作者丨黃若孜
學校丨復旦大學軟體學院碩士生
研究方向丨推薦系統
前言
本文是關於 Wasserstein 距離在生成模型中的應用的一個總結,第一部分講 Wasserstein 距離的定義和性質,第二部分講利用 W1 距離對偶性提出的 WGAN ,第三部分包括 ICLR18 的兩篇文章,講不依賴對偶性,可以泛化到利用 W1 距離以外的 Wasserstein 距離來產生生成模型的 WAE,以及用 NN 來模擬 Wasserstein 距離的思想。
Wasserstein距離
衡量兩個分佈的距離常用的有兩種:Optimal Transport 以及 f-divergence(包括 kl 散度,js 散度等)。f-divergence 的定義如下,P 和 Q 是兩個不同的分佈,則:

其中 f(x) 可以是任何滿足 1. f is convex 2. f(1) = 0 的函式。可以證明,當 P 和 Q 完全相同,也就是說取任意的 x,都有 p(x) = q(x),Df(P||Q)=0。當 P 和 Q 有差異時,由於 f 是 convex 的:
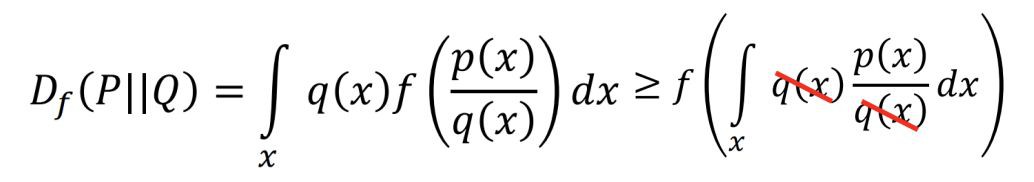
後者等於 0,所以 0 是 f-divergence 的最小值。當 f 取 xlogx 時,得到了 kl 散度。
而 OT 比 f-divergence 的拓撲更弱,在生成模型中這一點非常重要,因為資料的支撐集往往是輸入空間中低維流形 [1],所以真實分佈和生成分佈很可能沒有重疊,導致 f-divergence 這種捕捉分佈的機率密度比的距離會失效(p 和 q 的比值在同一個 x 點計算,而不在意 p(x1)/p(x2) 的大小),從而提供不了有用的資訊。
OT 距離也叫 Wasserstein 距離、Earth-Mover(推土機)距離。
1. 定義
Wasserstein 距離定義如下:
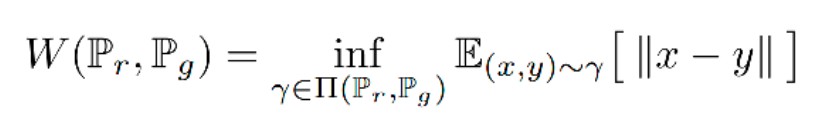
其中 ∏(Pr, Pg) 代表 Pr、Pg 所有可能的聯合機率分佈的集合。γ(x,y) 代表了在 Pr 中出現 x 同時在 Pg 中出現 y 的機率,γ 的邊緣分佈分別為 Pr 和 Pg。
在這個聯合分佈下可以求得所有 x 與 y 距離的期望,存在某個聯合分佈使這個期望最小,這個期望的下確界(infimum)就是 Pr、Pg 的 Wasserstein 距離。
直觀上看,如果兩個分佈是兩堆土,希望把其中的一堆土移成另一堆土的位置和形狀,有很多種可能的方案。

每一種方案可以對應於兩個分佈的一種聯合機率分佈,γ(x,y) 代表了在 Pr 中從 x 的位置移動 γ(x,y) 的土量到 Pg 中的 y 位置,對所有的 x 按 γ 移動,則可將分佈 Pr 轉化成 Pg。
推土代價被定義為移動土的量乘以土移動的距離,在所有的方案中,存在一種推土代價最小的方案,這個代價就稱為兩個分佈的 Wasserstein 距離。設定 Γ=γ(x,y),D=||x-y||,其中 ,則 em 距離可以重寫為:
,則 em 距離可以重寫為:

