


-
從入口層(CDN)—> 到安全層(WAF) —> 最後到達應用層 (ECS叢集);
-
Docker Swarm打通了ECS叢集中的每臺伺服器,在每臺ECS宿主機安裝Docker engine並部署了公司需要的應用服務和資料庫(Nginx、PHP、Redis、MySQL等);
-
MySQL容器透過宿主機的本地(目錄)掛載到容器中實現資料持久化;
-
業務專案以PHP為主,PHP也是執行在容器中,透過PhP指定的配置檔案連線到MySQL容器中。
version: "3"
services:
ussbao:
# replace username/repo:tag with your name and image details
image: 隱藏此映象資訊
deploy:
replicas: 1
restart_policy:
condition: on-failure
environment:
MYSQL_ROOT_PASSWORD: 隱藏此資訊
volumes:
- "/data//mysql/db1/:/var/lib/mysql/"
- "/etc/localtime:/etc/localtime"
- "/etc/timezone:/etc/timezone"
networks:
default:
external:
name: 隱藏此資訊

-
根據業務量規劃開通RDS實體,建立資料庫和使用者;
-
提前做好RDS白名單,新增允許訪問RDS的IP地址;
-
mysqldump備份Docker中的MySQL;
-
把備份好的.sql檔案匯入到RDS中;
-
修改PHP專案的資料庫配置檔案;
-
清空PHP專案的快取檔案或目錄;
-
測試驗證;
-
RDS定時備份;
#!/bin/bash
資料庫IP
dbserver='*******'
資料庫使用者名稱
dbuser='ganbing'
資料庫密碼
dbpasswd='************'
備份資料庫,多個庫用空格隔開
dbname='db1 db2 db3'
備份時間
backtime=`date +%Y%m%d%H%M`
out_time=`date +%Y%m%d%H%M%S`
備份輸出路徑
backpath='/data/backup/mysql/'
logpath=''/data/backup/logs/'
echo "################## ${backtime} #############################"
echo "開始備份"
日誌記錄頭部
echo "" >> ${logpath}/${dbname}_back.log
echo "-------------------------------------------------" >> ${logpath}/${dbname}_back.log
echo "備份時間為${backtime},備份資料庫 ${dbname} 開始" >> ${logpath}/${dbname}_back.log
正式備份資料庫
for DB in $dbname; do
source=`/usr/bin/mysqldump -h ${dbserver} -u ${dbuser} -p${dbpasswd} ${DB} > ${backpath}/${DB}-${out_time}.sql` 2>> ${backpath}/mysqlback.log;
#備份成功以下操作
if [ "$?" == 0 ];then
cd $backpath
#為節約硬碟空間,將資料庫壓縮
tar zcf ${DB}-${backtime}.tar.gz ${DB}-${backtime}.sql > /dev/null
#刪除原始檔案,只留壓縮後檔案
rm -f ${DB}-${backtime}.sql
#刪除15天前備份,也就是隻儲存15天內的備份
find $backpath -name "*.tar.gz" -type f -mtime +15 -exec rm -rf {} \; > /dev/null 2>&1
echo "資料庫 ${dbname} 備份成功!!" >> ${logpath}/${dbname}_back.log
else
#備份失敗則進行以下操作
echo "資料庫 ${dbname} 備份失敗!!" >> ${logpath}/${dbname}_back.log
fi
done
echo "完成備份"
echo "################## ${backtime} #############################"










