
作者:naughty
Kubernetes已經成為容器編排的事實上的王者,連Docker都已經向K8s女王大人低頭。對於Kubernetes的cluster的資料收集和監控已經成為IT運維的一個重要話題。我們今天來看一看如何利用Splunk最新的Metrics Store來對Kubernetes的叢集進行效能監控。
部署架構
下圖是該方案的部署架構,主要包括:
-
利用Heapster收集K8s的效能資料,包含CPU,Memory,Network,File System等
-
利用Heapster的Statsd Sink,傳送資料到Splunk的Metrics Store
-
利用Splunk的搜尋命令和儀錶盤功能對效能資料進行監控

前期準備
前期主要要準備好兩件事:
-
編譯最新的Heapster的映象,並上傳到某個公共的Docker映象倉庫,例如docker hub
-
在Splunk中配置Metrics Store和對應的網路輸入(Network Input UDP/TCP)
這裡主要要做的選擇是Statsd的傳輸協議用UDP還是TCP。這裡我推薦使用TCP。 最新的Heapster程式碼支援不同的Backend,包含了log, influxdb, stackdriver, gcp monitoring, gcp logging, statsd, hawkular-metrics, wavefront, openTSDB, kafka, riemann, elasticsearch等等。因為Splunk的Metrics Store支援statsd協議,所以可以很容易的和Heapster整合。
首先我們需要利用最新的heapster程式碼,編譯一個容器映象,因為docker hub上的heapsterd的官方映象的版本比較舊,並不支援statsd。所以需要自己編譯。
mkdir myheapster
mkdir myheapster/src
export GOPATH=myheapster
cd myheapster/src
git clone https://github.com/kubernetes/heapster.git
cd heapster
make container
執行以上的命令來編譯最新的heapster映象。
註意,heapster預設使用udp協議,如果想要使用tcp,需要修改程式碼
https://github.com/kubernetes/heapster/blob/master/metrics/sinks/statsd/statsd_client.go
func (client *statsdClientImpl) open() error {
var err error
client.conn, err = net.Dial("udp", client.host)
if err != nil {
glog.Errorf("Failed to open statsd client connection : %v", err)
} else {
glog.V(2).Infof("statsd client connection opened : %+v", client.conn)
}
return err
}
把udp改成tcp。
我在docker hub上放了兩個映象,分別對應udp版本的tcp版本,大家可以直接使用
-
naughtytao/heapster-amd64:v1.5.0-beta.3 udp
-
naughtytao/heapster-amd64:v1.5.0-beta.4 tcp
然後需要在Splunk中配置Metrics Store,參考這個檔案
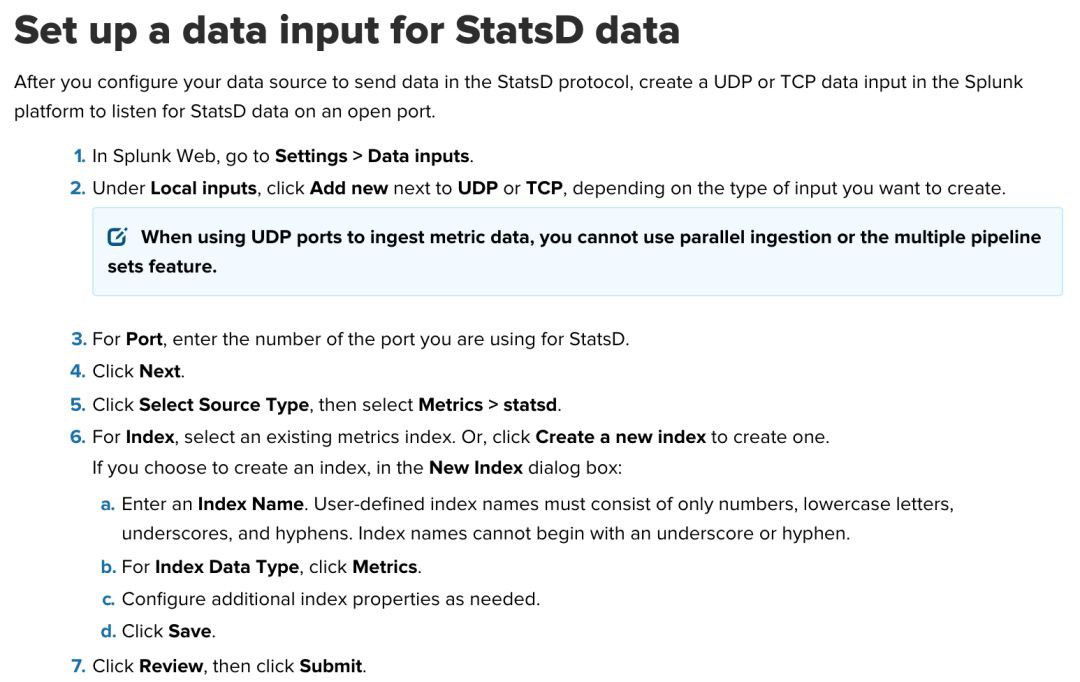
安裝配置Heapster
在K8s上部署heapster比較容易,建立對應的yaml配置檔案,然後用kubectl命令列建立就好了。
以下是Deployment和Service的配置檔案:
deployment.yaml
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: heapster
namespace: kube-system
spec:
replicas: 1
template:
metadata:
labels:
task: monitoring
k8s-app: heapster
version: v6
spec:
containers:
- name: heapster
image: naughtytao/heapster-amd64:v1.5.0-beta.3
imagePullPolicy: Always
command:
- /heapster
- --source=kubernetes:https://kubernetes.default
- --sink=statsd:udp://ip:port?numMetricsPerMsg=1
service.yaml
apiVersion: v1
kind: Service
metadata:
labels:
task: monitoring
# For use as a Cluster add-on (https://github.com/kubernetes/kubernetes/tree/master/cluster/addons)
# If you are NOT using this as an addon, you should comment out this line.
kubernetes.io/cluster-service: 'true'
kubernetes.io/name: Heapster
name: heapster
namespace: kube-system
spec:
ports:
- port: 80
targetPort: 8082
selector:
k8s-app: heapster
註意這裡deployment的–sink的配置,ip是Splunk的IP或者主機名,port的對應的Splunk的data input的埠號。當使用udp協議的時候,需要配置的numMetricsPerMsg的值比較小,當這個值比較大的時候,會出message too long的error。當使用tcp的時候可以配置較大的數值。
執行 kubectl apply -f *.yaml 來部署heapster
如果正常執行,對應的heapster pod的日誌如下
I0117 18:10:56.054746 1 heapster.go:78] /heapster --source=kubernetes:https://kubernetes.default --sink=statsd:udp://ec2-34-203-25-154.compute-1.amazonaws.com:8124?numMetricsPerMsg=10
I0117 18:10:56.054776 1 heapster.go:79] Heapster version v1.5.0-beta.4
I0117 18:10:56.054963 1 configs.go:61] Using Kubernetes client with master "https://kubernetes.default" and version v1
I0117 18:10:56.054978 1 configs.go:62] Using kubelet port 10255
I0117 18:10:56.076200 1 driver.go:104] statsd metrics sink using configuration : {host:ec2-34-203-25-154.compute-1.amazonaws.com:8124 prefix: numMetricsPerMsg:10 protocolType:etsystatsd renameLabels:map[] allowedLabels:map[] customizeLabel:0x15fc8c0}
I0117 18:10:56.076248 1 driver.go:104] statsd metrics sink using configuration : {host:ec2-34-203-25-154.compute-1.amazonaws.com:8124 prefix: numMetricsPerMsg:10 protocolType:etsystatsd renameLabels:map[] allowedLabels:map[] customizeLabel:0x15fc8c0}
I0117 18:10:56.076272 1 heapster.go:202] Starting with StatsD Sink
I0117 18:10:56.076281 1 heapster.go:202] Starting with Metric Sink
I0117 18:10:56.090229 1 heapster.go:112] Starting heapster on port 8082
在Splunk中進行監控
好瞭如果一切正常的化,heapster會用statsd的協議和格式傳送metrics到Splunk的metrics store。
然後就可以用利用SPL的mstats和mcatalog命令來分析,監控metrics資料了。
以下搜尋陳述句列出所有的Metrics
| mcatalog values(metric_name)