其中 F 為內積符號。

2. Kantorovich-Rubinstein Duality
當 D=||x-y|| 時,找 Wasserstein 距離的問題其實是一個線性規劃的問題。線性規劃問題是指線上性的約束條件下找一個線性標的函式的最最佳化解(極大解或者極小解)。包括三個部分:
-
一個需要極大化的線性函式
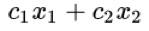
-
以下形式的問題約束:
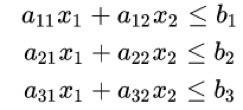
-
非負變數
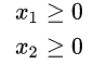
在本問題中,可以將 Γ 和 D 兩個矩陣展成一維:x = vec(Γ), c = vec(D)。找到 x 以最小化代價 ,其中
,其中 。同時 x 需要滿足約束條件 Ax = b,其中
。同時 x 需要滿足約束條件 Ax = b,其中 ,
, , x≥0。其中
, x≥0。其中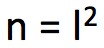 ,m = 2l。
,m = 2l。
為了得到這個約束條件,令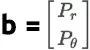 。A 則需要設定為 m*n 的矩陣,挑出 x 中適當位置的值得到兩個邊緣分佈。
。A 則需要設定為 m*n 的矩陣,挑出 x 中適當位置的值得到兩個邊緣分佈。
如果像本問題中,隨機變數只有一維,在這個維度上有有限個離散的狀態,可以直接用解線性規劃問題的方式來求解。然而在解實際問題中,比如學習圖片的分佈時,隨機變數有上千個維度,直接計算幾乎是不可能的。
但是由於我們需要的只是 z 的最小值,並且利用 z 求出生成分佈 Pθ ,而不一定需要求出 x(Γ)。所以我們可以對 z 進行關於 Pθ 的梯度下降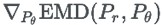 ,但是由於 Pθ 包含在最佳化的約束條件裡,所以無法直接進行梯度下降。
,但是由於 Pθ 包含在最佳化的約束條件裡,所以無法直接進行梯度下降。
由於線性規劃問題都有一個對偶問題,找到本問題的對偶形式為:

將新變數 y 作為未知變數,將最小化問題轉變成了最大化問題。經過轉化後,z* 的取值就直接取決於 b(包含 Pθ)。可以看到這個![]() 是 z 的下限(實際上可以證明
是 z 的下限(實際上可以證明![]() 的最大值無限接近於 z 的最小值):
的最大值無限接近於 z 的最小值):
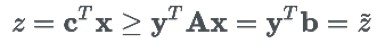
所以標的變成了找到 y*使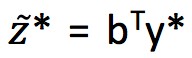 最大,
最大,![]() 即為兩個分佈的 Wasserstein距離,定義
即為兩個分佈的 Wasserstein距離,定義 ,則 Wasserstein 距離可以表達為如下形式:
,則 Wasserstein 距離可以表達為如下形式:

由於存在約束條件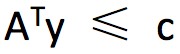 ,可以得到 f(xi) + g(xj) ≤ Dij。由於當 i = j 時,Dij =0,則 f(xi)≤-g(xj),因為兩個分佈一直非負,所以要最大化,就要最大化,這個求和式在 f = -g 時取到最大值 0。
,可以得到 f(xi) + g(xj) ≤ Dij。由於當 i = j 時,Dij =0,則 f(xi)≤-g(xj),因為兩個分佈一直非負,所以要最大化,就要最大化,這個求和式在 f = -g 時取到最大值 0。

f = -g 時可得到 f(xi) – f(xj) ≤ Dij 和 f(xi) – f(xj) ≥ -Dij,這表明 f 的傾斜程度要介於 1 和 -1 之間,這個約束稱為 lipschitz 連續性,對於連續分佈,這個性質仍然保持:
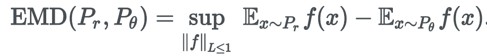
而實際上,以上結論成立的前提是 1-wasserstein distance,p-wasserstein distance 的定義如下:

