作者丨左育莘
學校丨西安電子科技大學
研究方向丨計算機視覺
影象去噪是low-level視覺問題中的一個經典的話題。其退化模型為 y=x+v,影象去噪的標的就是透過減去噪聲 v,從含噪聲的影象 y 中得到乾凈影象 x 。在很多情況下,因為各種因素的影響,噪聲的資訊是無法得到的,在這樣的情況下進行去噪,就變成了盲去噪。
Image Blind Denoising With Generative Adversarial Network Based Noise Modeling 是中山大學和 CVTE 發表於 CVPR 2018 的工作,該文章透過利用 GAN 對噪聲分佈進行建模,並透過建立的模型生成噪聲樣本,與乾凈影象集合構成訓練資料集,訓練去噪網路來進行盲去噪。

很多去噪問題的解法,例如基於多種影象先驗資訊的方法,如 BM3D,可以透過結合 noise-level 估計演演算法來達到盲去噪的效果。但是,這些方法還是有很大的缺陷。
首先,在這些方法中的影象先驗資訊大多基於人類知識,因此影象的全部特徵就很難被捕捉到。第二,這些方法中絕大多數都是只用了輸入影象的內部資訊,沒有使用到任何的外部資訊,所以,還有很大的提升空間。
而基於已知噪聲資訊(noise-level)的影象去噪方法,特別是基於 CNN 的方法,對於已知高斯噪聲的資訊,這些方法可以達到 SOTA 水平。而且,這些方法不需要依靠人類對於影象的先驗資訊。但是這些方法在實際中很難派上用場。因為實際中我們得到一張影象,其中的噪聲資訊是未知的。
基於上面的分析,作者的思路:透過給定的含噪聲影象構建一個配對的訓練資料集,然後透過使用基於 CNN 的方法來進行盲去噪。
構建這樣一個資料集需要透過含噪聲的影象來對噪聲分佈進行建模,然後生成噪聲資料。實際上,前面的工作已經使用 GMM(高斯混合模型)來進行對噪聲的模擬。但是得到的噪聲資料並不是和觀測得到的噪聲十分相似,因此就需要一個更好的噪聲建模方法。