以下搜尋陳述句列出整個cluster的CPU使用,我們可以用Area或者Line Chart來視覺化搜尋結果。
| mstats avg(_value) WHERE metric_name=cluster.cpu/usage_rate span=30m

kube-system namespace的對應記憶體使用情況
| mstats avg(_value) WHERE metric_name=namespace.kube-system.memory/usage span=30m
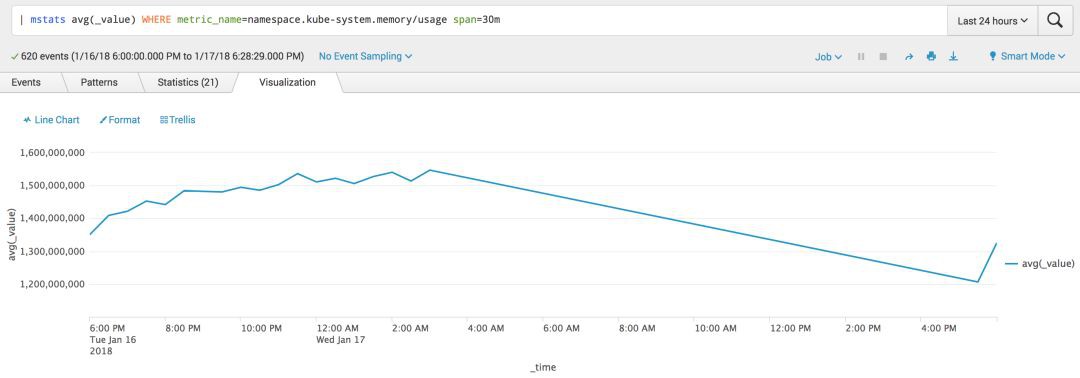
大家可以把自己感興趣的分析結果放在Dashboard中,利用Realtime設定進行監控。

好了,更多的分析選項可以參考Splunk檔案。
參考
-
https://github.com/DataDog/the-monitor/blob/master/kubernetes/how-to-collect-and-graph-kubernetes-metrics.md
-
https://kubernetes.io/docs/tasks/debug-application-cluster/resource-usage-monitoring/
-
https://kubernetes.io/docs/tasks/debug-application-cluster/core-metrics-pipeline/
-
https://itnext.io/kubernetes-monitoring-with-prometheus-in-15-minutes-8e54d1de2e13
-
http://docs.splunk.com/Documentation/Splunk/7.0.1/Metrics/GetStarted
作者:naughty
來源:https://my.oschina.net/taogang/blog/1608835
《Linux雲端計算及運維架構師高薪實戰班》2018年05月14日即將開課中,120天衝擊Linux運維年薪30萬,改變速約~~~~
*宣告:推送內容及圖片來源於網路,部分內容會有所改動,版權歸原作者所有,如來源資訊有誤或侵犯權益,請聯絡我們刪除或授權事宜。
– END –


更多Linux好文請點選【閱讀原文】哦
↓↓↓
