
本期內容選編自微信公眾號「開放知識圖譜」。
ISWC 2018

■ 連結 | http://www.paperweekly.site/papers/1912
■ 原始碼 | https://github.com/quyingqi/kbqa-ar-smcnn
■ 解讀 | 吳桐桐,東南大學博士生,研究方向為自然語言問答
概述
隨著近年來知識庫的快速發展,基於知識庫的問答系統(KBQA )吸引了業界的廣泛關註。該類問答系統秉承先編碼再比較的設計思路,即先將問題和知識庫中的三元組聯合編碼至統一的向量空間,然後在該向量空間內做問題和候選答案間的相似度計算。該類方法簡單有效,可操作性比較強,然而忽視了很多自然語言詞面的原始資訊。
因此,本文提出了一種 Attentive RNN with Similarity Matrix based CNN(AR-SMCNN)模型,利用 RNN 和 CNN 自身的結構特點分層提取有用資訊。
文中使用 RNN 的序列建模本質來捕獲語意級關聯,並使用註意機制同時跟蹤物體和關係。同時,文中使用基於 CNN 的相似矩陣和雙向池化操作建模資料間空間相關性的強度來計算詞語字面的匹配程度。
此外,文中設計了一種新的物體檢測啟髮式擴充套件方法,大大降低了噪聲的影響。文中的方法在準確性和效率上都超越了 SimpleQuestion 基準測試的當前最好水平。
模型

模型如上圖所示,假設單關係問題可以透過用單一主題和關係論證來查詢知識庫來回答。因此,只需要元組(s,r)來匹配問題。只要s和r的預測都是正確的,就可以直接得到答案(這顯然對應於o)。
根據上述假設,問題可以透過以下兩個步驟來解決:
1. 確定問題涉及的 Freebase 中的候選物體。給定一個問題 Q,我們需要找出物體提及(mention)X,那麼名稱或別名與物體提及相同的所有物體將組成物體候選 E。現在 E 中的所有物體都具有相同的物體名稱,因此我們暫時無法區分他們。具體地,模型中將命名物體識別轉換成了基於 Bi-LSTM 完成的序列標註任務。
2. 所有與 E 中的物體相關的關係都被視為候選關係,命名為 R。我們將問題轉換為樣式 P,它是透過用
為了更好地進行關係匹配,模型從單詞字面表達和語意兩個層面對自然語言進行了建模。具體操作如下圖所示:

圖中所示的 AR-SMCNN 模型,輸入是經替換 mention 後的問題模版(pattern)P 和候選關係 rk。
模型左邊的部分是結合了 attention 機制的 BiGRU,用於從語意層面進行建模。右邊的部分是 CNN 上的相似性矩陣,用於從字面角度進行建模。最終將特徵 ?1,?2,?3,?4 連線在一起並透過線性層得到最終的候選關係分數 ?(?,??)。
實驗結果

如表 1 所示,文中提出的方法在 FB2M 和 FB5M 設定上達到了 77.9% 和76.8% 的精確度,分別超過了之前的最佳結果 0.9% 和 1.1%。
總結
在這篇文章中,作者提出了一種基於神經網路的新穎方法來回答大規模知識庫中的單關係問題,它利用 RNN 和 CNN 的優勢互補來捕獲語意和文字相關資訊。透過省略物體匹配模型使得模型簡單化,所提出的方法實現了有競爭力的結果。
儘管所提出的方法僅限於單關係問題,但這項工作可以作為未來開發更先進的基於神經網路的 QA 方法的基礎,可以處理更複雜的問題。證實了人機協作的有效性,但是 MQS 演演算法複雜度太高,導致執行時間過長。
NAACL HLT 2018