作者在本文中提出了一個新穎的兩步框架。首先,訓練 GAN 以估計輸入噪聲影象上的噪聲分佈並生成噪聲樣本。其次,利用從第一步取樣的噪聲塊來構建成對的訓練資料集,該資料集又用於訓練 CNN 以對給定的噪聲影象進行去噪。
網路結構
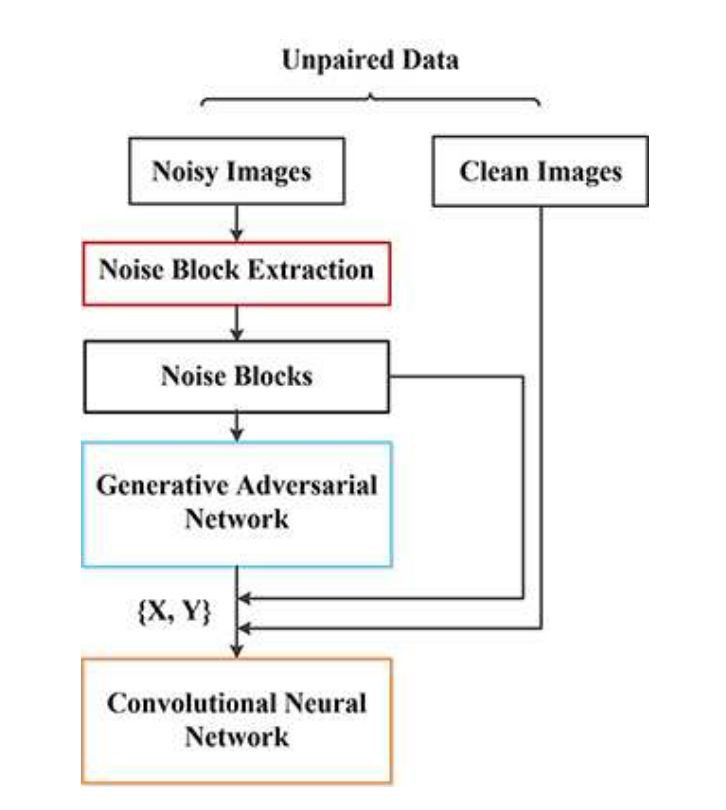
▲ GCBD方法
噪聲建模估計
文章假設需要處理的影象都含有同一型別的未知的均值為 0 的噪聲。然後,進行噪聲建模。
1. 提取噪聲影象塊
這是正確訓練 GAN 以模擬未知噪聲的重要步驟,因為噪聲分佈將從噪聲主導資料中更好地被估計。
為了減小原始背景的影響,需要從給定噪聲影象中具有弱背景的部分中首先提取一組近似噪聲塊(或塊),例如 V。
這樣,噪聲分佈成為 GAN 學習的主要標的,這可能使 GAN 模型更加準確。在噪聲分佈的期望為零的假設下,可以透過減去噪聲影象中相對平滑的 patch (smoothed patch) 的平均值來獲得近似的噪聲 patch。
這裡討論的 smoothed patch 指的是內部內容非常相似的區域。文中的數學定義即為 patch 中各部分的均值,方差在一個很小的範圍內波動。
-
以步長為 Sg 對整張含噪聲影象提取影象塊 Pi,其大小為 d × d;
-
以步長為 Sl 對影象塊 Pi 提取區域性影象塊
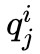 ,其大小為 h × h;
,其大小為 h × h; -
若對於 Pi 中所有的
,都滿足以下條件,就說明 Pi 為 smoothed patch,μ, γ∈(0,1)。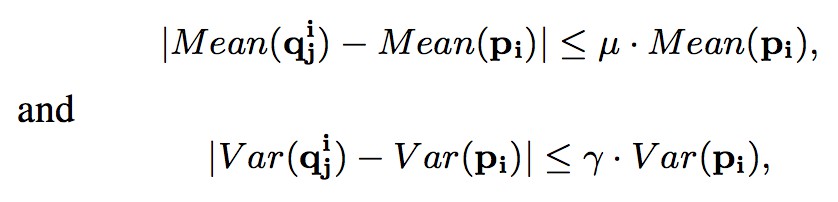
-
將每一個 smoothed patch 儲存到集合 S 中,然後各自減去各自的均值,就得到 noise patch 集合 V。
