作者丨朱政
學校丨中科院自動化所博士生
單位丨商湯科技
研究方向丨視覺標的跟蹤及其在機器人中的應用
本文主要介紹我們發表於 CVPR 2018 上的一篇文章:一種端到端的光流相關濾波跟蹤演演算法。據我們所知,這是第一篇把 Flow 提取和 tracking 任務統一在一個網路裡面的工作。
■ 論文 | End-to-end Flow Correlation Tracking with Spatial-temporal Attention
■ 連結 | https://www.paperweekly.site/papers/1825
■ 作者 | Zheng Zhu / Wei Wu / Wei Zou / Junjie Yan
論文動機
首先是 motivation,近兩年 DCF+CNN 的 tracker 在 tracking 的社群裡面一直是標配,但我們註意到幾乎所有的 tracker 都只用到了 RGB 資訊,很少有用到影片幀和幀之間豐富的運動資訊,這就導致了 tracker 在標的遇到運動模糊或者部分遮擋的時候,performance 只能依靠離線 train 的 feature 的質量,魯棒性很難保證。
於是我們就想利用影片中的運動資訊(Flow)來補償這些情況下 RGB 資訊的不足,來提升 tracker 的 performance。
具體來說,我們首先利用歷史幀和當前幀得到 Flow,利用 Flow 資訊把歷史幀 warp 到當前幀,然後將 warp 過來的幀和本來的當前幀進行融合,這樣就得到了當前幀不同 view 的特徵表示,然後在 Siamese 和 DCF 框架下進行 tracking。

▲ FlowTrack整體框架
上面是我們演演算法的整體框架,採用 Siamese 結構,分為 Historical Branch 和Current Branch。
在 Historical Branch 裡面,進行 Flow 的 提取 和 warp,在融合階段,我們設計了一種 Spatial-temporal Attention 的機制(在後面敘述)。
在 Current Branch,只提取 feature。Siamese 結構兩支出來的 feature 送進 DCF layer,得到 response map。
總結來說,我們把 Flow 提取、warp 操作、特徵提取和融合和 CF tracking 都做成了網路的 layer,端到端地訓練它們。
技術細節
下麵是一些技術細節,採用問答方式書寫。
問:warp 操作是什麼意思,怎麼實現的?
答:warp 具體的推導公式可以參見 paper,是一種點到點的對映關係;實現可以參見 DFF 和 FGFA 的 code,略作修改即可。
問:Flow 提取和訓練是怎麼實現的?
答:我們採用的是 FlowNet1.0 初始化,然後在 VID 上面訓練,訓練出來的 Flow 質量更高,對齊地更好;未來我們會換用 FlowNet2.0 或者速度更快的 Flow 網路,爭取在速度和精度上有所提升。
問:融合是怎麼實現的?
答:在融合階段,我們我們設計了一種 Spatial-temporal Attention 的機制。在 Spatial Attention 中,是對空間位置上每一個待融合的點分配權重,具體採用餘弦距離衡量(公式可以參見 paper),結果就是和當前幀越相似分配的權重越大,反之越小。
這麼做的問題是當前幀的權重永遠最大,所以我們借鑒 SENet 的思想進而設計了 temporal attention,即把每一幀看做一個 channel,設計一個質量判斷網路:

▲ Temporal Attention的圖示
網路輸出的結果是每一幀的質量打分,質量高的幀分數高,質量低(比如部分遮擋)的幀分數低:

▲ Temporal Attention的結果
Temporal Attention 和前面的 Spatial Attention 結合起來,就可以對 warp 之後的 feature map 和當前幀本身的 feature map 進行融合。
問:DCF 操作怎麼做成 layer?
答:這個在 CFNet 和 DCFNet 裡面具有闡述,paper 裡面也做了簡單的總結。
問:paper 裡面 warp 的幀數是怎麼選定的?
答:透過實驗確定,實驗結果如下:

▲ warp幀數的選擇
問:最後在 OTB 和 VOT 的實驗結果怎麼樣?
答:OTB2015 AUC 分數 0.655;VOT2016 EAO 分數 0.334(超過 CCOT),速度 12FPS(是 CCOT 的 40 倍),當然,和 ECO 還是有精度上的差距。結果圖可以參見下麵:

▲ OTB2015的實驗結果
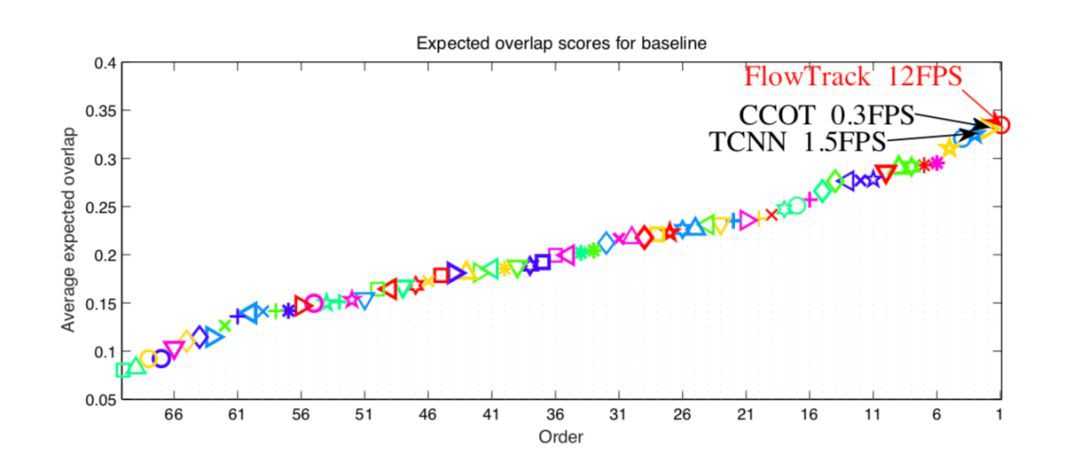
▲ VOT2016的EAO Ranking
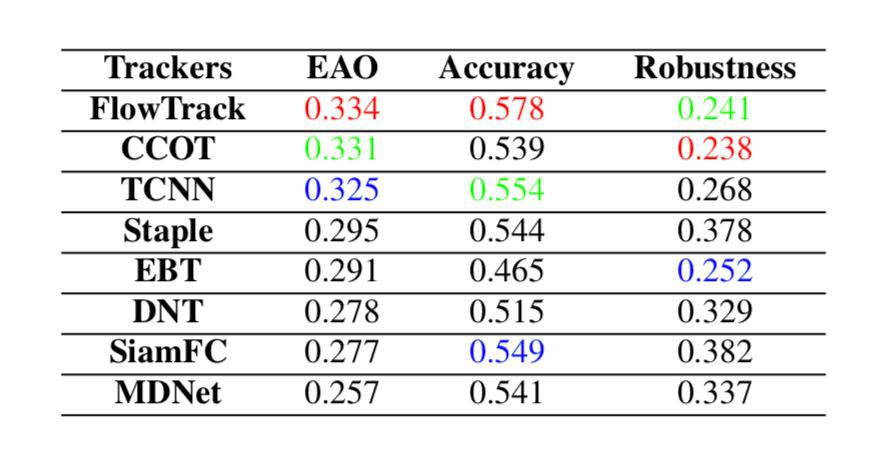
▲ VOT2016上面具體的accuracy和robustness
為了完整起見,補充一下 OTB2013 和 VOT2015 的結果:

▲ VOTB2013實驗結果
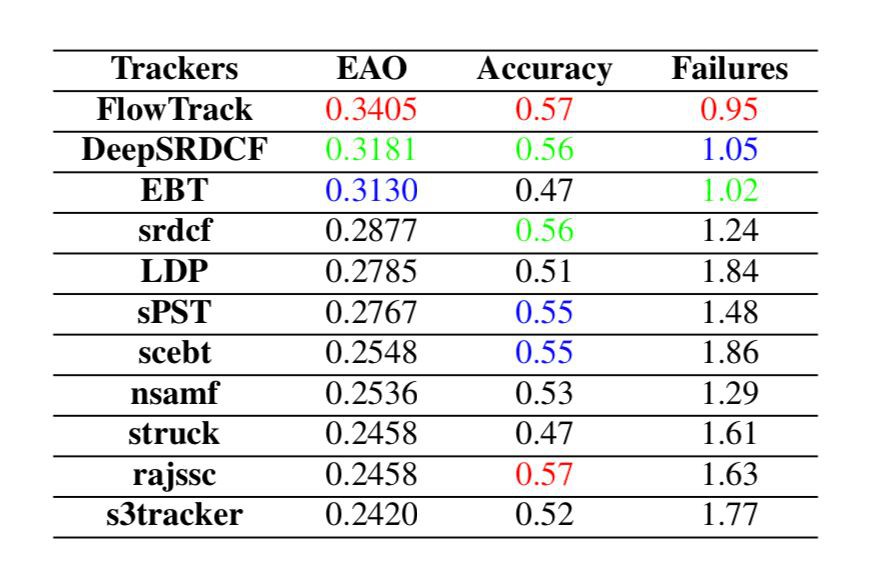
▲ VOT2015上面具體的accuracy和robustness

▲ VOT2015 EAO Ranking
問:網路中元素比較多,究竟哪一塊在 work?
答:我們做了 ablation 分析,結果如下,值得註意的是加入固定的光流資訊之後,某些資料集上的 performance 反而下降了;我們估計是由於光流資訊的(不高的)質量和(不太)對齊造成的。

▲ ablation分析,FlowTr是完整的FlowTrack,其餘從上到下分別是:不用Flow資訊的,用Flow資訊但不進行端到端訓練的,用time-decay方式進行融合的,不用temporal attention的
問:為什麼選擇 warp 的幀間隔是 1 而不是 2,4,8 這種,這樣的話不是更能包含更多的 temporal information 嗎?比如更長時間的遮擋的時候似乎更 work?
答:我們試了幀間隔為 1,2,4 的方案,當幀間隔為 2 和 4 的時候(即 warp t-2,t-4… 或者 t-4,t-8…),雖然在某些情況(比如遮擋)能取得更好的結果,但整體效能是下降的。
我們猜測是由於幀間隔大了之後,Flow 資訊的質量可能會變差(畢竟 FlowNet 是針對小位移的)。
問:fixed Flow 和訓練之後的 Flow 有什麼區別?
答:訓練之後的 Flow 相比較固定的 FlowNet 提取出來的 Flow,質量更高,對齊地更準,一個例子如下圖:

▲ 左列:待輸入 Flow 網路的兩張圖;中列:固定的 FlowNet 和訓練之後的 Flow 網路提取的 Flow;右列:Flow mask 到原圖(註意:都是 mask 到左下角的圖上)。
問:和 ICPR 那一篇 Deep Motion Feature for Visual Tracking 那一篇結果對比怎麼樣?
答:OP 指標可以超過,速度比他快很多(他的速度不包含提取 Flow 的時間),見下表:

▲ 和ICPR文章的對比
問:在 VOT2017 上面的結果怎麼樣?
答:還不錯,EAO 目前可以排名第二,見下圖:

▲ VOT2017結果

點選檢視更多CVPR 2018論文解讀:

▲ 戳我檢視招聘詳情
 #崗 位 推 薦#
#崗 位 推 薦#
關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 進入作者知乎專欄