隨著流量的提升,團隊的壯大,為了適應變化,2017年扇貝的服務端進行了比較大的改造,全面擁抱了微服務,容器編排等。從而很大程度上提高了開發效率,降低了維護成本。微服務的服務間通訊與服務治理是微服務架構的實現層面的兩大核心問題。希望透過這次分享能夠給中小型的網際網路公司實踐微服務帶來啟發。
我們微服務從開始嘗試到現在大規模使用,算來也有快 2 年了。回過來看,踩了無數的坑,有的是技術的,有的是管理的。算是有不少心得了。今天主要想跟大家分享下微服務的選擇、DevOps 實踐、服務治理和 Service Mesh。

個人覺得選擇微服務要慎重,要考慮清楚微服務可能帶來的挑戰。一定要結合自己的實際,慎重地決定是否需要微服務化。
網上關於微服務好處的介紹有很多,這裡我想特別強調的是,從“人”的角度講,微服務帶來的優勢和挑戰。
微服務架構下,每個服務的複雜度大幅下降,從而維護成本也大幅降低。對於團隊來說,新人也可以更快地上手專案,貢獻程式碼。交接專案也變得更加容易。
單一服務架構下,隨著時間的推移,專案的複雜度必然越來越高,相關人員也會越來越多,從而程式碼的合併頻率會逐漸下降,許可權越來越難以分配,需要越來越重的測試,部署也越來越複雜,頻率越來越低。
然而微服務也會帶來很多問題,例如如果設計不合理,整體的複雜度會提高。寫程式碼的時候需要考慮呼叫失敗的情況,需要考慮分散式的事務(當然很多時候是設計不合理導致的),從而對人提出了更高的要求。
總之,微服務帶來了很多優勢,同時也帶來了很多挑戰,我們需要認真的審視自己,這些優勢對當下的我們是否是優勢,這些挑戰對當下的我們是否能hold住。
-
區分邊界服務和內部服務。所謂邊界服務就是會接受公網流量的服務,比如處理 HTTP 請求的服務,反之就是內部服務。邊界服務和內部服務在安全方面的考慮是不一樣的(例如邊界服務需要做針對User的鑒權等等)。
-
區分基礎和業務服務。業務服務追求變化,feature,基礎服務追求穩定,效能。
-
微服務的呼叫,一定要考慮呼叫會失敗。微服務的提供方,一定要考慮呼叫可能會有bug(比如死迴圈)。
-
沒有把握的做到合理拆分的時候可以選擇先不拆,等到發現瓶頸了自然就知道怎麼拆了。
微服務除了是個技術活,更是個管理活。一定得有和微服務相融的團隊組織方式和工作流程。
架構組要負責微服務的基礎設施的建設,例如 CI/CD 系統,Kubernetes 叢集, Service Mesh 叢集,監控報警系統,日誌收集系統,基礎工具和庫的構建維護。
總之架構組在團隊中的意義,可以理解為是為內部構建 PaaS。
業務團隊(無論是寫基礎業務的還是其他業務的)能從架構組那裡得到一個穩定可靠的 PaaS 以及一攬子配套工具。
其次每個微服務要有固定的團隊負責(實踐中,可以是對微服務分組,每組微服務對應一組特定的人)。
每個團隊負責自己的微服務的從開發到上線,到維護,到效能調優,到Debug。
在我們的實踐中,每個微服務團隊由2-3人組成,有一個master,負責 DevOps 流程的建設,許可權的分配等等一系列工作。
例如我們的 DevOps 是基於 GitLab CI 和 Kubernetes 的,所以master要負責 gitlab-ci.yml ,以及所有自己服務相關的 Kubernetes 的 deployment、job、service 等等的編寫維護。
此外專案線上執行的狀況也要自己負責,例如設計自己特異的監控指標,報警策略等等。這些反過來會指導自己的維護和調優。
不同的微服務團隊相互獨立,透過gRPC 和 Celery 實現資料交換。
從通訊型別的角度看,大概有三種型別:同步呼叫,非同步呼叫,廣播。
在微服務的設計之初要想清楚呼叫關係以及呼叫方式,哪些需要同步,哪些可以非同步,哪些需要廣播,最好團隊內部要有統一的認識。