-
在經常查詢而不經常增刪改操作的欄位加索引。
-
order by與group by後應直接使用欄位,而且欄位應該是索引欄位。 一個表上的索引不應該超過6個。
-
索引欄位的長度固定,且長度較短。
-
索引欄位重覆不能過多,如果某個欄位為主鍵,那麼這個欄位不用設為索引。
-
在過濾性高的欄位上加索引。
-
使用like關鍵字時,前置%會導致索引失效。
-
使用null值會被自動從索引中排除,索引一般不會建立在有空值的列上。
-
使用or關鍵字時,or左右欄位如果存在一個沒有索引,有索引欄位也會失效。
-
使用!=運運算元時,將放棄使用索引。因為範圍不確定,使用索引效率不高,會被引擎自動改為全表掃描。
-
不要在索引欄位進行運算。
-
在使用複合索引時,最左字首原則,查詢時必須使用索引的第一個欄位,否則索引失效;並且應儘量讓欄位順序與索引順序一致。
-
避免隱式轉換,定義的資料型別與傳入的資料型別保持一致。
-
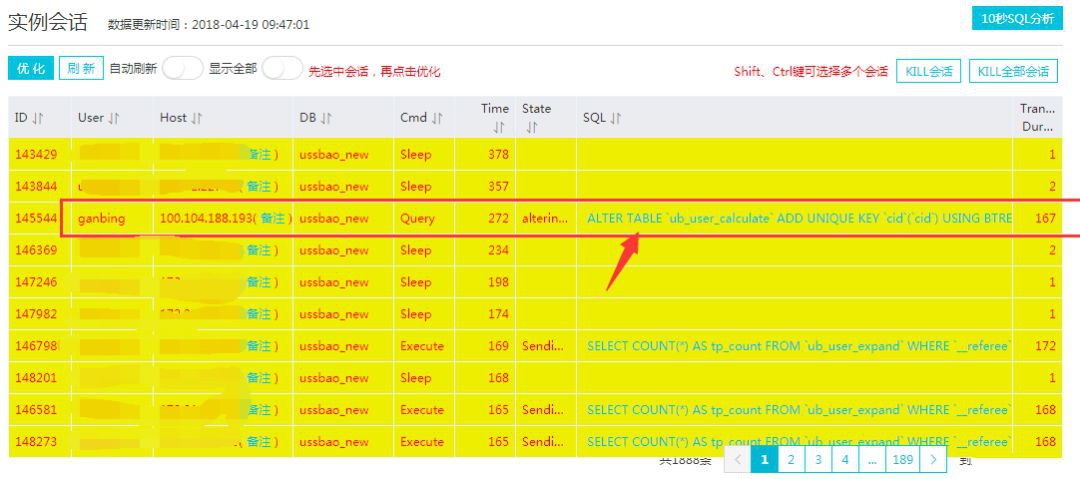
此次故障雖然是表沒有索引造成的,但是筆者是有責任的,沒有挨個表檢查一下表的結構;
-
透過此次故障也可以看出來開發在設計表的真的要非常的重視,註意細節;
-
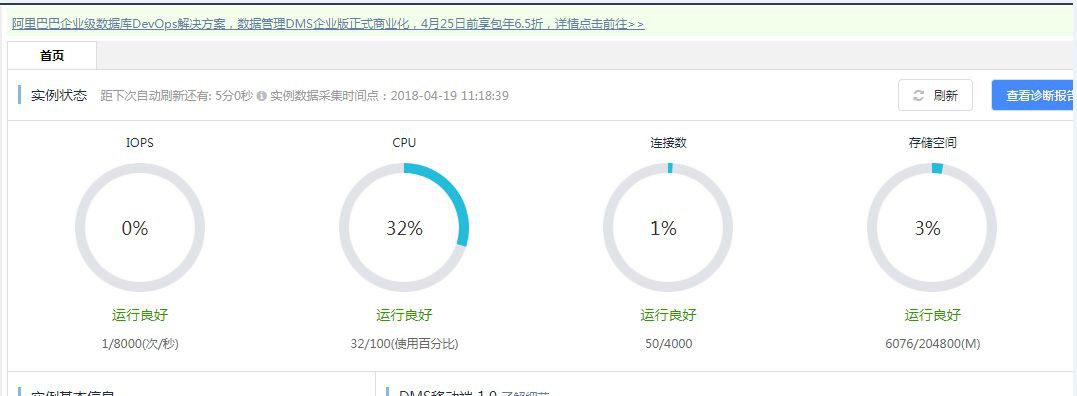
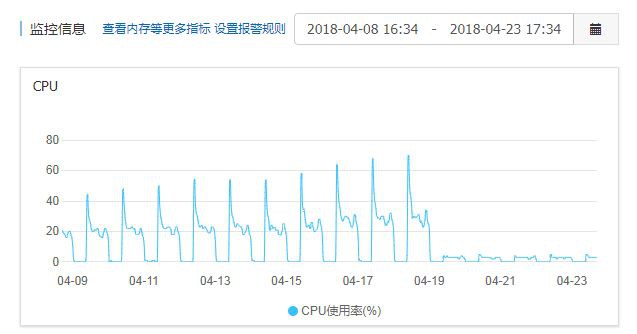
還有就是之前在容器中執行的MySQL也時不時的出現CPU瓶頸(比如CPU使用率偶爾會達到80%以上),筆者應該就要提前發現這些問題,徹底排查找出問題所在原因在進行遷庫的操作。


