
導讀:在當前複雜的零售環境下,選址對於零售企業而言變得格外重要,因為位置就是線下流量的直接入口。本文將從三個維度來為大家揭曉如何透過地理方法解決選址問題?融合機器學習的智慧地圖如何賦能商業選址?
1.0時代:地理視覺化
1.0時代即通常所說的資料上圖,將資料投放至地圖上,用地理視覺化的方式展現出來。

佳通輪胎是我接觸這一行業所做的第一個專案,這一專案對於現在而言能輕而易舉地做到並且能夠做得更好但對當時而言則較為複雜。
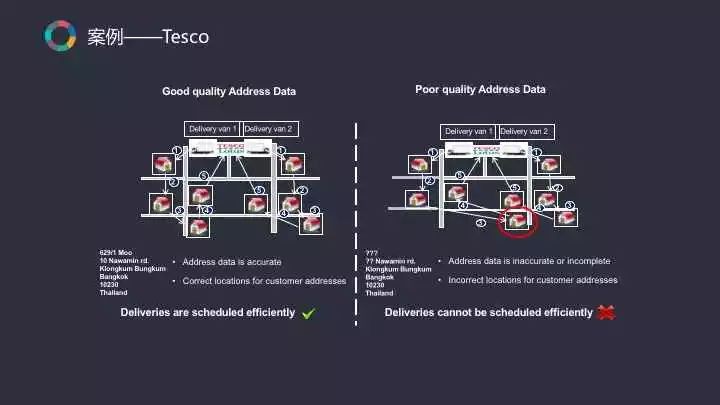
在視覺化1.0時代,Tesco走在行業前端,已經開始用地理視覺化的方式做選址。使用者只需在其線上商城註冊賬號後輸入自己的地址,系統後臺便會將使用者分配到他所屬的門店。但這對地理編碼的精度要求特別高,假設你的地址定位不準確就會影響後續的整個配送路徑。
在選址之前需對現有門店進行較深的認知,以麥當勞商圈調查為例,在選址之前需要對已經開業的門店做很多商業調研,將這些收集回來的資料呈現在地圖上,目的是幫助他們瞭解其客戶,這些客戶分佈在哪裡?

上圖每一個格子代表客戶百分比,顏色越深就代表這個地方的客戶越多。可以發現,大部分客戶都來自於離店鋪越近的地方,越遠的地方它的顏色越淺。另外還可以發現這家店的商圈大小,商圈的範圍是80%的客戶所分佈的範圍。透過調研的方式計算出80%的客戶分佈哪些範圍以內?另外還能瞭解有哪些因素會影響到商圈的大小及形狀。比如在上圖的右下角為一個高等級道路,可以發現在道路上方集中了大部分客戶,而在道路下方並沒有很多客戶,那就說明高等級道路是影響商圈形狀的重要因素。透過這種方式還能得到其他認知,例如河流也是影響商圈形狀的一個因素。

再以樂天瑪特為例,他的需求是根據會員分佈結合人口資料幫助其制定DM投放策略。例如人口多、會員較少的區域或是會員多、購買頻率較低的區域都是需要重點關註的地方,如上圖右上角圈出來的紅色區域,它就是DM投放重點關註的區域。
當我們有了會員資料之後,繼續把會員的消費金額、消費頻次投放到地圖之上,幫助他們安排接送車及站點分佈。如在銷售額貢獻大的區域增加站點等。
在地理視覺化1.0時代,阿迪達斯是一個較為特殊的案例。
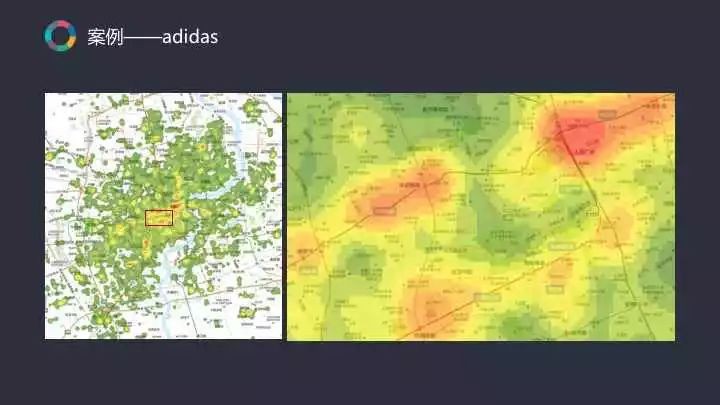
一直到現在為止,收集商圈市場容量資料是較難的一件事情。但我們透過可以獲取到的POI資料模擬商圈的市場潛力以達到發現其市場容量的目的。對於某些大家熟悉的大城市如上海而言,所有人都能大致瞭解其核心商圈。但我們的最終目的是幫助商戶瞭解二三線城市,甚至是四線城市。當對這個城市不夠瞭解時,如何挑選品牌應該進入的區域?這就是阿迪達斯服務案例解決的問題。
2.0時代:分析與流程
2.0時代是如今大部分企業所處的一個階段。由於資料量急劇上升,我們需要針對這種大資料做分析,從1.0時代針對單個點解決具體問題,上升至2.0時代幫助企業建立流程進而處理選址過程中可能面臨的一些問題。