d(x,y) 是![]() 上的任意距離,比如 L1 距離,歐氏距離。當 c(x,y) = d(x,y) 時,上述的 Kantorovich-Rubinstein duality 成立,而當
上的任意距離,比如 L1 距離,歐氏距離。當 c(x,y) = d(x,y) 時,上述的 Kantorovich-Rubinstein duality 成立,而當 時,f(xi) – f(xj) ≤ Dij 仍然成立,但是無法確定 f 的斜率的範圍。
時,f(xi) – f(xj) ≤ Dij 仍然成立,但是無法確定 f 的斜率的範圍。
WGAN
WGAN 的提出是為了剋服普通 GAN 出現的梯度消失的問題。Wasserstein 距離與 JS 散度,KL 散度的區別在於,這個距離在兩個分佈不重疊的時候也是連續的。
在二維空間中存在兩個分佈,P0 是在(0,1)上的均勻分佈,P1 是在(θ,1)上的均勻分佈,那麼根據定義可得:

可以看到當 θ 趨近於 0 時,在 Wasserstein 距離衡量下,P1 會趨近於 P0。而其他距離在兩個分佈不重疊的時候是常量,在兩個分佈重疊時有一個突變。所以在低維流形上學習機率分佈時,可以透過 EM 距離進行梯度下降,而不能透過 JS 距離,因為它作為 loss function 是不連續的。

WGAN 使用出了上節提到的代替公式:

L<1 代表 f 是一個 1-Lipsschitz 函式。K-Lipsschitz 函式定義為對於 K >0,||f(x1) – f(x2)||≤K||x1 – x2||。
在這裡 K=1,也就是說 f 的導數不能超過 1(如果 K 取 k 的話,求得的距離則是 k 倍的 EM 距離),限制了 f 不能改變得太快,在這個前提下,找到 f 使 最大,這個上確界(supremum)即為 Wasserstein 距離。f(x) 就可以用 nn 來擬合了,類似於普通 GAN 的判別器一樣。
最大,這個上確界(supremum)即為 Wasserstein 距離。f(x) 就可以用 nn 來擬合了,類似於普通 GAN 的判別器一樣。
要限制 f 是一個 k-Lipsschitz 函式,WGAN 給出的方案是做 weight clipping,即限制構成 f 的 NN 的引數 w 的範圍在 [-c,c] 之間,經過梯度下降更新後,一旦某個 w 超過了這個範圍,則把 w 修剪為 -c 或 c。
這樣因為 w 的範圍固定,那麼隨著輸入的改變,輸出的改變一定在一個有限的範圍內,存在 k 使 f 滿足 K-Lipsschitz。
WGAN 的演演算法如下,與普通 GAN 對比,判別器和生成器的 loss function 都去掉了 log,判別器的最後一層去掉了 sigmoid(因為不用限制 D 的輸出是 0~1),以及為判別器網路增加了 clip。

使用 WGAN 訓練出來的最優判別器沒有梯度消失的問題,下圖是兩個正態分佈,可以看到 GAN 的最優判別器得到了一個 sigmoid function,完全區分開了兩種分佈的樣本。
基於本章開頭的理論分析,梯度消失已經發生了,從圖上也可以直觀的看到,D(x) 在取樣處的梯度為常數,沒有有效的梯度資訊傳給生成器;而 WGAN 限制了判別器不能太陡峭,找到了一條接近直線的線,梯度是線性的。

WAE以及用NN學習Wasserstein距離的方法
問題
目前的一些生成模型可以看做是用不同的方法去最小化 Px 和 Pg 的某個距離,當 Px 未知,Pg 來自神經網路時,大部分的距離是無法直接計算的。
VAE 透過最小化兩個分佈的 KL 散度,或者等價於最大化,透過最小化變分下限得到了一個可行的理論框架,GAN 則是利用分佈的 JS 散度,當判別器達到最優時便能得到兩個分佈 js 散度。
再泛化一點,使用 f-GAN 可以最小化兩個分佈的 f 散度。OT 距離則是另一個選擇,由於 Kantorovich-Rubinstein 對偶性,可以將 OT 距離作為對抗訓練的標的用在 WGAN。
從效果上說,VAE 和 GAN 各自有其缺點,VAE 模型在理論上非常優美,而在應用的時候往往會產生模糊的圖片。
而 GAN 生成的效果往往令人驚艷,但是由於它缺少 encoder 結構,直接從一個不包含影象資訊的高斯分佈去生成影象,難以訓練而且經常出現 mode collapse。
儘管有很多工作去組合 VAE,GAN,但是仍沒有一個集 GAN 和 VAE 的優勢的統一框架。
Method
WAE 這個工作則是建立了 Pg 的隱變數模型,首先從隱空間一個固定的分佈 Pz 中得到 Z 的取樣,然後 Z 對映到一個影象 X,則 X 的分佈可表示為:

其中生成模型對映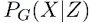 (也就是 decoder),可以是一個確定性的對映,對於固定的 G,將 Z 對映到 X = G(Z);也可以是加入了隨機性的 decoder。
(也就是 decoder),可以是一個確定性的對映,對於固定的 G,將 Z 對映到 X = G(Z);也可以是加入了隨機性的 decoder。
這樣就可以將 OT 距離的從找在同一個空間的兩個隨機變數(分別服從 Px 和 Pg)的某個聯合分佈轉變成了,對 Px 找一個條件分佈(也就是 encoder),使邊緣機率與先驗機率 Pz 相同。
定理:對於任何對映 G:Z→X,都存在:

定理 1 的證明如下:
有三個隨機變數,X 是真實影象,Y 是生成的影象,Z 是隱變數。在最優傳輸問題中,Γ(X,Y) 是聯合機率分佈的集合,由於 γ(X,Y) 對 X 求邊緣機率是 Px(X),所以 Γ(X,Y)=Γ(Y|X) Px(X),Γ(Y|X) 是一個從X到Y的非確定性的對映。
定理本質就是透過 Z 分解了這個對映,將它分解為 encoding 分佈 Q(Z|X) 和 generating 分佈 。
。
將 (Y,Z) 的聯合分佈記:

則:
 :(X,Y,Z) 聯合分佈的集合,滿足:
:(X,Y,Z) 聯合分佈的集合,滿足:

 :
:![]() 在 (X,Y) 上的邊緣機率分佈的集合
在 (X,Y) 上的邊緣機率分佈的集合
 :
:![]() 在 (X,Z) 上的邊緣機率分佈的集合
在 (X,Z) 上的邊緣機率分佈的集合
 :
: 的邊緣機率分佈的集合
的邊緣機率分佈的集合
根據以上定義可得到 (由於對於
(由於對於![]() 中任意一個 X 和 Y 的聯合分佈,也一定屬於,因為後者完全沒有約束),那麼就可以找到 Wasserstein 距離的上界:
中任意一個 X 和 Y 的聯合分佈,也一定屬於,因為後者完全沒有約束),那麼就可以找到 Wasserstein 距離的上界:

引理 2:,當 對於所有的 z 是 Dirac 函式時,
對於所有的 z 是 Dirac 函式時, 。
。
如果這個引理成立的話:
1. 那麼 Z → Y 使用確定性的對映,就可以找到準確的 Wasserstein 距離:
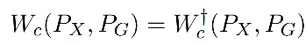

這樣就從找 X,Y 的聯合機率分佈轉變成了找 X,Z 的聯合機率分佈,而 Z 的邊緣分佈是固定的,P(X,Z) = P(X)P(Z|X),那麼目的則變為了找到條件分佈 P(Z|X)。
2. 當 Z → Y 這個 decoder 是非確定性的,根據引理 2 我們得到的是 Wasserstein 距離的上限。
推論 3:假設條件分佈 PG(Y|Z=z) 對每個 z 有均值 G(z),和方差 ,其中 G:Z→X。取
,其中 G:Z→X。取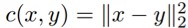 ,則:
,則:
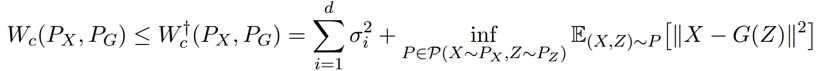
證明:已知
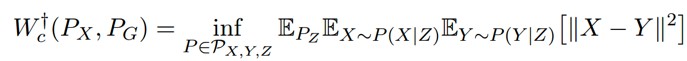
註意到:

其中第二項,Y~P(Y|Z) 中,則 Y 與這個 Y 均值 G(Z) 的差異對 P(Y|Z) 計算期望,肯定為 0,第三項則剛好是 Y 的方差。所以用這種方法計算出來的距離比 Wasserstein 距離多一個方差。
根據定理 1,解這個問題是在 encoder Q(Z|X) 上做最佳化,而不是在 X 和 Y 的聯合分佈上。在實踐中,為了找到數值解,WAE 放寬了對 Qz 的約束,訓練標的為:
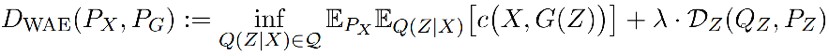
其中 encoder Q 和 decoder D 都用神經網路實現,而不同 VAE,WAE 可以使用確定性的 encoder,因為不需要為每一個資料 x 在 latent space 得到一個分佈,只要 Z 的邊緣分佈和先驗接近即可。
 可以是一個任意的 divergence,本文嘗試了兩種懲罰:基於 GAN 和基於 MMD。基於 GAN 即是選擇了 JS 散度來衡量分佈之間的距離
可以是一個任意的 divergence,本文嘗試了兩種懲罰:基於 GAN 和基於 MMD。基於 GAN 即是選擇了 JS 散度來衡量分佈之間的距離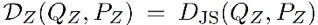 。
。

相關工作
VAE:
VAE 和 WAE 都是最小化兩項:重建誤差、正則化項,其中第二項是透過懲罰 Pz 和透過 encoder 得到的潛在變數 z 的分佈 Q 之間的距離得到的。
VAE 對所有的樣本 x 強迫 Q(Z|X=x) 匹配先驗 Pz,如下圖 a 所示,每一個紅色的圓都被迫去匹配而中間白色的圓形,這樣會導致紅色的圓距離越來越近,相互交叉。
而 WAE 是強迫生成的潛在變數 z 在 Px 分佈下的期望 匹配先驗 Pz,如下圖 b 所示的綠色的圓。這樣的結果是可以不同的樣本可以和其他樣本保持距離。
匹配先驗 Pz,如下圖 b 所示的綠色的圓。這樣的結果是可以不同的樣本可以和其他樣本保持距離。
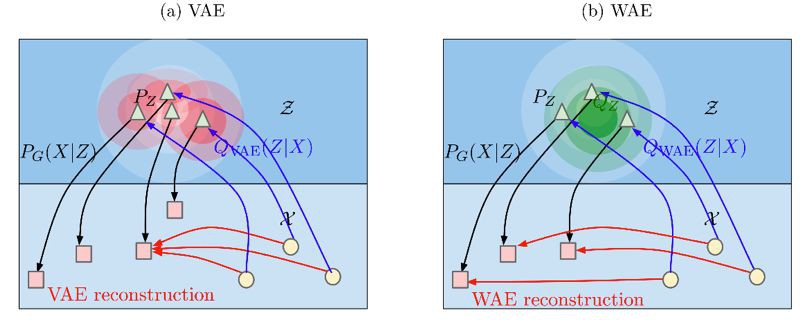
WAE 的 decoder 的任務是精確的重構出訓練樣本,encoder 的任務除了上文描述的最小化生成的潛在變數和其先驗分佈的距離之外,還要保證潛在變數裡面維持了訓練樣本中充足的資訊以重建。
此外,WAE 可以使用確定性的 encoder,因為不需要為每一個資料 x 在 latent space 得到一個分佈;VAE 只能使用高斯 encoder。
當使用 時,WAE-GAN 等同於 AAE。WAE 可以看做 AAE 的泛化:1. 在輸入空間可以使用任意的代價函式,2. 在隱空間可以使用任意度量差異的方法,比如 MMD。
時,WAE-GAN 等同於 AAE。WAE 可以看做 AAE 的泛化:1. 在輸入空間可以使用任意的代價函式,2. 在隱空間可以使用任意度量差異的方法,比如 MMD。
WGAN:
WGAN 最小化 1-Wasserstein distance,而不能對其他的代價 Wc 最佳化;同時 WGAN 不具有 encoder 結構,容易出現 model missing 的問題。
同樣在今年 ICLR 發表的 Deep Wasserstein Embedding,想用一種比較簡單粗暴的方式直接學習 Wasserstein 距離。DWE 適用於分佈已知,並且可以計算 Wasserstein 距離的情況,學習的目的是節省計算 Wasserstein 距離的時間。
DWE 就是想要用有監督的方法學習一個 embedding 的表示(同時在這個 embedding 層可以方便的進行距離計算)。需要一些預先計算好的資料集包括成對的多個直方圖 和每對直方圖對應的 Wasserstein 距離
和每對直方圖對應的 Wasserstein 距離 。
。
如果想要使用 NN 直接得到兩個分佈的 Wasserstein 距離,一種直觀的方法是將 x1 和 x2 作為輸入,將距離 y 作為輸出,然而這樣得到的 y 不具有良好的可解釋性,同時會產生不對稱的距離。
另一種方法則是直接對 x1 和 x2 用同一個網路進行(對稱的)encode,得到含有分佈資訊的 embedding 結果,併在這個新的空間中模仿 Wasserstein 距離學習一個歐式距離(contrastive loss)。
本文想要學習一個 embedding 網路 Φ,輸入是一個直方圖(即分佈),將其對映到一個給定的歐幾裡得空間,並且希望 embedding 後能夠保持 Wasserstein 空間的幾何性質。
同時將 embedding 後的結果輸入到 decoder 網路,計算一個重建損失,這樣的做可以迫使 embedding 網路學到更多的資訊來產生一個好的重建結果,使 embedding 的學習變得更簡單。