■ 連結 | http://www.paperweekly.site/papers/1911
■ 解讀 | 鄧淑敏,浙江大學博士生,研究方向為知識圖譜與文字聯合表示學習
動機
機器學習一直是許多 AI 問題的典型解決方案,但學習過程仍然嚴重依賴於特定的訓練資料。一些學習模型可以結合貝葉斯建立中的先驗知識,但是這些學習模型不具備根據需要訪問任何結構化的外部知識的能力。
本文的標的是開發一種深度學習模型,可以根據任務使用註意力機制從知識圖譜中提取相關的先驗知識。本文意在證明,當深度學習模型以知識圖譜的形式訪問結構化的知識時,可以用少量的標記訓練資料進行訓練,從而降低傳統的深度學習模型對特定訓練資料的依賴。
模型
模型的輸入是一組句中的詞構成的詞向量序列 x=[x_1, x_2,…,x_T],經過一個 LSTM 單元得到每個詞向量的隱藏層狀態 h_t = f(x_t, h_{t-1}),然後將得到的隱藏層狀態向量加和平均得到 o = 1/T(\sum_{t=1}^{T}h_t)。根據可以計算背景關係向量 C=ReLU(o^T W)。
物體和關係對應的背景關係向量分別與物體和關係的向量相乘,經過softmax操作,算出每個物體和關係的權重 \alpha_{e_i}, \alpha_{r_i}。其中,物體和關係的向量是透過 DKRL 模型(一種結合文字描述的知識圖譜表示學習模型)計算得到。

然後將文字中的所有物體和關係分別根據前面算出的權重進行加權平均,從而得到文字中所有物體和關係的向量 e, r。

根據 TransE 的假設 (h+r≈t),構建事實元組 F=[e,r,e+r],將這個輸入 LSTM 模型中進行訓練,得到文字分類的結果。

計算文字中物體和關係表示的原始模型架構如下圖所示:

將計算物體和關係表示的模型與文字分類的 LSTM 模組進行聯合訓練,聯合模型架構如下圖所示。

文字中物體和關係的數目很大,為每一個物體和關係分別計算權重開銷不菲。為了減少註意力空間,本文利用 k-means 演演算法對物體和關係向量進行聚類,並引入了基於摺積的模型來學習知識圖譜物體和關係集的表示。
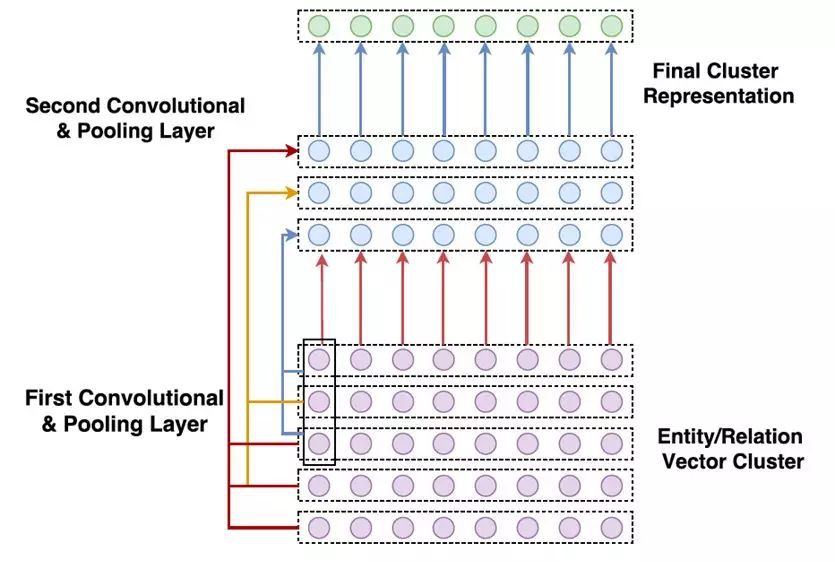
實驗
本文使用了 News20,DBPedia 資料集來解決文字分類的任務,使用斯坦福自然語言推理(SNLI)資料集進行自然語言推斷的任務。還使用了 Freebase (FB15k) 和 WordNet (WN18) 作為相關的知識庫輸入。

圖 (a)、圖 (b) 分別表明,在 SNLI 資料集上訓練的準確度和損失函式值。實驗中分別比較 100% 資料集,70% 資料集,以及 70% 資料集 + KG 三種情況輸入的結果。
可以發現,引入 KG 不僅可以降低深度學習模型對訓練資料的依賴,而且還可以顯著提高預測結果的準確度。此外,本文提出的方法對大量的先驗資訊的處理是高度可擴充套件的,並可應用於任何通用的 NLP 任務。
AAAI 2018

