳化演演算法專題所包含的內容:

在最後的《Deep Learning》整理中,專案作者給出了五十多道深度學習問題,並根據這些問題介紹《Deep Learning》中的知識點。如下為問題示例,不同的星號表示問題的難度:

自然語言處理與數學
後面的自然語言處理也是最近在重點更新的,目前介紹的方面主要有:
-
自然語言處理基礎
-
NLP 發展趨勢
-
詞嵌入專題
-
句嵌入專題
-
多模態專題
-
視覺問答綜述
-
深度理解查詢
NLP 很多知識點其實都不算基礎內容,這需要根據我們自己學習的領域收集複習內容。不過像 NLP 基礎或詞嵌入等知識點,專案作者介紹得很詳細,它們也是 NLP 面試必備知識。
最後還有一些數學知識點,它們是演演算法工程師面試所需要具備的基礎。例如今日頭條演演算法工程師的實習生面試會問:“在圓環上隨機選取 3 個點,這 3 個點組成銳角三角形的機率?”,或者其它算個積分之類的。專案作者主要為面試準備了以下幾方面的知識點:
-
機率論
-
微積分本質
-
深度學習核心
其中深度學習核心主要包含非線性啟用函式、梯度下降和反向傳播。
演演算法題和筆試題
對於程式設計面試,基礎演演算法是必不可少的,它們一般體現在筆試題上,例如資料結構、動態規劃或排列組合等。很多開發者可能感覺筆試解題會很難,因為題目並不會告訴你需要用什麼樣的基礎演演算法來解決,全靠我們自己一步步解析題目。這就要求我們對各種基礎演演算法都比較熟悉,專案作者提供了以下基本演演算法專題:
-
字串
-
資料結構
-
高階資料結構
-
動態規劃
-
雙指標
-
區間問題
-
排列組合
-
數學問題
-
Shuffle、取樣、隨機數
-
大數運算
-
海量資料處理
這些演演算法題會介紹具體的問題、解題思路以及對應的解題程式碼。例如在資料結構中,我們如何判斷樹 B 是不是樹 A 的子樹。

如下所示為解題程式碼,註意基本上各基礎演演算法的題解都是用 C++寫的,作者會取用劍指 Offer 題解和 Leetcode 題解等的解決方案。
class Solution {
public:
bool HasSubtree(TreeNode* p1, TreeNode* p2) {
if (p1 == nullptr || p2 == nullptr) // 約定空樹不是任意一個樹的子結構
return false;
return isSubTree(p1, p2) // 判斷子結構是否相同
|| HasSubtree(p1->left, p2) // 遞迴尋找樹 A 中與樹 B 根節點相同的子節點
|| HasSubtree(p1->right, p2);
}
bool isSubTree(TreeNode* p1, TreeNode* p2) {
if (p2 == nullptr) return true; // 註意這兩個判斷的順序
if (p1 == nullptr) return false;
if (p1->val == p2->val)
return isSubTree(p1->left, p2->left) // 遞迴判斷左右子樹
&& isSubTree(p1->right, p2->right);
else
return false;
}
};
此外,該專案還提供了 IO 模板和必備演演算法模板。作者表示不少筆試不像 LeetCode 那樣可以自動完成 I/O,我們需要手動完成資料 I/O,而且如果我們沒有 ACM 經驗,很可能會在這上面浪費很多時間。因此這裡總結的幾種常見 IO 模板對於程式設計面試有很大的幫助,另外的演演算法模板同樣也是。
例如如果我們輸入不定數量個 Input,且以某個特殊輸入為結束標誌,那麼用 C 語言實現的模板為:
// 示例 1
int a, b;
while (scanf("%d %d", &a;, &b;) != EOF && (a != 0 && b != 0)) {
// ...
}
// 或者
while (scanf("%d %d", &a;, &b;) != EOF && (a || b)) {
// ...
}
// 示例 2
int n;
while (scanf("%d", &n;) != EOF && n != 0) {
// ...
}
用 C++實現的模板為:
// 示例 1
int a, b;
while (cin >> a >> b) {
if (a == 0 && b == 0)
break;
// ...
}
// 示例 2
int n;
while (cin >> n && n != 0) {
// ...
}
面試真題
最後,專案作者還收集了十多家科技企業面試真題,並介紹從一面到三面的內容與經驗。

例如以下是頭條/位元組跳動-深度學習/NLP 方向的三面概覽:

具體的面試題也會提供,如下所示為位元組跳動 18 年 8 月的筆試題,積分卡牌遊戲:

當然給了題目,對應的解決方案也會提供:
# 輸入處理
n = int(input())
x, y = [], []
for i in range(n):
_x, _y = list(map(int, input().split()))
x.append(_x)
y.append(_y)
xy = list(zip(x, y))
xy = sorted(xy, key=lambda t: t[1])
ret = 0
if sum(x) % 2 == 0: # 如果所有 x 的和為偶數
print(sum(y)) # 直接輸出所有 y 的和
else:
for i in range(len(xy)):
if xy[i][0] % 2 == 1: # 去掉 x 中為奇數的那一項
ret = sum([xy[j][1] for j in range(len(xy)) if j != i])
print(ret)
break