以上汽為例,在收集了新能源車輛的的行車軌跡資料後,提前制定好使用者標簽從而制定出使用者畫像,汽車廠商就會根據這些標簽找到一些異業聯盟。例如這一品牌的客戶經常會去某個購物中心,那麼就可將車放在這個購物中心供潛在的客戶試駕,這也就是一個潛在的獲取客戶的渠道。
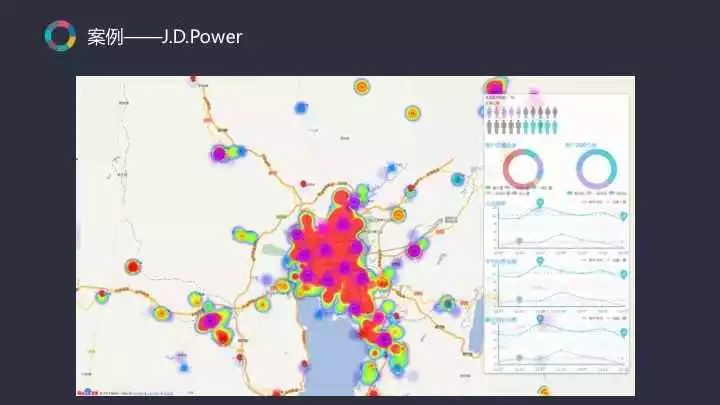
再以JDPower所做的會員管理系統為例。根據客戶的到店頻次、消費金額以及最近到店消費時間,將會員劃分成不同等級,如高價值客戶、低價值客戶、高風險客戶、低風險客戶等,針對不同的客戶型別進行不同的營銷策略。在此平臺基礎上,還可以互動地針對某一區域的客戶做營銷。透過對會員更深入的分析,幫助他們更好地制定一個選址策略。

以極海和某銀行的合作平臺為例,對於現階段而言,增加網點並不是銀行主要的目的,而是透過系統的層次建立一個流程,對網點進評估,針對不同的網點從資料的角度制定開、停、並、轉的決策。
3.0時代:機器學習輔助決策
從去年開始就有很多企業慢慢在選址策略上應用機器學習的方式。這裡引入自然街區這一概念。

自然街區是規劃裡的一個概念,將它應用到零售選址這一行業中代替原先的網格方式。網格方式最大的缺點在於網格可能會橫跨一條路、改寫了兩個小區,這樣就有可能出現一種分歧。假設一個小區是公寓,一個小區是別墅,那麼這兩個小區的人其實是沒有同質性可言的。為瞭解決這一問題,我們引入自然街區的方式。
沿街道、河流等天然屏障劃分的自然街區對此就具有天然優勢,因為各等級街道是人口的隔離和聚攏的自然表現,小巷衚衕可以把附近的人聚攏在一塊,高速路和主幹道卻把一塊地切割成比較獨立的活動區域,這種符合情理的劃分方式會為各種各樣的分析提供可靠性上的保障。
生成自然街區之後,將所有的資料基於這個統計單元做出分析。對每一個區塊做出區分,打上標簽,如辦公區、大學城、購物中心等。
不同的零售業態關註的型別是不一樣的,如高檔的化妝品關註購物中心,而像麥當勞、肯德基則更關註居民區、商業街等人流更為集中的地方。