■ 連結 | http://www.paperweekly.site/papers/1909
■ 解讀 | 高桓,東南大學博士生,研究方向為知識圖譜、自然語言處理
動機
傳統的知識圖譜問答主要是基語意解析的方法,這種方法通常是將問題對映到一個形式化的邏輯運算式,然後將這個邏輯表達轉化為知識圖譜的查詢例如 SPARQL。問題的答案可以從知識圖譜中透過轉化後的查詢得到。
然而傳統的基於語意解析的知識庫問答會存在一些挑戰,如基於查詢的方法只能獲取一些明確的資訊,對於知識庫中需要多跳才能獲取的答案則無法回答。舉例來說當問到這樣一個問題“Who wrote the paper titled paper1?,傳統的基於語意解析的方法可以獲得如下陳述句進而可以查到 paper1 這個物體。

但是在上例中,當我們詢問 Who have co-authored paper with author1? 由於缺乏 co-author 這個明確的關係,傳統的方法則無法轉換成合適的查詢陳述句。但實際上,在上例中 author2 則是 author1 在 paper1 中的 co-author。
另一個對於傳統方法的挑戰是,在傳統方法中問句中含有的物體通常都使用很簡單的方法來匹配到知識庫上,例如字串匹配。但實際場景中使用者的輸入可能是透過語音識別轉換而來或者是使用者透過打字輸入而來。因此使用者的輸入很難確保不存在一定的噪聲。在具有噪聲的場景下,問句中的物體則很難直接準確的匹配到知識庫上。
因此本文提出了一個端到端的知識庫問答模型來解決以上兩個問題。
創新點

▲ 模型框架圖
本文提出的模型如上圖所示,這個模型為了剋服上述所說的問題則將模型分為兩個部分:
第一部分是透過機率模型來識別問句中的物體。如問句 who acted in the movie Passengers? 我們希望能將 Passengers 識別出來。但由於訓練資料中的物體沒有被標註出來,因此這個識別的物體將被看成一個隱變數。整個識別物體的過程如下:
1. 先將輸入的問句 q 進行編碼,將問句 q 轉換為一個維度是 d 的向量;
2. 隨後將圖譜中每個物體都轉化為一個向量;
3. 透過 softmax 計算在 q 下圖譜中每個物體是 q 中物體的機率。
該過程在整個模型框架圖的左上部分在上例中輸入問句 The actor of lost Christmas also starred in which movies,透過演演算法在圖中找到 lost Christmas 為問句中對應的物體。
第二部分則是在問答時在知識圖譜上做邏輯推理,在推理這部分的工作中我們給出了上一步識別的物體和問句希望系統能給出答案。由於在整個系統的學習過程中沒有人來標註在問答時使用的推理規則,因此在問答時使用的規則將被學習出來。整個推理過程如下所示:
1. 透過另一個網路對問句 q 進行編碼,將 q 轉化為一個維度是 d 的向量;
2. 透過一個 Reasoning graph embedding,對 y 的相鄰物體進行編碼;
3. 透過 softmax 計算透過 y 推理找到物體是問題 q 答案的機率;
4. 如果推理沒有達到限定的步數則傳回 2,將原來 y 相鄰的物體轉換為 y 進而進行推理。
整個推理過程則在上圖的右半部分,該部分分別計算推理時物體是問句答案的機率,最後得到物體 shifty 對於問句 q 機率最大。而機率最大的物體到 y 的路徑則是推理所獲取的路徑為 lost Christmas acted Jason Flemyng acted Shifty。
最後演演算法透過 EM 進行最佳化,整體訓練的思路是希望第一部分和第二部分的概率同時最大。
實驗結果

實驗結果顯示在 Vanilla、NTM 和 Audio 資料集下,演演算法的效果都超過傳統的 QA 系統,同時在需要推理的問題中效能更為顯著。
AAAI 2018