2. 利用GAN進行噪聲建模
利用剛才得到的 noise patch 集合,然後用 GAN 來對噪聲進行建模,透過建立的模型生成更多的噪聲資料。
在文章的方法中,GAN 是透過第一部得到的近似噪聲 patch 集合 V 來估計噪聲的分佈的。
由於 WGAN 可以改進 GAN 的訓練並生成高質量的樣本。因此,在文章的實驗中,WGAN-GP 是 WGAN 的改進版本,用於學習噪聲分佈。
這裡的 loss 函式為:
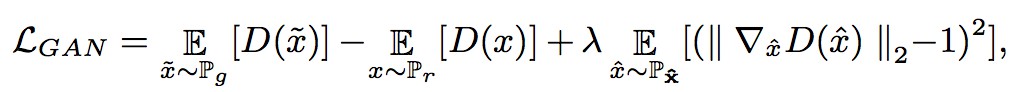
這裡的 Pr 表示 V 的資料分佈,Pg 是生成器生成資料的分佈。![]() 被定義為沿著 Pr 和 Pg 樣的點對之間的直線均勻分佈的取樣。
被定義為沿著 Pr 和 Pg 樣的點對之間的直線均勻分佈的取樣。
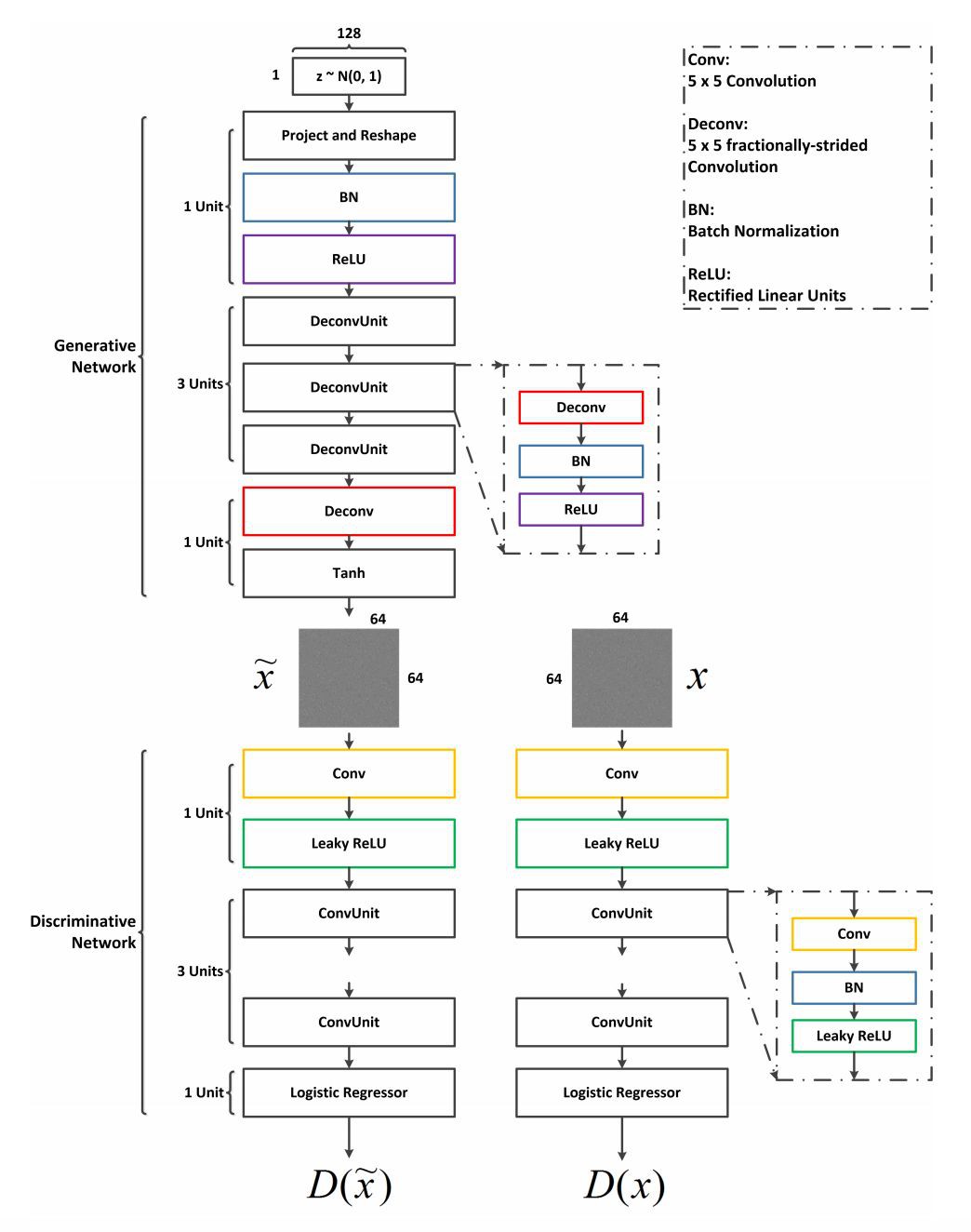
▲ GAN網路結構
作者採用類似於 DCGAN 的網路,訓練好的網路被用來生成噪聲樣本(增強集合 V)並最終得到集合 V’。
透過深度CNN進行去噪
許多以前的工作提出透過訓練具有大型資料集的 CNN 來解決去噪問題,並取得了令人矚目的成果。如前所述,CNN 可以隱含地從配對的訓練資料集中學習潛在噪聲模型,從而放鬆了對影象先驗的人類知識的依賴。因此,在文章的方法中使用 CNN 進行去噪。
為了訓練 CNN,首先需要構建一個配對的訓練資料集,從剛才得到的經過 GAN 擴充套件的 V’ 資料集,然後再從乾凈影象的資料集中透過影象分塊(patch 大小 d×d)的方法得到乾凈影象資料集 X。在 V’ 中的 noise block 隨機地加入到 X 中,得到集合 Y。其中有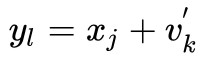 。然後透過集合 X 和 Y 構成配對資料集 {X,Y}。