在美國,資料的完整度是非常好的,他可以做到對每一個街區定一個類別,假設這個街區叫做Milk and Cookie,那在這個街區生活的人則是中產階級有孩子的家庭,這一家庭平均兩三個人住在獨棟的房子中。有了這樣的分析結果後,就能在選址的時候做出很明確的標的。
但是來到國內後發現資料沒有這麼好的完整度,這就意味著你很難說清每個街道住的人都是怎樣的檔次,其消費能力如何?因此我們的解決方案是將會員資料投放至自然街區上,每一個自然街區有相對應的會員數,會有各維度統計而來的資料,透過機器學習的方式瞭解哪些因素對它有正向作用,經過不斷的學習和迭代後,預測每塊區域中可能會帶來多少潛在會員。

這是在2016年我們給北京一個做房地產的房產中介公司推出的自動報告的工作平臺。根據每個月更新的資料,機器會自動利用30多大類資料做400多項小指標的運算,生成一份一百多頁的PPT報告,而且整個過程就用一分鐘。我們把北京分成了兩千多個自然街區,在一分鐘之內就能同時出兩千份一百頁的PPT投策報告。我們希望跟房地產公司等各行業的客戶合作,透過這些新技術,把他們從以前不熟悉的技術工作中解脫出來。讓他們把自己更多的精力,投入到他們更擅長的專業裡去,真正做到術業有專攻、共贏,提高他們的工作效率,也同時大大的促進他們的工作成果。
我們希望搭建一個一站式雲平臺幫助使用者解決一些他們不需要關註的問題,如資料安全問題、服務問題、模型問題,在這個平臺環境下,幫助使用者盡可能提供現成資料,在資料基礎上搭建常見應用,所有的資料和應用利用API、SDK的方式封裝起來,能夠在這個基礎上做一些更複雜的應用場景。
在平臺上可以支援不同資料源、不同維度、不同格式的資料。另外公共資料也是非常重要的資料,目前極海團隊會定期更新和處理大量的資料。針對大資料如何做視覺化這一問題,我們採用了雲端與前端相結合的方式,在後端對資料進行切片渲染,推送到前端進行視覺化。
但現在企業自己內部的業務資料越來越多,外部的多源的資料獲取也越來越容易,價格越來越便宜。我們怎麼把這些多源的大資料進行整合,是否能真正有效的挖掘他們的價值?根據這些資料能否做出預測?這個是我們有了人工智慧才敢想的。很慶幸,我們極海的小夥伴們,對人工智慧的演演算法很早就非常的痴迷。
我們高效整合了內外網豐富的位置資料、商業資料、政府公開資料,採用機器學習技術提高資料質量並生產更多獨有的資料。生產基於各種地理資料的深度學習模型,諸如交通分析、客源分析等大資料分析方法,透過這些資料和方法可以對街區中的使用者群進行精細分析,高效調查區域內數以萬計的使用者群。
這所有的資料和分析方法,都被封裝到一個資料容器內方便使用提取,這個容器,我們稱之為“城市基因”,猶如生物研究的DNA一般,幫助精細精準地描述城市,為解決店鋪選址,提供豐富、高質量的資料基礎。

基於城市基因,我們能夠輕鬆搭建面向行業應用的服務平臺,如與IBM合作的平臺 Metro Pulse。

這一階段的雲平臺基本可以滿足到2.0需求,在未來會有更多的新技術加入這一平臺。
作者:何宇兵
來源:DT資料俠(ID:DTdatahero)
推薦閱讀
日本老爺爺堅持17年用Excel作畫,我可能用了假的Excel···
Q: 好了,現在你發現開店發財的秘密了嗎?
歡迎留言與大家分享
覺得不錯,請把這篇文章分享給你的朋友
轉載 / 投稿請聯絡:baiyu@hzbook.com
更多精彩文章,請在公眾號後臺點選“歷史文章”檢視