■ 連結 | http://www.paperweekly.site/papers/1910
■ 原始碼 | http://sentic.net/downloads/
■ 解讀 | 徐康,南京郵電大學講師,研究方向為自然語言處理、情感分析和知識圖譜
概述
目前大部分人工智慧的研究都集中在基於統計學習的方法,這些方法需要大量的訓練資料,但是這些方法有一些缺陷,主要是需要大量的標註資料而且是領域依賴的;不同的訓練方法或者對模型進行微調都會產生完全不同的結果;這些方法的推理過程都是黑盒的。
在自然語言處理領域中,人工智慧科學家需要減少統計自然語言處理領域和其他理解自然語言急需的領域(例如,語言學、常識推理和情感計算)之間的隔閡。在自然語言處理領域,有自頂向下的方法,例如藉助符號(語意網路)來編碼語意;也有一種自底向上的方法,例如基於神經網路來推斷資料中的句法樣式。
單純地利用統計學習的方法主要透過歷史資料建模關聯性以此“猜測”未知資料,但是建模自然語言所需要的知識遠不止此。因此,本論文工作的目的就是結合人工智慧領域中統計學習和符號邏輯的方法進行情感分析任務。
模型
本論文首先設計了一種 LSTM 模型透過詞語替換髮現“動詞-名詞”概念原語(概念原語就是對常識概念的一種的抽象,概念“嘗”、“吞”、“啖”和“咀嚼”的原語都是“吃”。),為情感分析任務構建了一個新的三層知識表示框架 SenticNet5。
SenticNet5 建模了普遍關聯現實世界物件、行為、事件和人物的內涵和外延資訊,它不是盲目地依賴關鍵詞和詞語共現樣式,而是依賴關聯常識概念的隱含語意。
SenticNet5 不再單純地使用句法分析技術,同時透過分析短語關聯的概念,而不是短語本身(因為短語本身經常並不顯式地表達情感)挖掘微妙表達的情感。

▲ 圖1:背景關係語境向量和詞向量生成框架
本論文聲稱是情感分析應用中第一個提出結合符號邏輯和統計學習的方法。本論文的核心思想就是提出一種概念原語的,也就是使用一種自頂向下的方法泛化語意相關的概念,例如,“munch_toast”和“slurp_noodels”可以泛化成概念原語“EAT_FOOD”。這種做法背後核心的思想就是使用有限的概念上的原語描述包含情感資訊的概念。
本論文工作的第一步就是挖掘概念原語,具體模型如圖 1 所示,該模型的核心思想就是屬於相同原語下的概念詞語跟標的詞語在語意上關聯並且具有相似的背景關係語境。
舉個例子,句子“他剛剛咀嚼幾口粥”,這裡的“咀嚼”和“狼吐虎咽”屬於相同的概念原語“吃”,所以這裡的句子“狼吞虎嚥”代替“咀嚼”也說得通。
該模型左邊建模標的詞語的左背景關係和右背景關係合成標的詞語的背景關係語境表示,模型的右邊建模標的詞語的表示,基於這個模型就可以找到屬於同一原語的詞語,也就是講這些詞語聚類,然後人工標註原語。
 ▲ 圖2:原語“Intact”在語意網路圖Sentic5中的片段
▲ 圖2:原語“Intact”在語意網路圖Sentic5中的片段
因為 SenticNet5 是一個三層的語意網路(如圖 2 所示),原語層包含基本的狀態和行為(狀態之間的互動),包含狀態的情感資訊;概念層透過語意關聯連結的常識概念;物體層屬於常識概念的實體。
例如,在原語層,狀態“inact”對應情感“joy”和概念層上的形容詞概念“complete”,行為“break”對應動詞概念“crack”和“split”;在概念層,概念短語“repair_phone”對應概念“repair”和“phone”;同時概念“phone”又對應實體層上的“iPhone”。
這樣我們分析“iPhone”的時候雖然本身不包含情感資訊,但是跟“repair”在一起,“repair”對應狀態原語“fix”,“fix”又轉到正面的情感“intact”,因此“iPhone”就包含了正面的情感。
實驗
在實驗部分,本論文主要評估了深度學習方法的效能和 SenticNet5 作為知識庫在情感分析任務中的效果。從圖 3,4,5 的結果看來本論文的方法在兩個人物都有 3% 左右的提升。
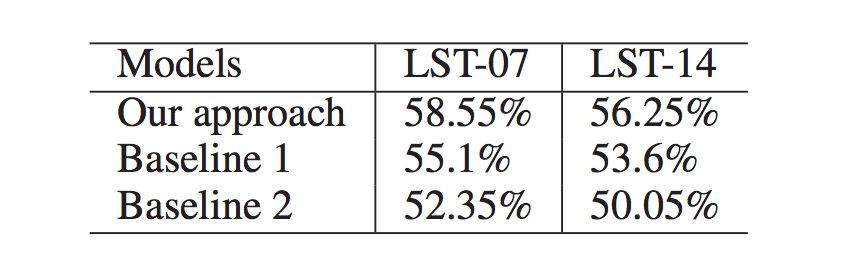 ▲ 圖3:對比現有方法和深度學習方法在原語識別上的效能
▲ 圖3:對比現有方法和深度學習方法在原語識別上的效能