。然後透過集合 X 和 Y 構成配對資料集 {X,Y}。
實際上,資料集是在訓練去噪網路的時候構建的。在每個 epoch,xj 和![]() 的組合都會改變,然後構成一個新的配對資料集 {X,Y’} 。
的組合都會改變,然後構成一個新的配對資料集 {X,Y’} 。
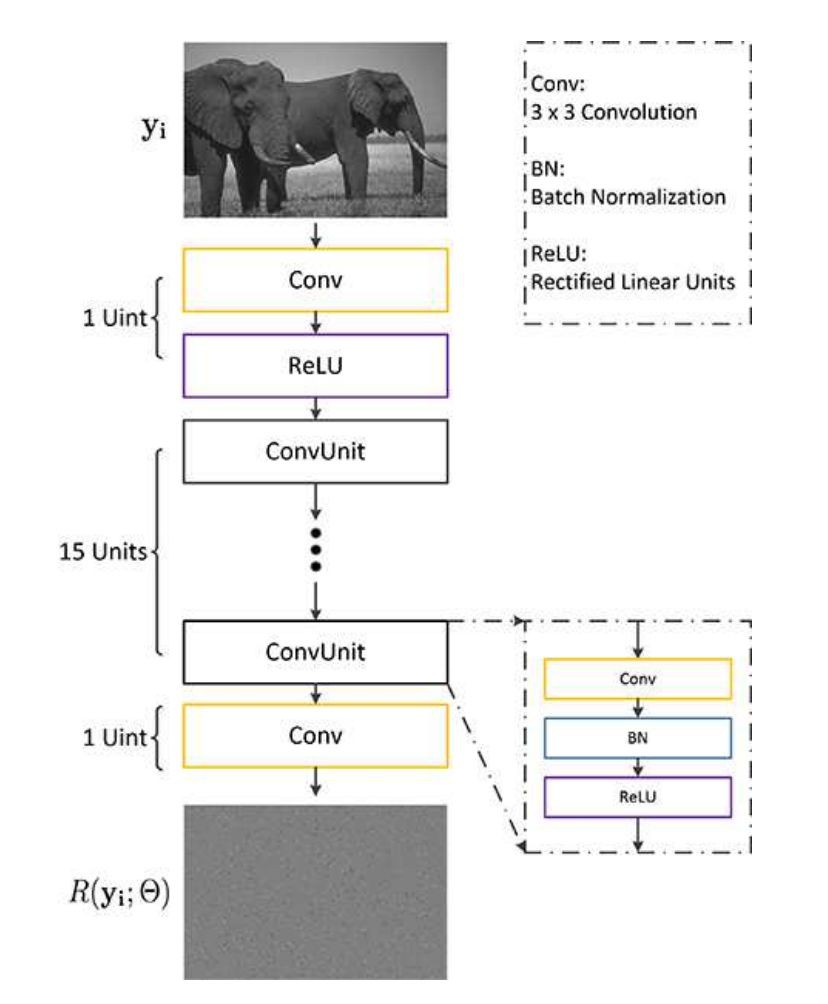
▲ 去噪網路
作者使用的網路結構類似於 DnCNN,CNN 被視為預測殘留影象的殘差單元,即輸入噪聲影象和潛在乾凈影象之間的差異。
損失函式為:
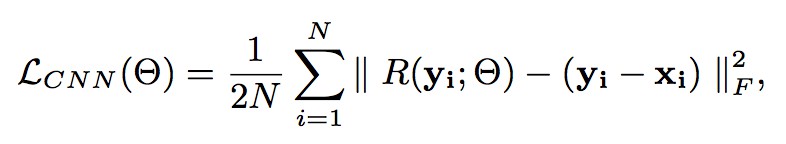
引數設定
d=64,h=32,Sg=32,Sl=16,μ=0.1,γ=0.25
GAN 的引數設定則參考的是 DCGAN 中的設定,DnCNN 則是以 lr=0.001,用 SGD 最佳化器訓練 50 個 epoch。
相關實驗
作者用合成噪聲影象和真實噪聲影象評估了 GCBD 方法,並對幾種代表性方法進行了比較,主要分為 4 部分:
1. 驗證 GAN 的噪聲建模效果,GCBD 和一些 SOTA 的方法進行比較,特別是一些基於判別學習的方法(像 DnCNN),從高斯盲去噪方面進行比較;
2. GCBD 可以處理比高斯噪聲更複雜的噪聲,利用混合噪聲進行實驗;
3. 真實影象去噪實驗;
4. 對噪聲建模的一些討論,說明選擇 GAN 而不是傳統方法(GMM)的原因。
實驗資料
Test set:BSD68
真實影象:DND 資料集,NIGHT 資料集(25 張夜間高解析度含噪聲影象)
用於構建配對資料集的乾凈影象集:CLEAN1
為了模擬實際處理大量影象資料的情況,將噪聲新增到另一組高解析度乾凈影象集(CLEAN2)以在合成資料的評估中形成用於 GCBD 的輸入噪聲影象(測試泛化能力) 。