對於如何選擇,我們需要從很多角度去思考。網上有大量的 “X vs Y”的文章或問答。其實無非就是從幾個角度:效能,成熟度,易用性,生態,技術團隊。我們的建議是:優先選擇社群活躍,以及和自己團隊技術棧相融的。社群活躍的技術往往代表了趨勢和生態,而團隊技術棧的相容性則是能否落地成功的保證。
比如當時扇貝選擇gRPC作為同步呼叫的介面協議。主要考慮的就是兩點:1. 社群活躍,發展非常迅速;2. 基於 HTTP/2,與我們的技術棧相容。
除了選擇協議,更加重要的應該就是介面檔案的管理了。最好介面檔案和程式碼是強相關的,就像 gRPC 的 proto 和生成出來的程式碼那樣。否則人往往是有惰性的,很有可能程式碼改了檔案沒改。
服務治理是個非常大的話題,真的要鋪開來講,分享的時間肯定講不完。
這裡我們想先簡單地看一下服務治理要解決的問題,以及現在的一些解決方案,發展趨勢。最後以扇貝為例,簡單介紹下在一個真實的百萬日活的生產環境中,服務治理是如何做的。
微服務化帶來了很多好處,例如:透過將複雜系統切分為若干個微服務來分解和降低複雜度,使得這些微服務易於被小型的開發團隊所理解和維護。然而也帶來了很多挑戰,例如:微服務的連線、服務註冊、服務發現、負載均衡、監控、AB測試,金絲雀釋出、限流、訪問控制,等等。
除了新星 Service Mesh,現在還有諸如 Spring Cloud 等方案。
這些方案的問題是:1. 對程式碼有侵入,也就意味著,如果想換框架,得改很多東西。2. 語言特異性(Java),如果我們用的是 Go/Python,或者我們的微服務不全是 Java,就搞不定了。
之後便是 Service Mesh 方案了,其實 DockOne 上關於 Service Mesh 的介紹太多了,我這裡不想浪費大家時間,就不贅述了,我就直接介紹下我們是怎麼用 Service Mesh 的。
扇貝的 Service Mesh 是基於 Envoy 配合 Kubernetes 實現的。
首先介紹一些前提:扇貝的微服務全部容器化,編排系統基於 Kubernetes,同步呼叫基於 gRPC,非同步基於 celery[rabbitmq]。開發語言以 Python 3、Node.js、Go 為主,Service Mesh 基於 Envoy。
總體的方案是:Envoy 以 DaemonSet 的形式部署到 kubernetes 的每個 Node 上,採用 Host 網路樣式。 所有的微服務的 Pod 都將 gRPC 的請求傳送到所在 Node 的 Envoy,由 Envoy 來做負載均衡。如下圖所示:
-
Envoy 中的 Route 類似於 Nginx 的 Location,Cluster 類似於 Nginx 的 upstream,Endpoint 對應於 Nginx 的 upstream 中的條目。
-
之所以選擇 Envoy 而沒有用 Linkerd,是因為當時 Envoy 是對 HTTP/2 支援最好的。且資源消耗更少。
-
之所以選擇 Host 網路樣式是為了最大化提高效能。
-
對於 Enovy 而言,服務發現就是告訴 Envoy,每個 Cluster 背後提供服務的實體的IP(對應於 Kubernetes 也就是 Pod 的IP)是什麼。
-
最開始服務發現是利用 Kubernetes 的 DNS,因此,在建立Service的時候,要使用 ClusterIP: None。
-
後來的服務發現是基於 Kubernetes 的 Endpoint API 實現了 Enovy 的 EDS(這個專案我們日後會開源到 GitHub 上)。
-
對於 Envoy 而言,實現熔斷,只要實現 rate limit service 就行了。我們基於Lyft/ratelimit 實現的 rate limit service。