▲ 圖4:SenticNet5在Biltzer資料集上情感分析的效能

▲ 圖5:SenticNet5在Movie Review資料集上情感分析的效能
AAAI 2018

■ 連結 | http://www.paperweekly.site/papers/1913
■ 原始碼 | https://github.com/TimDettmers/ConvE
■ 解讀 | 汪寒,浙江大學碩士,研究方向為知識圖譜和自然語言處理
本文主要關註 KG Link prediction 問題,提出了一種多層摺積神經網路模型 ConvE,主要優點就是引數利用率高(相同表現下引數是 DistMult 的 8 分之一,R-GCN 的 17 分之一),擅長學習有複雜結構的 KG,並利用 1-N scoring 來加速訓練和極大加速測試過程。
背景
一個 KG 可以用一個集合的三元組表示 G={(s,r,o)},而 link prediction 的任務是學習一個 scoring function \psi(x),即給定一個三元組 x=(s,r,o) ,它的 score \psi(x) 正於與 x 是真的的可能性。
Model ConvE

這是 ConvE 的整體結構,把輸入的物體關係二元組的 embedding reshape 成一個矩陣,並將其看成是一個 image 用摺積核提取特徵,這個模型最耗時的部分就是摺積計算部分。
為了加快 feed-forward 速度,作者在最後把二元組的特徵與 KG 中所有物體的 embedding 進行點積,同時計算 N 個三元組的 score(即1-N scoring),這樣可以極大地減少計算時間,實驗結果顯示,KG 中的物體個數從 100k 增加到 1000k,計算時間也只是增加了 25%。
ConvE 的 scoring function:

Loss function 就是一個經典的 cross entropy loss:

Test Set Leakage Problem
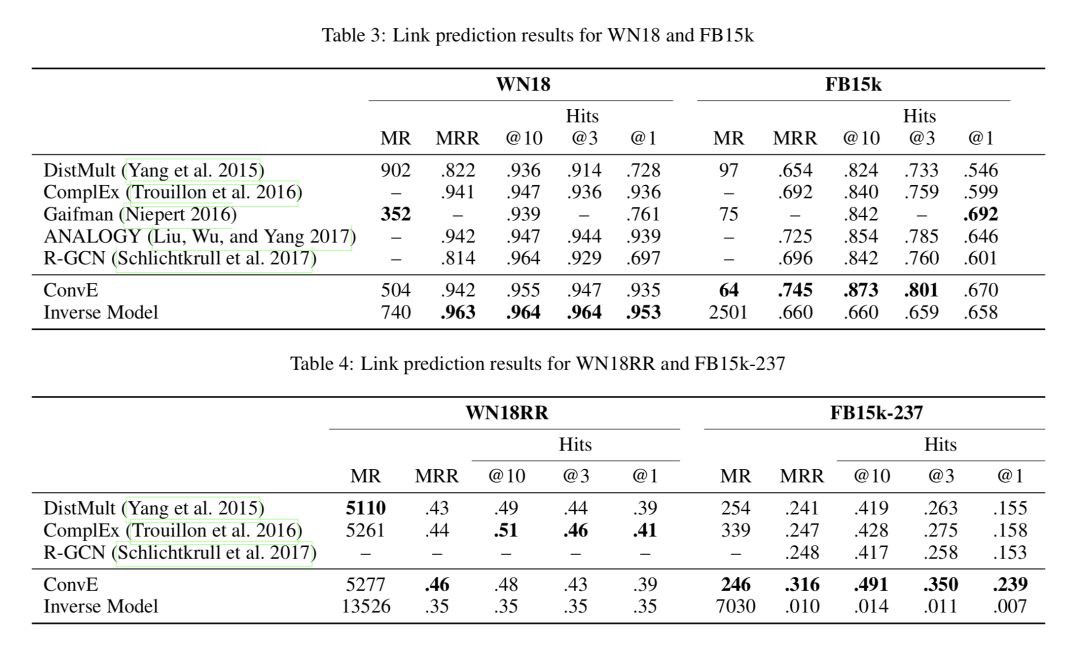
WN18 和 FB15k 都有嚴重的 test set leakage problem,即測試集中的三元組可以透過翻轉訓練集中的三元組得到,舉個例子,測試集中有 (feline, hyponym, cat) 而訓練集中有 (cat, hypernym, feline),這個問題的存在導致用一個很簡單的 rule-based 模型就可以在某些資料集上實現 state-of-the-art 效能。
作者構造了一個簡單的 rule-based inverse model 來衡量這個問題的嚴重性,並利用消去了 inverse relation 的資料集 WN18RR 和 FB15k-237 來進行實驗,實驗結果如下:
AAAI 2018