實驗結果
1. 高斯盲去噪與合成噪聲去噪
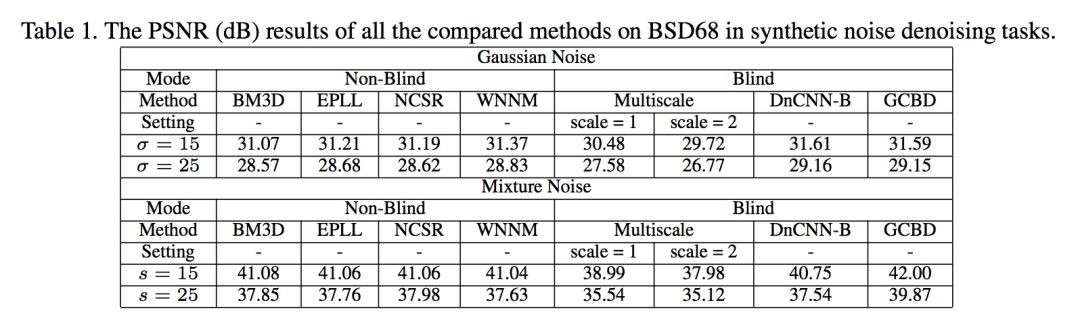
▲ 高斯盲去噪以及混合噪聲去噪結果
可以看到在高斯盲去噪方面,文章提出的方法 GCBD 和 DnCNN 不相上下,而在合成噪聲去噪方面,GCBD 則達到了最高水平。文中所用到的混合噪聲為 10% 的均勻分佈噪聲(分佈區間為[-s,s]),20% 的高斯噪聲(N(0,1)),70%的高斯噪聲(N(0,0.01)。
2. 真實影象去噪
DND資料集實驗結果
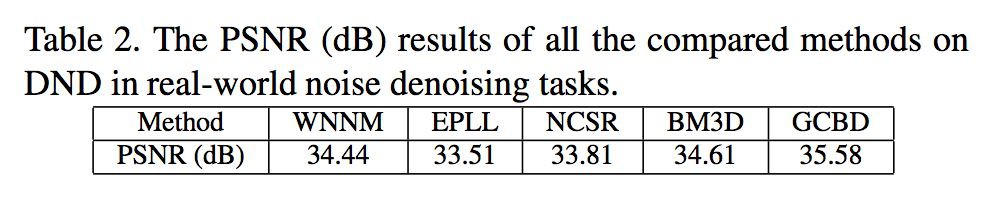
▲ 真實影象去噪結果
NIGHT資料集實驗結果
因為 NIGHT 資料集沒有 GT,所以之後能透過視覺效果進行衡量。

▲ NIGHT資料集實驗結果
視覺效果上看,GCBD 達到了最佳的效果,在保留影象資訊的情況下,去除了噪聲。
3. 選擇GAN而不是GMM的原因
對於真實含噪聲影象而言,GMM 對噪聲估計的效果並沒有 GAN 好,如圖所示:

▲ 噪聲估計結果
可以看到利用 GAN 估計的噪聲比 GMM 估計的噪聲更接近與真實影象噪聲。作者認為原因是 GMM 中高斯模型的數量以及顯式地對噪聲進行建模會限制 GMM 的估計能力,而 GAN 則是隱式地對噪聲進行估計,所以效果會更好一些。
4. 利用GAN生成噪聲樣本的效果
作者透過實驗發現利用 GAN 生成更多噪聲資料的方法能提升效能(高斯盲去噪提升 0.34dB,混合噪聲去噪提升 0.91dB)。作者認為原因是隻對提取的噪聲塊直接進行訓練的話,資料缺少多樣性,而利用 GAN 生成更多噪聲資料則彌補了這一缺陷。
總結
這篇文章針對影象盲去噪任務,透過利用 GAN 學習噪聲的分佈,並生成更多的噪聲資料來生成訓練資料集對 CNN 進行訓練,得到的影象盲去噪效果達到了 SOTA 水平。