DWE 方法如圖所示,從一個資料分佈中得到兩個取樣,分別作為 encoder Φ 的輸入,然後透過在 embedding 層使歐氏距離的平方模仿 Wasserstein 距離,用另一個 decoder 網路 Ψ 重構輸入的圖片,用 KL 散度計算重建誤差(選擇 KL 散度是因為 x 分佈)。訓練的標的函式為:

註意,該方法對資料集的利用不同於 WAE,如果將隨機變數 X(如圖片)展成長度為 d 的 vector,WAE 要學習一個 d 維隨機變數的分佈 P(X)(也是一般的生成模型要學習的標的)。
而 DWE 則是將這個 vector 作為了一個離散分佈,有 d 個取值的直方圖,對每一個通道 n,計算一次 Wasserstein 距離。比如對於 mnist 的圖片,由於是灰度圖,每一個灰度值可以當做機率分佈,進行 softmax 後即可歸一。
參考文獻
[1]. Arjovsky M, Bottou L. Towards principled methods for training generative adversarial networks[J]. arXiv preprint arXiv:1701.04862, 2017.
[2]. https://vincentherrmann.github.io/blog/wasserstein
[3]. https://www.youtube.com/watch?v=KSN4QYgAtao&t;=1448s
[4]. Tolstikhin I, Bousquet O, Gelly S, et al. Wasserstein Auto-Encoders[J]. arXiv preprint arXiv:1711.01558, 2017.
[5]. Courty N, Flamary R, Ducoffe M. Learning Wasserstein Embeddings[J]. arXiv preprint arXiv:1710.07457, 2017.
[6]. Arjovsky M, Chintala S, Bottou L. Wasserstein gan[J]. arXiv preprint arXiv:1701.07875, 2017.

 #作 者 招 募#
#作 者 招 募#
我是彩蛋
解鎖新功能:熱門職位推薦!
PaperWeekly小程式升級啦
今日arXiv√猜你喜歡√熱門職位√
找全職找實習都不是問題
解鎖方式
1. 識別下方二維碼開啟小程式
2. 用PaperWeekly社群賬號進行登陸
3. 登陸後即可解鎖所有功能
職位釋出
請新增小助手微信(pwbot02)進行諮詢
長按識別二維碼,使用小程式
賬號註冊 paperweek.ly
paperweek.ly

關於PaperWeekly
PaperWeekly 是一個推薦、解讀、討論、報道人工智慧前沿論文成果的學術平臺。如果你研究或從事 AI 領域,歡迎在公眾號後臺點選「交流群」,小助手將把你帶入 PaperWeekly 的交流群裡。

▽ 點選 | 閱讀原文 | 加入社群刷論文