-
微服務之間的呼叫情況都可以透過 Envoy 的 statistic API反映出來,所以我們針對 statistic API做服務呼叫的監控報警。
-
同理,呼叫日誌也可以利用 Envoy 的 Access Log 來實現。
-
之所以不用istio,是因為生產環境真不能用。效能問題,穩定問題太過突出。
我們的監控報警方案是基於 Prometheus 做的,分了三個級別:cluster級別,包括Node的狀況,叢集核心元件的狀況,等等。
-
叢集級別是架構組關心的, 基礎服務級別是所有人都要關心的,業務自定義級別就是微服務團隊關心的
-
基礎服務級別:包括 Service Mesh 的各種指標(例如請求量,請求時間等等),Redis、MySQL、RabbitMQ 等
-
業務自定義級別:包括各個微服務團隊自己設計的監控指標
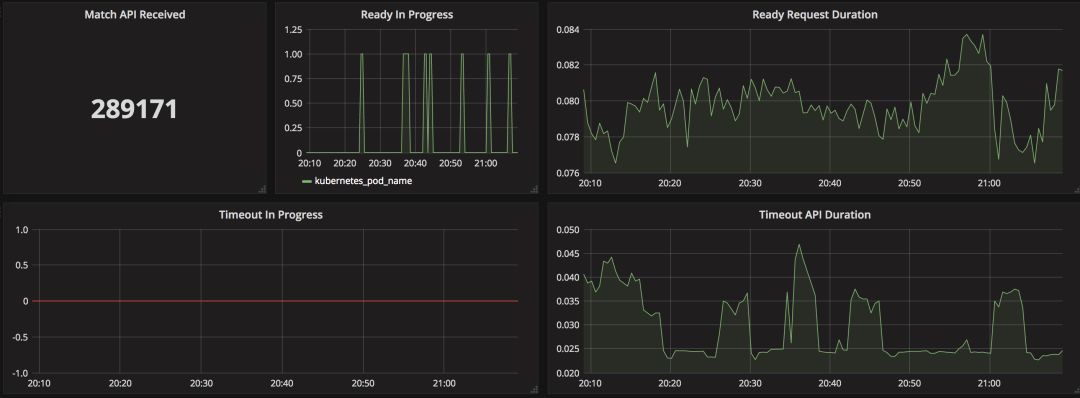
上面這個例子就是我們的“單詞大師”團隊自定義的監控指標,包括他們特有的 “Match API Received”(也就是對戰匹配API呼叫次數)等等。
至於日誌的話,基本還是沿用:Container -> stdout -> Filebeat -> Kafka -> Logstash -> ES(定期 archive)。所有容器的日誌都是直接打到stdout/stderr 的。
多說一句,我們的日誌系統出了方便給程式員Debug,同時還有承擔打點資料的收集的職責。所有的打點資料,也是透過日誌系統,在 Kafka -> Logstash 那一步分揀出來的。
例如上圖就是我們分揀的部分 gRPC 的呼叫日誌。
Q:Prometheus 只採集 Kubernetes 叢集的指標資料,那非 Kubernetes 的指標資料用什麼採集?
A:都是 Prometheus,應用是可以裝 Prometheus 的client,暴露自己的metrics的,然後 Redis 什麼的也都有exporter。
Q:請問下日誌如果都落到 stdout 的話,會不會造成格式不一致,從而導致收集和歸檔困難?比如說業務日誌和中介軟體日誌都打到 stdout,在 Filebeat 或者 Logstash 內是怎麼處理的?另外容器日誌定期刪除的策略是什麼?
A:這是個好問題,需要分揀的日誌會在 message 的開頭做特定的標記。例如 [DATABEAT] 表示打點資料。ES 有很多工具可以做定期 archive 的,策略比如保留多少天,多少月,根據不同的資料的策略不同。
Q:Envoy 對效能的損耗有多大,自身的效能消耗有多大?
A:Envoy 是有效能損耗的,因為 API 的平均響應時間差不多在 100-150 ms,同時相比其帶來的好處,我們認為這些損耗是值得的,所以我們具體並沒有測算。
Q:gRPC 做了服務註冊嗎,gRPC 新增減少欄位相容性如何處理的?
A:服務註冊/發現是基於 Kubernetes 和我們寫的 Kubernetes Endpoint 到 Envoy eds 的轉化服務做的。
A:Istio 包括一個控制面 + 資料面,Envoy 可以作為 Istio 的資料面的一個實現。
本次培訓內容包括:Docker基礎、容器技術、Docker映象、資料共享與持久化、Docker三駕馬車、Docker實踐、Kubernetes基礎、Pod基礎與進階、常用物件操作、服務發現、Helm、Kubernetes核心元件原理分析、Kubernetes服務質量保證、排程詳解與應用場景、網路、基於Kubernetes的CI/CD、基於Kubernetes的配置管理等,點選瞭解具體培訓內容。

長按二維碼向我轉賬
![]()
受蘋果公司新規定影響,微信 iOS 版的贊賞功能被關閉,可透過二維碼轉賬支援公眾號。