■ 連結 | http://www.paperweekly.site/papers/1914
■ 原始碼 | https://github.com/bxshi/ConMask
■ 解讀 | 李娟,浙江大學博士生,研究方向為知識圖譜和表示學習
本文解決知識庫補全的問題,但和傳統的 KGC 任務的場景有所不同。以往知識庫補全的前提是物體和關係都已經在 KG 中存在,文中把那類情況定義為 Closed-World KGC。從其定義可以發現它是嚴重依賴已有 KG 連線的,不能對弱連線有好的預測,並且無法處理從 KG 外部加入的新物體。
對此這篇文章定義了 Open-World KGC,可以接收 KG 外部的物體並連結到 KG。論文提出的模型是 ConMask,ConMask 模型主要有三部分操作:
1. Relationship-dependent content masking
強調留下和任務相關的詞,抹去不相關的單詞; 模型採用 attention 機制基於相似度得到背景關係的詞和給定關係的詞的權重矩陣,透過觀察發現標的物體有時候在權重高的詞(indicator words)附近,提出 MCRW 考慮了背景關係的權重求解方法。
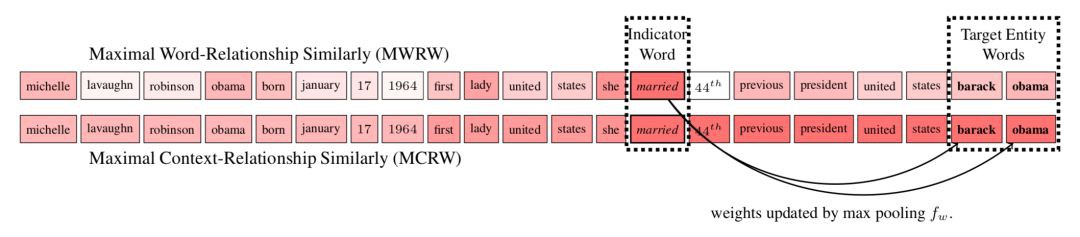
2. Target fusion
從相關文字抽取標的物體的 embedding(用 FCN 即全摺積神經網路的方法);這個部分輸入是 masked content matrix,每層先有兩個 1-D 摺積操作,再是 sigmoid 啟用函式,然後是 batch normalization,最後是最大池化。

為避免引數過多,在得到物體名等文字特徵時本文選用語意平均來得到特徵的 embedding 表示。
3. Target entity resolution
透過計算 KG 中候選標的物體和抽取的物體的 embedding 間的相似性,結合其他文字特徵得到一個 ranked list。本文設計了一個 list-wise ranking 損失函式,取樣時按 50% 比例替換 head 和 tail 生成負樣本,S 函式時 softmax 函式。

論文的整體模型圖為:

本文在 DBPedia50k 和 DBPedia500k 資料集上取得較好的結果,同時作者還添加了 Closed-World KGC 的實驗,發現在 FB15k,以及前兩個資料集上效果也很不錯,證明瞭模型的有效性。


▲ 戳我檢視招聘詳情
 #崗 位 推 薦#
#崗 位 推 薦#
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。


